Table of Contents
A few weeks ago I hinted at some big changes coming in the InfluxDB clustering design. These changes came about because of the testing we’ve done over the last 3 months with the clustering design that was going to be shipped in 0.9.0. In short, the approach we were going to take wasn’t working. It wasn’t reliable or scalable, and made sacrifices for guarantees we didn’t need to provide for our use case.
Six weeks ago we took a step back and re-evaluated our entire approach to clustering. We looked at the kinds of guarantees we need to provide and, more importantly, guarantees that don’t matter for us. Finally, we revisited the literature around distributed systems, consensus, and conflict resolution. We realized that we could architect a much simpler system that achieved our goals for scalability and maximum throughput by relaxing constraints that aren’t necessary for the use case of time series data.
The end result is the clustering implementation that will be in the next build of InfluxDB. It’s designed for throughput and combines a CP system with an AP system for the primary write path. As a whole it is designed to be highly available and eventually consistent. Read on for a very detailed writeup of the design. Feedback is very appreciated. To say distributed systems are difficult would be vastly understating the challenge. We know that it’ll take iterations, but this design is the foundation we’re building on.
Assumptions and Requirements
Before getting into the specific design, we need to lay out some key requirements for the time series use case that we’re targeting. There are also some assumptions about how the database will be used that will allow us to greatly simplify the design.
Assumptions
- Time series data is almost always new data (or historical backfill) that is keyed off information provided by the client and is immutable. In our case each point is keyed off measurement name, tags, and the timestamp.
- If the same data point is sent multiple times, it is the exact same data that a client just sent twice
- Deletes are a rare occurrence. When they do occur it is almost always against large ranges of old data that are cold for writes
- Updates to existing data are a rare occurrence and contentious updates never happen
- The vast majority of writes are for data with very recent timestamps
- Scale is critical. Many time series use cases handle data set sizes in the terabyte or petabyte range
- Being able to write and query the data is more important than having a strongly consistent view
- Many time series are ephemeral. There are often time series that appear only for a few hours and then go away, for example a new host that gets started and reports for a while and then gets shut down
Notice from the assumptions that we’re talking primarily about inserts with large range deletes. Contentious updates don’t come into the picture, which makes conflict resolution a much easier problem to deal with. More on that later, let’s talk specific requirements.
Requirements
- Horizontally scalable - design should be able to initially support a few hundred nodes, but be able to scale to a few thousand without a complete rearchitecture. Reads and writes should scale linearly with the number of nodes.
- Available - for the read and write path, favor an AP design. Time series are constantly moving and we rarely need a fully consistent view of the most recent data.
- Should be able to support billions of time series, where an individual series is represented by the measurement name plus tag set combination. This arises from the ephemeral time series assumption.
- Elastic - nodes should be able to leave and new nodes join the cluster. For 0.9.0 this need not be automatic, but the design should facilitate this in future releases without a rearchitecture.
The requirements are pretty straight forward. Mostly what you’d expect from a horizontally scalable distributed system that is designed for eventual consistency. There are other requirements for InfluxDB as a whole, but these are the requirements driving the clustering design.
If these requirements and assumptions seem off to you, let us know. But these lay out a clear picture that InfluxDB isn’t designed as a general purpose database. If that’s what you need, go elsewhere. InfluxDB is designed for time series, metrics, and analytics data, which are a high throughput insert workload.
Clustering Design
The new clustering design consists of two systems: a CP system for storing cluster metadata and an AP system for handling writes and reads. This section will cover the design for each and close with a section that shows how the two work together in a configured cluster.
Cluster Metadata - CP
The cluster metadata system is a Raft cluster that stores metadata about the cluster. Specifically, it stores:
- Servers in the cluster - unique id, hostname, if it's running the cluster metadata service
- Databases, Retention Policies, and continuous queries
- Users and permissions
- Shard Groups - start and end time, shards
- Shards - unique shard id, server ids that have a copy of the shard
An update to any of this data will have to run through the cluster metadata service. The service is a simple HTTP API backed by the Hashicorp Raft implementation using BoltDB as the underlying storage engine.
