Table of Contents
Today, InfluxDB Cloud is generally available on Microsoft Azure. Now you have the freedom to run the leading time series database on whichever you prefer: Microsoft Azure, Google Cloud or AWS.
If you’re a Microsoft Azure customer, InfluxDB Cloud provides you with:
- Effortless scaling to handle the largest time series data workloads;
- Flexible usage-based pricing that frees you from worrying about over- or under-provisioning database instances; and
- The ability to ingest time series data from a broad range of Azure services.
Because InfluxDB Cloud is now multi-cloud, you can:
- Choose the cloud provider that best meets your needs around cloud services, developer tooling, budget and data compliance;
- Run production time series data workloads on the same cloud vendor that hosts the rest of your application infrastructure, reducing latency and data ingest costs; and
- Increase your flexibility to shift workloads across cloud vendors if needed.

Where does InfluxDB Cloud run?
InfluxDB Cloud now runs in five regions across three vendors and two continents. For Azure, this region is Azure West Europe, in Amsterdam. This will soon expand to six, as we expand to the Azure East U.S. region in Blue Ridge, Virginia, in early September.
Below is a list of locations where InfluxDB Cloud is available as of when this post was written, but here is the current list of InfluxDB Cloud Regions.
| Vendor | Region | Location |
| Microsoft Azure | West Europe | Amsterdam, Netherlands |
| Microsoft Azure | East US | Virginia |
| AWS | us-west-2 | Boardman, Oregon |
| AWS | eu-central-1 | Frankfurt, Germany |
| Google Cloud | us-central1 | Council Bluffs, Iowa |
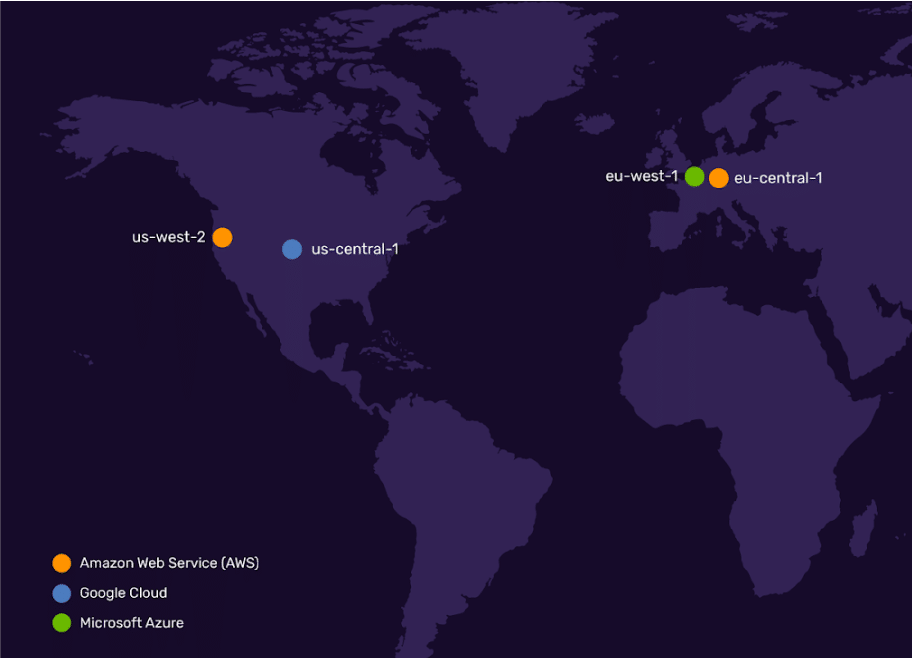 <figcaption> InfluxDB Cloud availability regions</figcaption>
<figcaption> InfluxDB Cloud availability regions</figcaption>
How does InfluxDB Cloud integrate with Microsoft Azure?
InfluxDB Cloud has a broad range of integration points with Azure, and Microsoft products in general. Before we dive in, let’s take a closer look at how our time series data platform handles time series data.
