Table of Contents
“We all get our credit cards replaced a lot. Our online ecosystem is getting more complex with the number of accounts we have. We wanted to simplify that, and make it less complicated to get those cards back on file,” says Katherine Chavez, Director of Marketing for Strivve (formerly Switch, Inc.).
Strivve is a startup that aims to take the pain out of updating credit and debit cards by automating the updating process. This was the need driving Strivve to build a platform that helps issuers get their cards into use immediately, to update online payment profiles, and activate new or replacement cards on cardholders’ behalf.
The task of managing cards to site relationships, however, is complex. To build their credit card updater, Strivve needed anonymized site navigation for machine learning to enable using remote process automation (RPA). Strivve chose InfluxDB Cloud, the hosted version of InfluxDB, as their platform’s time series database. Here’s how they built their platform.
Credit card updater solving card issuer and cardholder needs
Strivve sought to solve both card issuer and cardholder needs.
- Cardholders have to replace their card on every single site if they get a new card a painstaking, time-consuming process.
- Card issuers and merchants lose significant revenue when reissuing events (such as fraud) occur and replacement cards are active but not used. A card issuer's goal is not to know what sites their cardholders are using but to get their card on those sites.
With the growing number of cards in every wallet, online merchants are storing on file. Besides the need to store credit card information, Strivve needed to store login credentials on all sites used by each cardholder.
The path of machine learning and remote process automation
Early on in their journey, Strivve attempted to gather as much data as possible but soon realized that classic mining techniques were not the right approach. They narrowed down their massive data volume to only data of interest:
- Anonymized site navigation for machine learning so that they can help their users through their remote process automation (RPA).
- Anonymized RPA interaction error data for troubleshooting whereby the service provider gets errors snapshotted to help resolve them.
Strivve first chose Elasticsearch, put a Logstash server up into Linux, and created an EC2 instance on AWS. However, they learned that it was difficult to get the machine learning and troubleshooting artifacts out of Logstash; that Logstash wouldn’t scale for their needs; and that it didn’t fit their strategic model of leveraging non-intellectual property hosted/cloud services.
As a small team, Strivve had to be creative and efficient in gathering data and extracting value from it. They decided to invest their energy into machine learning and remote process automation. This put an end to using Elasticsearch and set them on a search for an alternative.
Managed time series database for Strivve's credit card updater
“We saw some of the other folks using InfluxDB, and some of the scale points they were using it at. Could we generate a big enough load to bother InfluxDB? It was far beyond what we were doing with Logstash at that time,” says Gary Tomlinson, Strivve’s Director of R&D, “We knew it would work for what we were doing.”
Strivve chose InfluxDB because it is:
- Purpose-built for time series data
- Scalable
- Tag system based
- Available in a cloud version (InfluxDB Cloud)
- Widely adopted by the community
Strivve modified their machine learning system to ingest time-based site navigation events stored in InfluxDB. Since InfluxDB is time-based, it was easy to use InfluxQL to query the data on time for analysis in their machine learning system. This allowed them to structure their data nicely so when problems arise, they are able to navigate the records to determine cause during any specified time period. The InfluxData platform is well-suited for machine learning because it can easily send time series data to an ML solution for training. The trained model can then be brought back into InfluxDB to provide real-time dashboarding and trigger the appropriate workflow.
Using best-in-class security protocols, Strivve’s platform CardUpdatr (formerly called TopWallet), also available in the form of an API called CardSavr, discovers where cards are used for payments, navigates to login pages, and adds new or updated payment cards on behalf of each user. This unique functionality is enabled by streaming anonymized crowdsourced site artifacts into InfluxDB for learning, analysis and support.
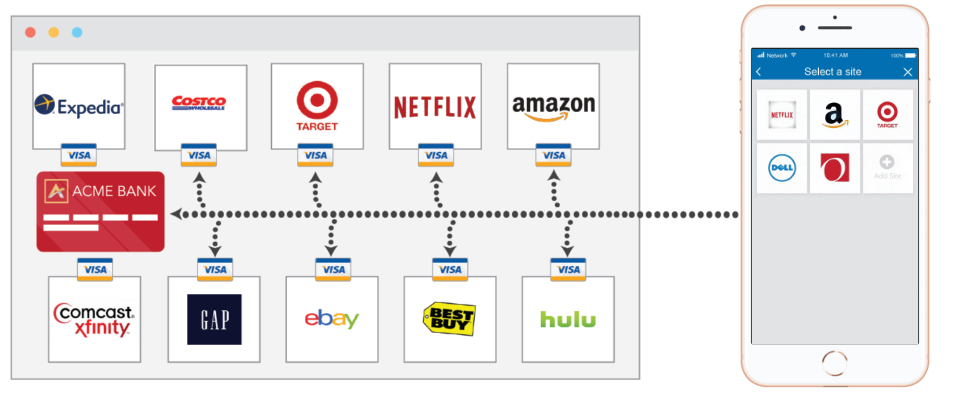 <figcaption> The Strivve Platform is easily integrated into any online environment.</figcaption>
<figcaption> The Strivve Platform is easily integrated into any online environment.</figcaption>
Platform architecture using InfluxDB Cloud and machine learning
Early on, Strivve realized that if they anonymize their data, they could crowdsource site artifacts and learn about visited sites that they have commercial relationships with. The Remote Process Automation, which runs in the virtual or real browser, interfaces with merchant sites on behalf of an end user. So they can log in, impersonate users, navigate forms, update billing information and card information, and replace a card.
