Table of Contents
At InfluxData, we believe it makes sense to use a time series database for security monitoring. In summary, it’s because security investigations are inevitably time-oriented – you want to monitor and alert on who accessed what, from where, at which time – and time series databases like InfluxDB are very efficient at querying the data necessary to do this.
In this post, we’d like to show you the beginnings of how we’re using InfluxDB for security monitoring so that you can apply these patterns to your own organization.
Our inventory of security events at InfluxData
The first question: where to begin our security event monitoring? Since most security breaches are related to compromised accounts, we decided to focus there.
In order to verify geographically appropriate access to our services, we need to collect data for over 100 cloud services. But one of the first hurdles we hit was the availability of access data (who’s logged in) and activity data (what they did once logged in). Of those 100+ services, a few dozen use single-sign on (SSO) using Google Workspace (formerly called G Suite). Since we were able to acquire access data for those services, we decided to start there.

Patterns we're looking for
Security monitoring is all about anomaly detection – what the deviations from normal are. We decided to look at the following:
- Total number of unique accounts
- Total number of authentication attempts
- Total number of successful authentication attempts
- Total number of unsuccessful auth attempts
- Average number of IP addresses per account
- Average number of accounts per IP address
- List of authentication events, with time, username, app, IP address, and whether successful or not
With the event data stored in InfluxDB, it’s easy to view the above information across any time period we like, such as the past hour, day, week, month, etc.; a particular set of hours or days; certain hours of the day (business hours vs. non working hours); or certain days of the week (weekdays versus weekends).
We want to keep the data points required simple. After all, we have many services to track. Our list of cloud services used – and thus attack surface – is continually changing. And usage patterns change over time, whether it’s the holiday slowdown, or the return to a post-pandemic world with more travel.
Authentication events
We are collecting authentication events from the Google Workspace (GWs) audit logging services, Login audit log. The GCP Cloud Logging documentation describes methods for automated collections. Later, we’ll shift to collecting these events using the Telegraf PubSub plugin, since it’s an easier, cleaner integration. (Please learn from my mistakes!)
Data collection
Each service can require a separate collection process. The methods and data models can be similar though each will be unique. This will be accomplished in many ways and with a variety of tools. (Details are beyond our scope today.) The collection service for Google Workspace currently runs a NodeJS polling program every 5 minutes. Again, this is migrating to a simpler PubSub Telegraf listener.
Data storage
The metrics storage is the InfluxDB Cloud service.
Data model
Each service will deliver the data in a different pattern than other services, and we will need to normalize each for our uses.
The basic information we will require:
- Authentication timestamp
- Company account ID
- Username
- User ID
- User domain
- Authentication type
- Authentication result
The company ID is used to manage separate corporate accounts. The username is usually the email address but could match the user ID.
Our keys are mapped to static values or GWs event fields.
GWs == Google Workspace Event Record
- time: GWs.id.time
- service_source: "G Suite"
- service_domain: "influxdata.com"
- source_address: GWs.ipAddress
- email_address: GWs.actor.email
- saas_account_id: GWs.actor.profileId
- customer_id: GWs.id.customerId
- application: GWs.id.applicationName
- auth_results: GWs.events[X].name
- login_type: GWs.events[X].parameters[Y].value
Visualization
This initial dashboard visualization consists of general usage metrics, success vs. failure counts, account and address cardinality, results over time chart, and a list of authentication event details. Creating visualizations and dashboards is covered very well in the InfluxDB documentation.