To ingest time series data, InfluxDB provides a number of options. Telegraf , our open source server agent for collecting metrics, can pull data from the following Microsoft technologies:
- Azure IoT Hub, using the Telegraf plugins for Azure Event Hub, AMQP, MQTT, and HTTPS, to collect IoT device telemetry data.
- Windows servers, using the Telegraf Windows Performance Counter plugin and Windows Services plugin, to ensure that your Windows servers are performant.
- GitHub, using the Telegraf plugin and InfluxDB Template for GitHub, to track stats for each of your repositories, such as the number of forks, open issues, etc.
- Azure Storage Queues, using the eponymous Telegraf plugin, to track queue sizes.
- SQL Server, using the Telegraf plugin and InfluxDB Template for SQL Server, to track the health and performance of your databases.
Also, Telegraf has over 200 plugins, covering technologies that aren’t Microsoft-specific but which you might find on Azure, such as Docker and Kubernetes. You can also pull in data from over 700 FluentD plugins, thanks to the Telegraf FluentD plugin.
As if that’s not enough, our Flux data scripting and query language has a SQL library that lets you enrich your time series telemetry with metadata from relational databases, including SQL Server. This metadata can include IoT asset information for example, the year, make, and model of a piece of IoT equipment. The specific Flux function you use to do this is called sql.from().
In addition to Telegraf and Flux, InfluxDB Cloud can also ingest data from Vector, Apache NiFi, OpenHAB, and JMeter. All in all, a broad range of options.
As for time series analysis, that is handled by InfluxDB itself. As mentioned, InfluxDB Cloud runs on Azure infrastructure running in the West EU region in Amsterdam, and by early September, East US in Virginia.
Additionally, when you analyze your data using Flux from within the InfluxDB UI, you do so in an embedded Monaco editor that delivers an experience that is similar to Microsoft Visual Studio Code with capabilities like autocompletion, syntax validation and highlighting, variable references and renaming, and more. There’s also a Flux plugin for VS Code, for developers building applications on top of InfluxDB. If you have features you’d like us to add, file an issue on the Flux LSP repo.
 <figcaption> Autocompletion in InfluxDB Cloud’s embedded Monaco editor</figcaption>
<figcaption> Autocompletion in InfluxDB Cloud’s embedded Monaco editor</figcaption>
These editors are two of many ways we sweat the details to ensure that you have a great experience working with InfluxDB, and is part of our time to awesome mantra.
Flux provides a broad range of functions for statistical analysis and forecasting, such as:
- Calculating percentiles to detect SLA compliance failures
- Windowing and aggregating data to pick out insights from noisy data sets
- Enriching monitoring data with business data in SQL databases like account name, type or size to detect anomalies by business measures
- Forecasting with Holt-Winters to predict outages and capacity issues
- Geographically tracking monitoring metrics to better determine which regions are experiencing problems
- Sophisticated anomaly detection, using techniques like Median Absolute Deviation (MAD) and Balanced Iterative Reducing & Clustering (BIRCH), to help you find and fix problems faster and reduce your mean time to resolution (MTTR)
To act on time series data, you can:
- Send alerts to Microsoft Teams, PagerDuty, Slack, Discord, Telegram, Pushbullet, and via webhooks.
- Pull data into your custom applications using our client libraries for Javascript/Node.js, C#, and more.
InfluxDB Cloud on Azure pricing
InfluxDB Cloud pricing has three tiers:
- Free, for hobbyists or those experimenting to see what technologies work best for their project
- Usage-based pricing, which charges your credit card each month according to how much data you write, store and query
- Annual plans, where you commit to a preset level of consumption in exchange for discounts beyond our usage-based pricing
To learn more, visit our InfluxDB Cloud pricing page. To go deeper on the costs of InfluxDB Cloud on Azure, check out this blog post, which covers the product’s total cost of ownership, as well as how to manage your data ingest and egress costs.
This pricing is the same whether you run InfluxDB Cloud on Azure, AWS, or Google Cloud. Regardless of where you run InfluxDB Cloud, you have access to all the benefits of its serverless cloud database architecture. Let’s explain.
