How to Consolidate OSS Data into a Cloud Account
By
Rick Spencer
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
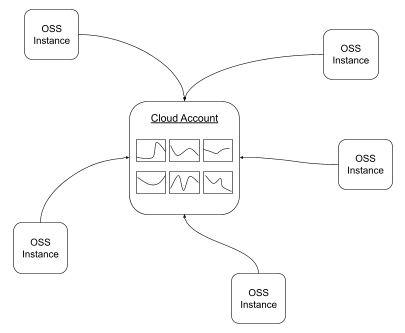
In this post, we will describe a simple way to share data from multiple InfluxDB 2.0 OSS instances with a central cloud account. This is something that community members have asked for when they have OSS running at different locations, but then they want to be able to visualize some of the data or even alert on the data in a central place.
Please note that while the method presented here is simple and fast to set up, it has many limitations which may make it inappropriate for your product use case. This will be discussed at the end of the post.
This method uses a combination of features available in InfluxDB today; namely, tasks, line protocol, and the Flux http.post() method.
An InfluxDB IoT scenario
To demonstrate this functionality I created a pretend manufacturing plant where I am running an InfluxDB 2.0 OSS instance. I call this “Plant 001.” This site has two different kinds of sensors throughout the plant. These are differentiated with the tag “s_type”, and each sensor is either s_type=1 or s_type=2. The plant has 50 of each of these sensors, which report in every 5 seconds. The sensors each have a type code of either 1 or 2.
Here is some example line protocol for the sensor data:
sensors,s_type=1,s_id=s18 s_reading=40
sensors,s_type=2,s_id=s28 s_reading=91
sensors,s_type=1,s_id=s19 s_reading=36
sensors,s_type=2,s_id=s29 s_reading=99
sensors,s_type=1,s_id=s110 s_reading=33
sensors,s_type=2,s_id=s210 s_reading=71
sensors,s_type=1,s_id=s111 s_reading=37
sensors,s_type=2,s_id=s211 s_reading=67
sensors,s_type=1,s_id=s112 s_reading=45
sensors,s_type=2,s_id=s212 s_reading=75
sensors,s_type=1,s_id=s113 s_reading=31
sensors,s_type=2,s_id=s213 s_reading=61The users in Plant 001 can view the status of these sensors within their network, typically with the following dashboard.
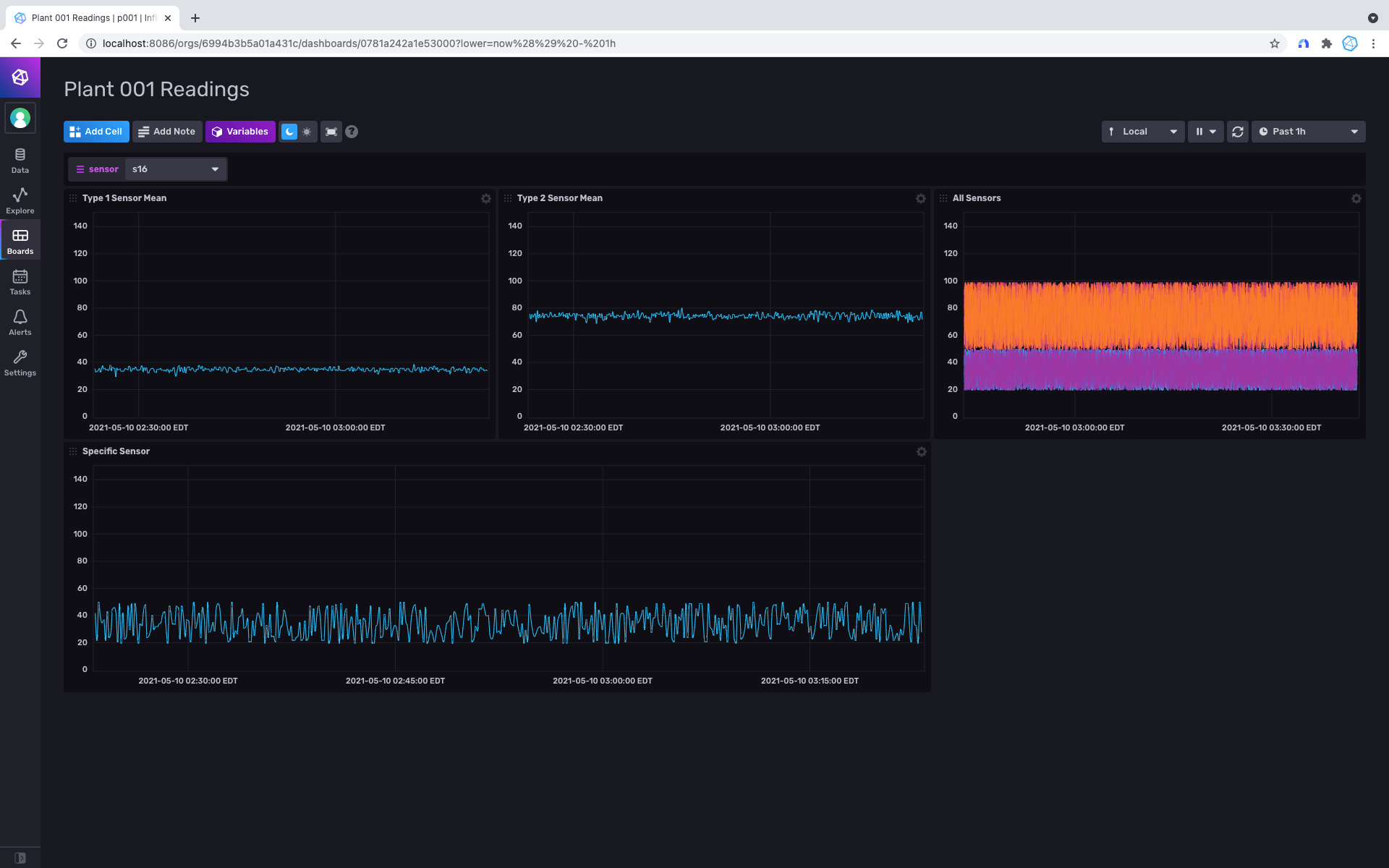
Your InfluxDB Cloud account
But what if I am going to have many plants running in the same way? What if I want to be able to help monitor the plant, but the OSS instance is not running in an accessible place? To solve this, first, you will need an InfluxDB Cloud account.
A free tier account will work just fine for this. You can easily sign up for an account here.
Therefore, you can go ahead and create a bucket. Because you will be passing the bucket name as part of a url, I suggest not including any special characters in the bucket name to avoid issues with url encoding. For my example, I chose to name the bucket simply “remote.”
After creating your bucket, go ahead and create a write token for the bucket. Your cloud account is now set up to start collecting data from your OSS instance.
Create the task in your InfluxDB OSS instance
First thing you want to do is to store the write token for your cloud account bucket as a secret in your OSS instance. There is no UI for this, but it is simple enough to do with the CLI. Assuming that the influx CLI is configured to point to your OSS instance, you can use a command like this:
