October Monthly Product Update – InfluxDB New Engine and More!
By
Bharat Bhat
updated October 20, 2023
Product
Use Cases
Navigate to:
We love to write and ship code to help developers bring their ideas and projects to life. That’s why we’re constantly working on improving our product in sync with developer needs to ensure their happiness and accelerate Time To Awesome.
This month is very special. We now have a new engine that significantly increases the “horsepower and torque” for InfluxDB.
We also expanded the Data Explorer UI, made it easier for you to apply custom Data Retention to your organization, and added an onboarding wizard for the Arduino platform – along with fixing bugs, of course.
1 - New engine – unbounded cardinality, SQL, and real-time analytics
InfluxDB Cloud customers using the new storage engine have their cardinality limits lifted completely. Users can write any kind of event data with infinite cardinality and slice-and-dice data on any dimension without sacrificing performance. This opens up use cases such as events, tracing, and all sorts of ephemeral unbounded cardinality data.
The new engine also brings blazing fast queries. Queries that touch a large number of time series are orders of magnitude faster with the new engine than in our previous versions of InfluxDB. Querying across 10 series or 1 million series is all the same. This makes performing real-time analytics – in the way you want – a reality.
The new engine supports SQL natively and our cloud customers will soon be able to connect using Postgres-compatible clients like psql, Grafana’s Postgres data source, and BI tools like PowerBI and Tableau. We will also be rolling out Apache Arrow FlightSQL as the standard matures, giving users high-performance access to millions of rows of time series data.
Here’s what it looks like under the hood:
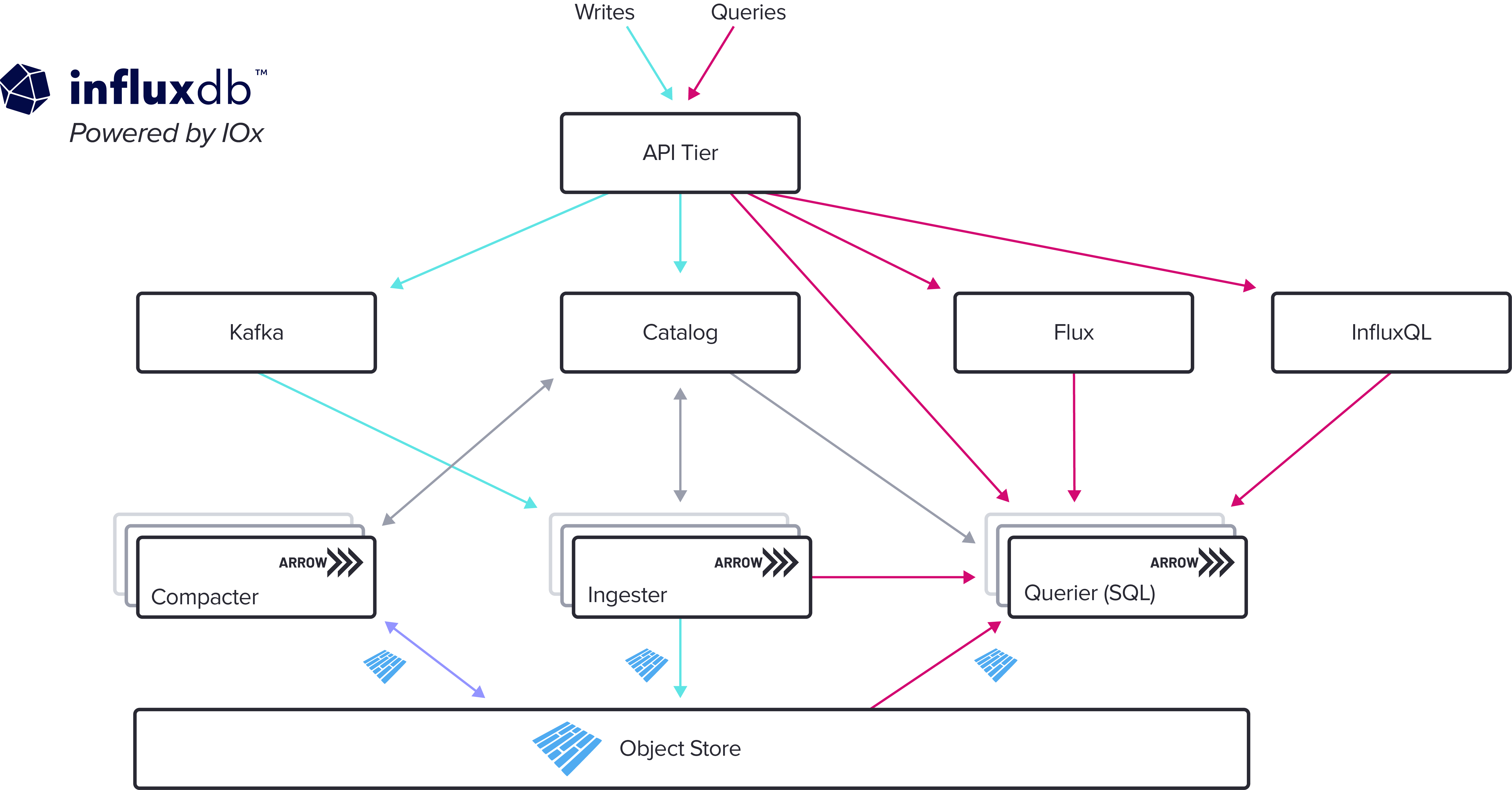
The new storage engine represents an advanced core that we intend to build many new features upon. Bulk data ingest, bulk data export, and integrations with other third-party systems are all planned for the near future. We’ll also be launching dedicated cloud tiers and a new on-premises Enterprise product based on these new engine capabilities.
To take advantage of all these advancements, please sign up here.
2 - Other key features shipped in October
Along with the new engine, we also released major new features relating to Data Explorer, Custom Data Retention, and onboarding to Arduino. Please take a look at my blog posts below for more information.
-
Data Explorer - Significant improvements in Raw Data Mode for parsing and display. You also now have the capability to search for multiple measurements at the same time.
-
Custom Data Retention - With InfluxDB being able to handle hundreds of thousands of data points per second, you might need a way to manage expiring data that is no longer valuable. InfluxDB offers retention policies that automate the process of expiring old data.
-
Arduino Onboarding - The new Arduino onboarding wizard allows you to write and query data to and from InfluxDB within your first 5 minutes of logging in.
3 - Bug fixes
This month, we fixed a number of outstanding bugs to improve the user experience with InfluxDB:
-
Improved styling of graphs and single stat visualizations during rendering
-
InfluxDB University is now accessible from the “Useful Links” section on the homepage
-
Resolved table header rendering issues for simple table
-
Prevented decimal place customizations from crashing visualizations
Please reach out to us if you have any specific design or implementation questions. We are always here to help.