What is a serverless database?
Unlike some “cloud” databases that are little more than fixed-sized virtual machines, databases with a fully elastic serverless architecture free you from having to worry about over- or under-provisioning your databases, and ensure that you only pay for what you use. This eliminates time-consuming migrations from one VM to another, or paying for unused capacity. After all, the cloud is supposed to be about productivity, not busywork.
InfluxDB Cloud applies serverless thinking to time series data. As you ingest, analyze, and visualize on ever-increasing amounts of data from sensors, software, and customer metrics, it automatically scales without any effort on your part.
How do we achieve this scalability?
- First, InfluxDB, our open source database, is purpose-built for time series telemetry and thus has high single-node scalability of hundreds of thousands of writes per second.
- Also, InfluxDB Cloud runs InfluxDB instances across multiple Kubernetes clusters that elastically scale in or out as needed, as well as provide redundancy for high reliability.
- Finally, InfluxData's site reliability engineering team manages InfluxDB Cloud 24/7 so you don't have to.
All this means you don’t pay for a fixed-sized VM, but instead pay only for what you use how much data you ingest and store, and how much you query.
Get started with InfluxDB Cloud on Azure
Go to cloud2.influxdata.com to get started. You’ll see a screen like this:
 <figcaption> InfluxDB Cloud 2 registration screen</figcaption>
<figcaption> InfluxDB Cloud 2 registration screen</figcaption>
Later in the registration process, you’ll be prompted to pick where to host your data. Once you pick Azure, you’ll instantly get access to InfluxDB Cloud. There’s no database-on-a-VM that you need to wait to start up. Because InfluxDB Cloud is a multi-tenant service, you can immediately get to work; it’s instant-on.
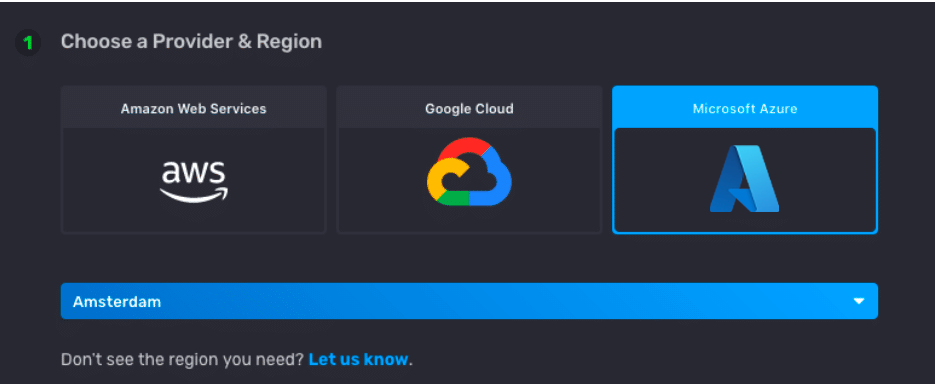 <figcaption> How to choose your InfluxDB Cloud 2 cloud provider and region</figcaption>
<figcaption> How to choose your InfluxDB Cloud 2 cloud provider and region</figcaption>
Then follow the steps in our Getting Started and Collecting Data guides. One hidden gem is this video which shows how easy it is to add data to InfluxDB Cloud using Telegraf:
When capturing data with Telegraf, client libraries, or other means, you’ll want to ensure that you use the correct URL for InfluxDB Cloud on Azure:
https://westeurope-1.azure.cloud2.influxdata.com
If you’re looking to run InfluxDB Cloud with another region or provider, you can find all our cloud URLs here.