$ influx secret update -k remote-token -v LN1lYeE3j0we0dji_E027UyOUrmi1vLJK2xz-N3z8cDzxqiqDjTdV3xrUAjsBLQ6AbNZf67Nxsu3pvBtg3tsrg==
Key Organization ID
remote-token 6994b3b5a01a431cNow we are ready to write from our OSS instance. To do this, we just need to:
- Pull in the secret from the secrets store.
- Create the url string for the API.
- Select and aggregate the data you want to send.
- Call http.post() for each row using map() to send line protocol to your InfluxDB Cloud account.
import "http"
import "influxdata/influxdb/secrets"
token = "Token ${secrets.get(key: "remote-token")}"
url = "https://us-west-2-1.aws.cloud2.influxdata.com/api/v2/write?orgID=27b1f32678fe4738&bucket=remote"
from(bucket: "readings")
|> range(start: -5m)
|> filter(fn: (r) =>
(r["_measurement"] == "sensors"))
|> mean()
|> map(fn: (r) =>
({r with http_code: http.post(url: url, headers: {"Authorization": token}, data: bytes(v: "sensors,plant=p001,s_id=${r.s_id} m_reading=${string(v: r._value)}"))}))Now that the data is flowing in, I can go ahead and make a dashboard in my InfluxDB Cloud account so that I can keep an eye on the remote instances.

Of course, I can go ahead and repeat this process for more remote instances and thereby create a consolidated view.
Limitations
While this method has the advantage of being easy to set up and not requiring any additional software or integrations to make it work, it has some limitations that may make it inappropriate for your production setup.
Very small amounts of data
This method is only able to send a single line of line protocol at a time over the API. In my example, that means that every five minutes, it makes 100 separate calls to the write endpoint to write the data to the cloud account. For a meaningful number of points, this will become gothically slow. There is no batching or any other optimizations. As you can imagine, that means for this to work, the data must be aggressively downsampled.
Retry Logic
A write call can always fail for many reasons, such as the network in which the OSS instance is running becomes disconnected from the internet, etc In this example, those failed writes are simply ignored. While there would be some techniques you could try to overcome this lack of resiliency, most likely if this level of availability is a concern, you will likely want to explore other options for such integration.
Next steps
As mentioned above, this technique is simple but has some significant limitations. I may follow up with more details about addressing some of these limitations.
Checks and notifications
The example presented here shows how to visualize data from a remote OSS instance, but it is more likely that you will be interested in alerting based on data collected in those remote instances. This is possible by creating a check in your task that writes to your cloud account’s _monitoring bucket.
Telegraf
Telegraf has many desirable features built in that can improve the resiliency of this system. By configuring a Telegraf instance that proxies your cloud account, you can improve the resiliency of this setup without significant code changes.