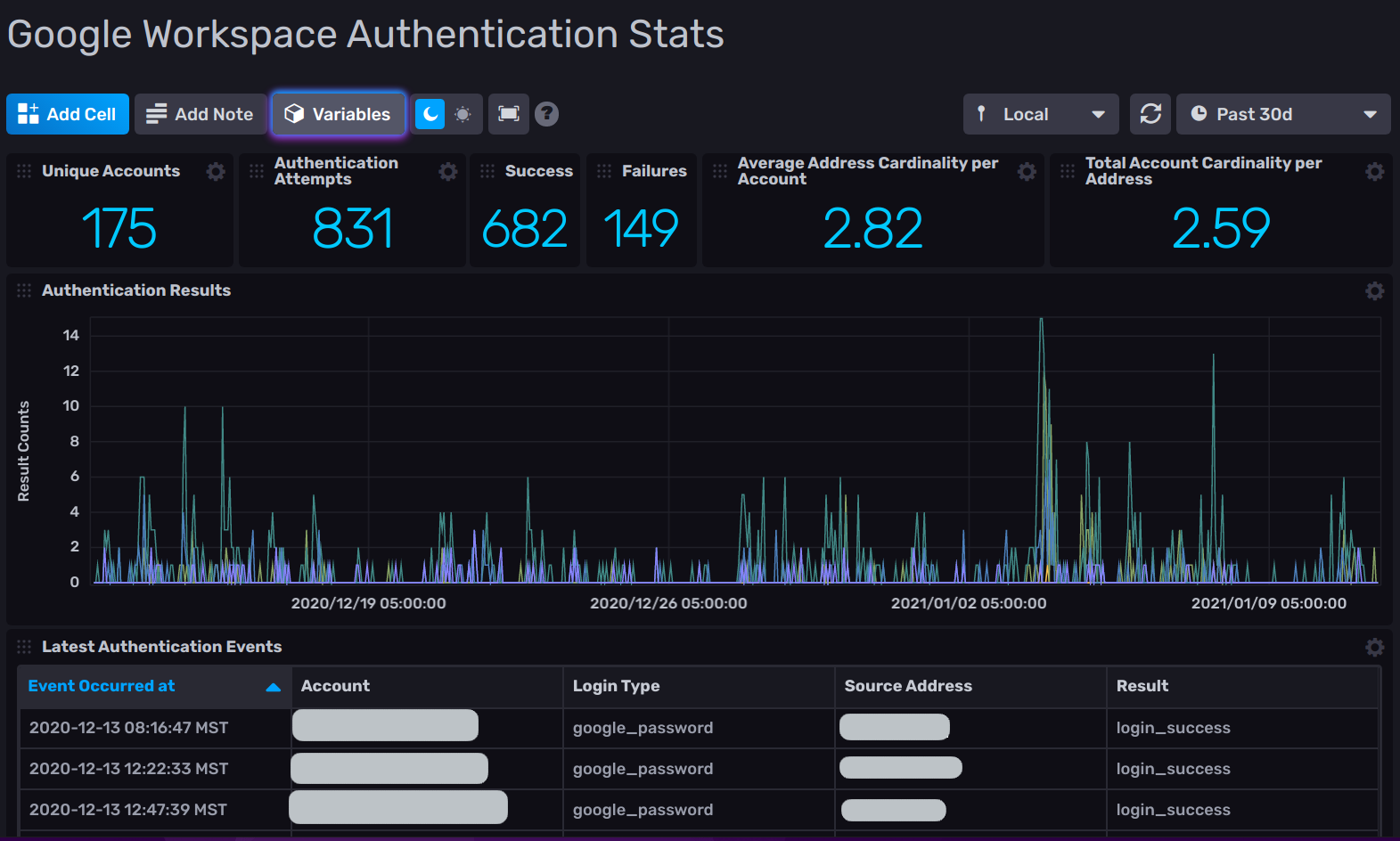
Dashboard elements
Flux queries used for each cell of the above dashboard are as follows:
Unique accounts
This builds the list of unique accounts attempting authentication for the given period of time.
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "auth_activity"
and r._field == "auth_result"
)
|> keep(columns:["email_address"])
|> group()
|> unique(column: "email_address")
|> count(column: "email_address")Authentication attempts
How many total authentications were attempted during our request period.
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "auth_activity"
and r._field == "auth_result"
and (r._value == "login_success" or r._value == "login_failure")
)
|> keep(columns:["_time","email_address"])
|> group()
|> count(column: "email_address")Success
For this time period, how many authentication attempts were successful.
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "auth_activity"
and r._value == "login_success"
)
|> group()
|> count()Failures
Demonstrates how many authentication attempts failed during this time.
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "auth_activity"
and r._value == "login_failure"
)
|> group()
|> count()Average address cardinality per account
For the given time period, what is the average number of internet addresses used for each user id.
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "auth_activity"
and r._field == "auth_result"
)
|> keep(columns:["email_address","source_address"])
|> group(columns: ["email_address"])
|> unique(column: "source_address")
|> count(column: "source_address")
|> group()
|> mean(column: "source_address")Total account cardinality per address
How many accounts were used per internet address during the same time period.
addresses = from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "auth_activity"
and r._field == "auth_result"
)
|> keep(columns:["source_address"])
|> map(fn: (r) => ({ r with field: "x1" }))
|> group(columns:["field"])
|> rename(columns: {source_address: "_value"})
|> unique()
|> count()
accounts = from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "auth_activity"
and r._field == "auth_result"
)
|> keep(columns:["email_address"])
|> map(fn: (r) => ({ r with field: "x1" }))
|> group(columns:["field"])
|> rename(columns: {email_address: "_value"})
|> unique()
|> count()
join(tables: { d1: addresses, d2: accounts }, on: ["field"])
|> map(fn: (r) => ({
r with _value: float(v: r._value_d1) / float(v: r._value_d2)
}))
|> keep(columns:["_value"])Authentication results
Summary of authentication attempt successes and failures that occurred during the entire time period.