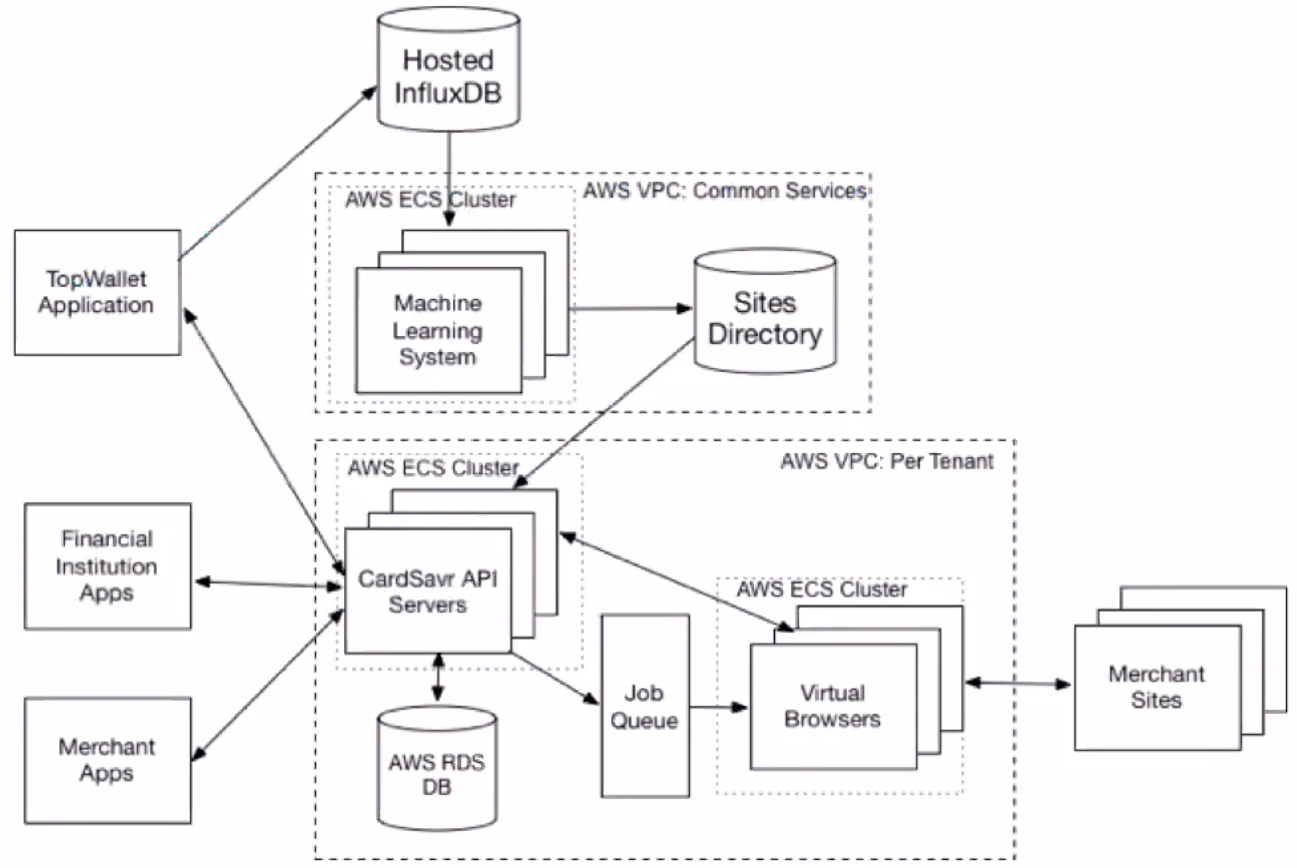 <figcaption> Service architecture of Strivve’s platform</figcaption>
<figcaption> Service architecture of Strivve’s platform</figcaption>
Strivve leverages machine learning to automate common tasks across tens of thousands of the most popular websites. They modified their machine learning system to ingest site navigation events. InfluxDB Cloud, being time-series-based, made that ingestion easy to set up and implement.
Strivve’s automation technology allows issuers to capture lost revenue of newly issued cards while enhancing cardholder convenience and security. By choosing InfluxDB Cloud, Strivve successfully built their groundbreaking credit card updater service. Learn more about this machine learning use case deploying InfluxDB Cloud.

