Introduction to Apache Arrow
By
Anais Dotis-Georgiou
updated October 20, 2023
Use Cases
Developer
Navigate to:
This post was originally published on The New Stack and is reposted here with permission.
A look at what Arrow is, its advantages and how some companies and projects use it.
Over the past few decades, using big data sets required businesses to perform increasingly complex analyses. Advancements in query performance, analytics and data storage are largely a result of greater access to memory. Demand, manufacturing process improvements and technological advances all contributed to cheaper memory.
Lower memory costs spurred the creation of technologies that support in-memory query processing for OLAP (online analytical processing) and data warehousing systems. OLAP is any software that performs fast multidimensional analysis on large volumes of data.
One project that is an example of these technologies is Apache Arrow. In this article, you will learn what Arrow is, its advantages and how some companies and projects use Arrow.
What is Apache Arrow?
Apache Arrow is a framework for defining in-memory columnar data that every processing engine can use. It aims to be the language-agnostic standard for columnar memory representation to facilitate interoperability. Several open source leaders from companies also working on Impala, Spark and Calcite developed it. Among the co-creators is Wes McKinney, creator of Pandas, a popular Python library used for data analysis. He wanted to make Pandas interoperable with data processing systems, a problem that Arrow solves.
Apache Arrow technical breakdown
Apache Arrow achieved widespread adoption because it provides efficient columnar memory exchange. It provides zero-copy reads (the CPU does not copy data from one memory area to a second one), which reduces memory requirements and CPU cycles.
Advantages of columnar storage
Because Arrow has a column-based format, processing and manipulating data is also faster. Imagine that we write the following data to a datastore:
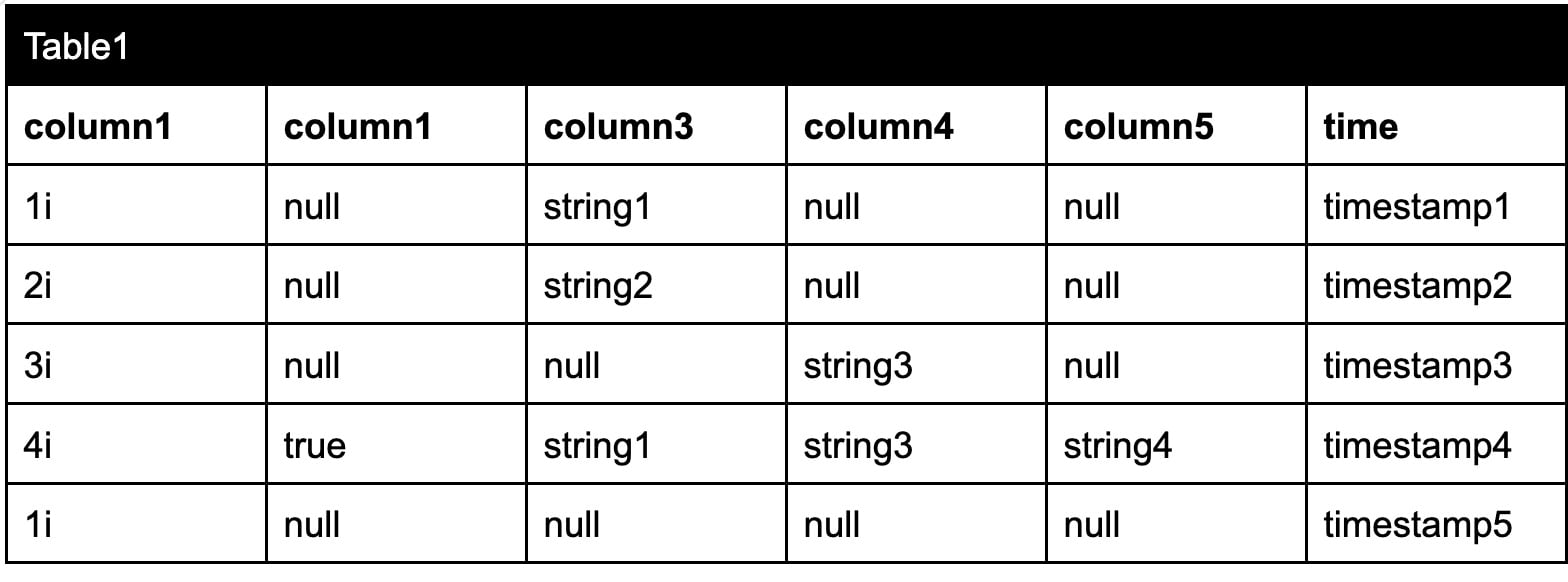
However, the engine stores the data in a columnar format like this:
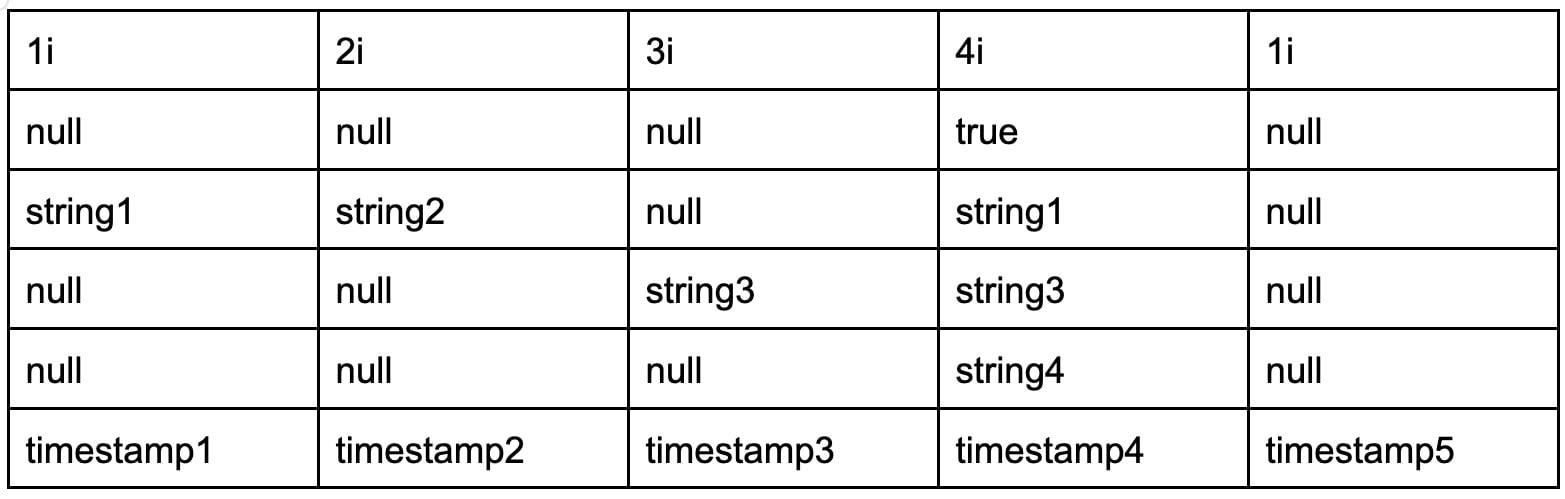
In other words the Arrow memory buffer groups data by column instead of by row. Storing data in a columnar format allows the database to group like data together for more efficient compression. Specifically, Apache Arrow defines an inter-process communication mechanism to transfer a collection of Arrow columnar arrays (called a “record batch”) as described in this FAQ.
Apache Arrow developers designed Arrow for modern CPUs and GPUs, so it can process data in parallel and take advantage of things like single instruction/multiple data (SIMD), vectorized processing and vectorized querying.
Advantages of standardization in storage
Arrow aims to be the standard data format for databases and languages. Standardizing the data format removes costly data serialization and deserialization. Any system that supports Arrow can transfer data between them with little overhead, especially with the help of Apache Arrow Flight SQL (more on that later).