Every server in the cluster keeps an in memory copy of this cluster metadata. Each will periodically refresh the entire metadata set to pick up any changes. For requests coming in, if there is a cache miss (like a database it doesn’t yet know about), it will request the relevant information from the CP service.
Writes - AP
For handling reads and writes, we leverage the fact that time series data is almost always new immutable data. This means we can bypass conflict resolution schemes like vector clocks or pushing it out to the client. We favor accepting writes and reads over strong consistency.
One caveat is that shard groups and shards are created in the CP system. During normal operation these will be created well ahead of the time they will have data written into them. However, that means that if a node is partitioned off from the CP system for too long, it won’t be able to write data because it won’t have the shard group definitions.
For example, let's take a look at what happens when a write comes in. Say we have a cluster of 4 servers:
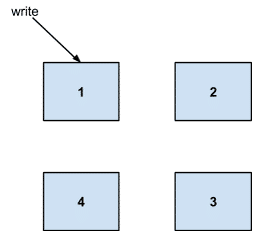
And the data is owned by servers 2-3.
To determine which server owns data we look at the timestamp of the point to see which shard group it belongs to. If the shard group doesn’t exist, we call out to the CP cluster metadata service to get or create a shard group for that point’s time range.
The shard group returned from the metadata service should have shards in it and those shards should be assigned to servers in the cluster. Thus the cluster metadata service is responsible for laying out where data lives in the cluster. Shard groups will be created ahead of time when possible to avoid a thundering herd of writes hitting the cluster metadata service when a new time range comes up.
Once we have the shard group we hash the measurement name and tagset and mod that against the number of shards to see which shard in the group the data point should be written to. Notice that this isn’t a consistent hashing algorithm. The reason we’re not bothering with consistent hashing is because once the shard group becomes cold for writes we don’t need to worry about balancing those across a resized cluster. While getting more read scalability is as simple as copying the cold for write shards to other servers in the cluster.
The key for the data is the measurement name, tagset, and nanosecond timestamp. As an example, let's say that the shard exists on servers 2, 3, and 4:
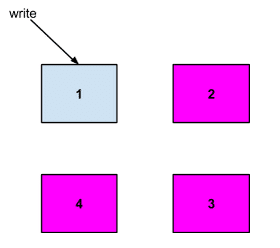
What happens next depends on the requested consistency level of the write operation. The different levels are:
- Any - succeed if any of the servers that owns the data accept the write or once the receiving server (1 in our example) writes the data as a durable hinted handoff (more on this later)
- One - succeed once one of the servers that owns the data (2, 3, 4) responds with success
- Quorum - succeed when n/2 + 1 servers accept the write where n is the number of servers that have a copy of the shard
- All - succeed when all servers (2, 3, 4) accept the write
Requests to write the data are made in parallel and success is returned to the client when the requested level is hit.
Write Failures
What happens when a write fails or partially succeeds? For example, say you asked for a quorum, but were only able to write to host 2, while hosts 3 and 4 timed out.
At this point we take advantage of one of our key assumptions about time series data: writes are always for new data that is keyed off information provided by the client.
We return a partial write failure to the client. In the meantime, the write could be replicated in the background by hinted handoff. The client can then either fail, or it can make the request again, which would only overwrite the existing value. But it’s important to note that a failed partial write could end up being taken in and fully replicated.
Hinted Handoff
Hinted handoff is helpful for quick recovery from short term outages like server restarts or temporary unavailability caused by GC pauses or large queries causing a system to get overloaded.
In our previous example, when a write comes into server 1, it will attempt to write that point to servers 2, 3, and 4. If the write consistency is Quorum or lower, it’s possible for the write to use hinted handoff for any downed servers.
For example if we had a quorum level write, 2 of the servers that have the shard (2, 3, or 4) will have to accept the write. A success is returned to the client. Then let us say that for some reason server 4 timed out. Server 1 would then write the data point as a hinted handoff.