Here’s another trick to ensure you always use the correct URL for InfluxDB Cloud: click the gear icon in the upper right corner of our InfluxDB Cloud 2 documentation:
![]()
You’ll then see this screen:
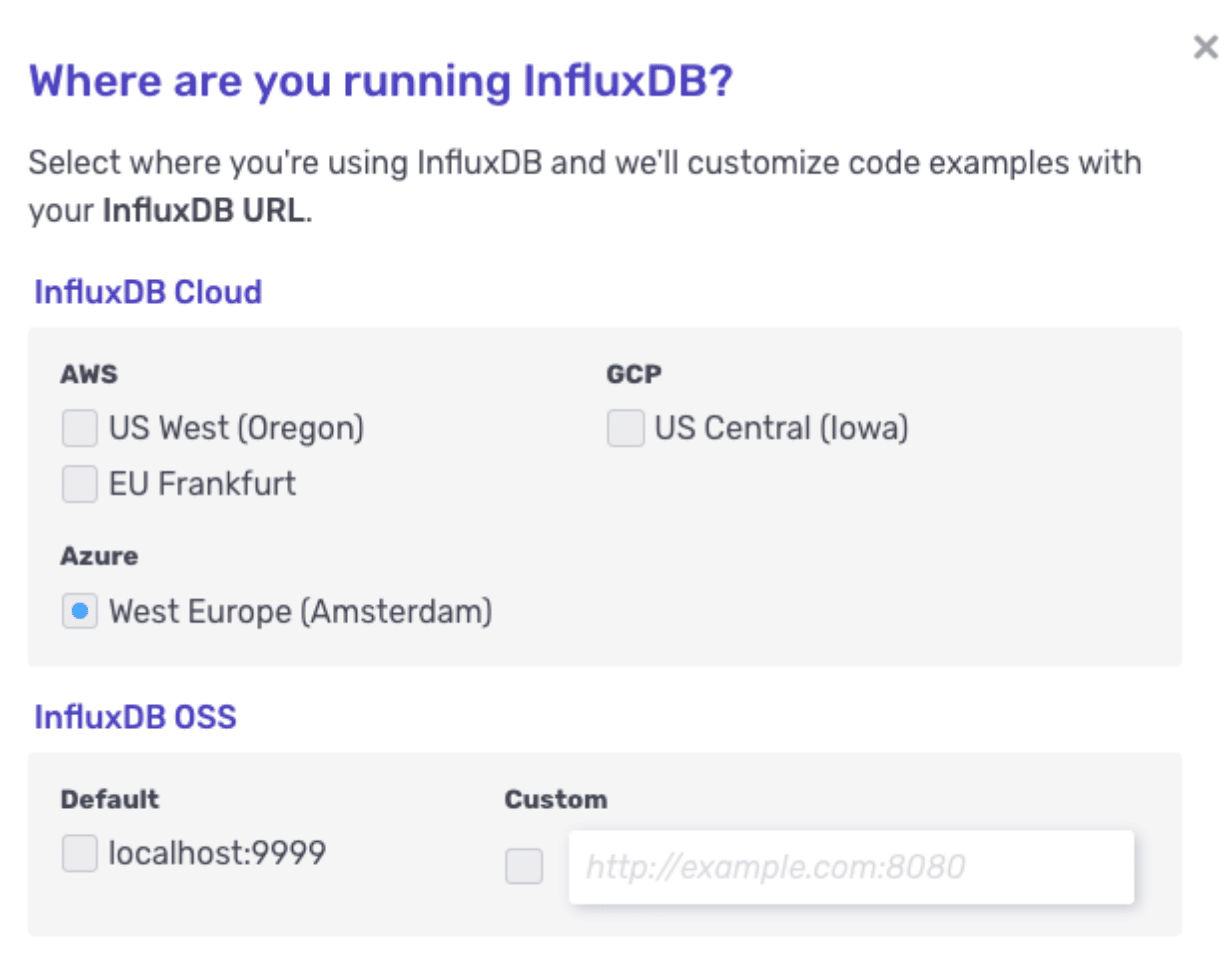 <figcaption> How to set your InfluxDB Cloud documentation to use the Azure URL</figcaption>
<figcaption> How to set your InfluxDB Cloud documentation to use the Azure URL</figcaption>
Choose Azure West Europe, and all your documentation examples will update accordingly.
Once you’ve done all that, join our ever-helpful InfluxDB community and Slack for questions.
Enjoy!