Advantages of multi-language support
The Arrow project contains libraries that make working with the Arrow columnar format easier in many languages including: C++, C#, Go, Java, JavaScript, Julia, Rust, C (GLib), MATLAB, Python, R and Ruby. These libraries enable developers to work with the Arrow format without having to implement the Arrow columnar format themselves.
What is Apache Arrow Flight SQL?
Another benefit of Apache Arrow is its integration with Apache Arrow Flight SQL. Having an efficient in-memory data representation is important for reducing memory requirements and CPU and GPU load. However, without the ability to transfer this data across networked services efficiently, Apache Arrow wouldn’t be that appealing. Luckily Apache Arrow Flight SQL solves this problem. Apache Arrow Flight SQL is a “new client-server protocol developed by the Apache Arrow community for interacting with SQL databases that makes use of the Arrow in-memory columnar format and the Flight RPC framework.”
Background
To understand the benefits of Arrow and Arrow Flight SQL, it’s helpful to understand what came before. ODBC (Open Database Connectivity) and JDBC (Java Database Connectivity) are APIs for accessing databases. JDBC can be thought of as a Java version of ODBC, which is C-based. These APIs provide a standard set of methods for interacting with a database. They define how to formulate SQL queries, how to handle the results, error handling and so on. Specifically, JDBC and ODBC have been used for decades for tasks like:
- executing queries
- creating prepared statements
- fetching metadata about the supported SQL dialect
- available types
However, they don’t define a wire format. A wire format refers to the way data is structured or serialized for efficient transfer over a network. Examples include JSON, XML and Protobuf, which the database driver must define.
Advantages of Arrow Flight SQL
Luckily, database developers don’t have to define a wire protocol with Arrow Flight SQL. Instead, they can just use the Arrow columnar format. ODBC and JDBC use row-based formats and fall short for columnar-based formats like Arrow. Arrow eliminates the need for data transposition with row-based APIs. It also enables clients to communicate with Arrow-native databases without data conversion or expensive serialization and deserialization.
Arrow Flight SQL also provides features like encryption and authentication out of the box, further reducing development effort. This is largely a result of the Flight RPC framework, which is built on top of gRPC. Finally, Arrow Flight SQL enables further optimizations such as parallel data access. Parallel data access refers to the ability of these systems to divide a task that involves reading or writing large amounts of data into smaller subtasks that can be executed simultaneously. The data might be partitioned across multiple disks, nodes or database partitions and a single query or operation could access multiple partitions at the same time, greatly improving performance.
Companies and projects using Apache Arrow
Apache Arrow powers a wide variety of projects for data analytics and storage solutions, including the following:
- Apache Spark is a large-scale, parallel processing data engine that uses Arrow to convert Pandas DataFrames to Spark DataFrames. This enables data scientists to port over proof-of-concept models developed on small datasets to large datasets.
- Apache Parquet is a columnar storage format that’s extremely efficient. Parquet uses Arrow for vectorized reads. Vectorized readers make columnar storage even more efficient by batching multiple rows in a columnar format.
- InfluxDB is a time series data platform. Its new storage engine uses Arrow to support near-unlimited cardinality use cases, querying in multiple query languages (including InfluxQL and SQL and more to come), and to offer interoperability with business intelligence and data analytics tools.
- Pandas is a data analytics toolkit built on top of Python. Pandas uses Arrow to offer read and write support for Parquet.
Using a toolset or being part of an ecosystem with a huge and well-functioning community is a massive benefit to the adopters of the technology. Cross-organizational collaboration results in faster resolution time for issues, spurs innovation and promotes interoperability.
Recommended resources
Apache Arrow is a columnar format framework that reduces memory and CPU load. It also enables faster data transfer with the help of Apache Arrow Flight SQL.
To take advantage of Apache Arrow in the context of InfluxDB, sign up here. If you would like to contact the InfluxDB 3.0 developers who contributed a ton of work the Apache ecosystem, join the InfluxData Community Slack and look for the #influxdb_iox channel.