The hinted handoff is a durable write queue for any writes the server has missed. So server 1 would now have writes stored on disk for server 4. When server 4 comes back up server 1 would then push the writes from its hinted handoff queue to server 4.
We should have settings for the max size of the hinted handoff queue. Writes from the hinted handoff queue should also be throttled to avoid overloading a server that has recently come back up after an outage.
If the hinted handoff writes hit their TTL or if server 1 fills up its queue for server 4, server 4 will have to recover through the anti-entropy repair process.
Anti-Entropy Repair
Anti-entropy repair ensures that we get eventual consistency on all of our data. Servers within the cluster will occasionally exchange information to ensure that they have the same data. Anti-entropy is for cases where a server has been down for an extended period of time and hinted handoff wasn’t able to buffer all the necessary writes.
A Merkle Tree for each shard will be compared against the other servers that own that shard. Here again we’ll make use of a time series assumption: that writes are always for new data and we want all of it.
Thus, if two servers find that a shard has mismatched data, they will work together to walk the merkle tree to find the data points that don’t match. They’ll exchange their divergent data and the shard will be a union of the data for that shard from the servers.
Another key assumption in time series data will help us to lesson the burden of comparisons. Specifically, that all of the data getting written is for recent time frames, except when loading historical data.
Because of this, we’ll check consistency on old shards infrequently. Maybe once an hour or a day, it’ll be configurable. A full repair is something that a user should be able to request (like Cassandra’s node repair tool).
For the shards that are hot for writes, we’ll run comparisons only for data that is older than some small configurable amount of time. For example, we’ll only run the hash comparison on data in the shard that is older than 5 minutes.
Conflict Resolution
Conflict resolution only comes into play if the user is performing updates to existing data points. Our scheme for dealing with conflict resolution is simple: the greater value wins. If it is a situation where data is missing on one or more servers, then the final set should be the union of the data from all servers.
This keeps our overhead for doing conflict resolution incredibly low. No vector clocks are anything needed.
Given this, update and delete operations should set a consistency level of ALL to ensure that they are successful and won’t be lost. If ALL haven’t responded, it’s possible that the delete would be reverted or the update overwritten when anti-entropy repair kicks in.
This means that durable deletes and updates are not highly available. Our assumption is that both of these operations are rare.
The caveat with this scheme is that data retention enforced by retention policies will actually be eventually consistent. Each node will enforce the retention policy locally against its shards.
Dropping Large Segments of Historical Data
Delete operations that run through the normal write path aren’t highly available if using the ALL consistency level. However, deletes that drop full shards of old historical data can be a bit more fault tolerant.
That’s because dropping shards goes through the Cluster Metadata service. Remember that shards are contiguous blocks of time ordered data. The most efficient way to drop a large amount of old historical data is to drop an entire shard or shard group.
These operations are performed against the CP cluster metadata service. The request can come into any server in the cluster and will be routed accordingly.
Tunable query consistency
The initial versions of clustering will check a single server that has a copy for each shard, making the effective consistency level ONE. Later versions will enable tunable levels of consistency.
Conclusion
At the end of all this, you may ask, where does this design fall on the CAP spectrum? The answer is that it’s neither a pure CP or pure AP system. There is a part that is CP, but the data from that system is eventually consistent across the cluster. There are also parts that are AP, but that would cease to be available if there were a long enough partition between those nodes and the CP system.
There are many more things we could talk about with respect to the clustering design. Particularly around how each failure case will be handled. There are more in depth details that we could cover around deletes and updates to cluster metadata. Over the next few months we’ll work on documenting those things and fleshing out each case in detail. Those situations in a production environment matter more than whether it’s CP or AP and we’ll strive to provide as much information and data as we can.
This design is based on three iterations of clustering in InfluxDB. We’ve landed here based on trade-offs we felt were acceptable and by focusing on some of the most important parts of our use case: horizontal scalability with low write overhead. Feedback, thoughts, and even challenges are welcome!