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) =>
r._measurement == "auth_activity"
and (r._field == "auth_result")
)
|> keep(columns: ["_start","_stop","_time","_value"])
|> map(fn: (r) => ({ r with res: r._value }))
|> group(columns: ["res"])
|> aggregateWindow(every: v.windowPeriod, fn: count )Latest authentication events
A full list of the authentication events and details for the time period.
from(bucket: v.bucket)
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter( fn: (r) =>
r._measurement == "auth_activity"
and r._field == "auth_result"
)
|> duplicate(column: "_value", as: "auth_result")
|> drop(columns:[
"_start","_stop","_field","_measurement","application",
"customer_id", "service_source","saas_account_id","_value",
"service_domain"
])
|> group()
|> sort(columns:["_time"], desc: true)A request to our fellow cloud software vendors
Let me step onto my soapbox for a moment.
One thing we’ve noticed is that many cloud services and SaaS applications don’t provide access to security events such as logins. And for those that do, many charge extra for them. For example, here’s the pricing of AWS CloudTrail, which lets you log and monitor your AWS account activity.
As an industry, us cloud and SaaS vendors are doing ourselves a disservice, because these practices reduce the likelihood of our customers finding security breaches. The more we can make security events widely available via APIs – and make those APIs free – the more we can build trust in the products we all offer.

Think of the car industry – they don’t charge extra for fancier seatbelts, anti-lock brakes, or airbags. These come standard, because car vendors know that the safer they make cars, the more people will trust them as a mode of transportation. We need to start thinking like that.
So if you’re a cloud software developer, please make your security events, especially authentication events, available via a free API. Specifically, provide programmatic access, either via pull (REST API calls) or push (web sockets, MQTT, AMQP, etc.) of the following information:
- Access: Who (attempted) log in, at what time, and from where, in the form of IP address or fully-qualified domain name (FQDN). Even better: determine the latitude and longitude of a login. This way a customer can compute the distance between login sessions to see if they indicate an account compromise.
- Usage: How long someone's session lasted.
- Activity: This is domain-specific and should allow tracking of at least add, change, and delete operations in an application or cloud service.
InfluxDB OSS and Enterprise products produce detailed authorization and activity logs. This is available through AWS, Azure, and Google Cloud marketplaces to streamline the installation and purchasing.
Now, to be completely transparent, the information is only available for InfluxDB Cloud services with a request to the support team. The capabilities are on our product roadmap, and we are working to rectify this.
More on InfluxData and security
InfluxDB content on security:
- Monitoring Endpoint Security States with InfluxDB
- Fail2ban Monitoring with InfluxDB and Telegraf
- Automating SSL Certificate Expiration Monitoring
- InfluxDB OSS 2.0 Security and Authorization
- Manage InfluxDB security | InfluxDB OSS 1.8 Documentation
- Security at InfluxData
- Network Security Monitoring with Suricata and Telegraf | Blog
- Authentication and authorization in InfluxDB | InfluxDB OSS 1.8 Documentation
We have the following security monitoring templates:
Sending log data to InfluxDB:
- Send Syslog Data to InfluxDB and Telegraf Syslog input plugin
- Telegraf Docker Log plugin
- Telegraf Graylog input plugin
- Telegraf Logparser plugin
- Telegraf Logstash plugin
- Telegraf Tail plugin
- A buffered output plugin for fluentd and InfluxDB
Sending log data from InfluxDB:
Conclusion
As we migrate our operations and services from self-hosted to cloud, the security-related events are more difficult to collect and correlate yet become even more important to watch. Our tools and methods must evolve in order to keep up with a continually changing attack surface, and the InfluxData platform can be utilized well for this.
We will continue to build and demonstrate various methods for improving our security posture, so stay tuned for more!
If you’re using a time series database for security monitoring, we’d love to hear from you. Let us know on our Slack or on our community website. And if you want to try InfluxDB for yourself, get it here.
Thank you, Al Sargent and Peter Albert, for your assistance and contributions to this article.
