Table of Contents
Thsi article was originally published in The New Stack. Posted here with permission.
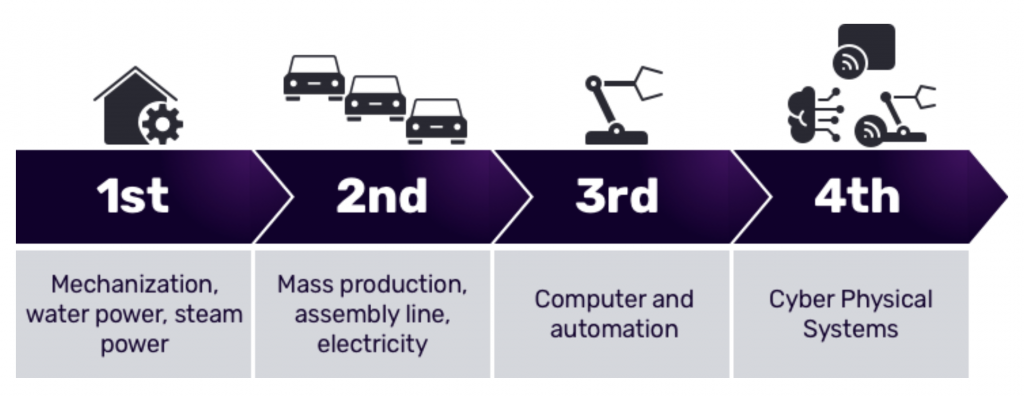
The industrial revolution was a watershed period in human history. The shift from piecemeal, cottage-industry work to mechanized manufacturing transformed the way humans work. Since the 18th century, successive waves of innovation, such as the assembly line and the computer, continued to alter and change the nature of manufacturing. Today, we find ourselves in the midst of another industrial transformation. Typically referred to as Industry 4.0, this latest wave of innovation involves feeding data – either raw or as trained machine learning models – to autonomous systems that enhance manufacturing processes.
Manufacturers seek to generate consistent and predictable output. To do that, they have embraced physical instrumentation, which involves putting sensors on equipment to measure different aspects of a process. These sensors are the basis for the industrial Internet of Things (IIoT) and record critical data about how industrial machinery functions.
Critical context: time
Industrial operators need context for that data to begin to make sense of it. No matter what type of reading a sensor collects, it always includes a timestamp. This time-series data, therefore, provides a shared context for these readings and becomes the critical fulcrum for processing and understanding Industry 4.0 IoT data.
Fortunately, the basic principles underpinning Industry 4.0 mesh with the characteristics of time-series data. Industry 4.0 strives for:
- Interconnection – The ability to have devices, sensors and people connect and communicate with each other.
- Information transparency – Interconnection allows for the collection of large amounts of data from all points of the manufacturing process. Making this data available to industrial operators provides them with an informed understanding that helps identify areas for innovation and improvement.
- Technical assistance – The ability to aggregate and visualize the collected data using a centralized dashboard allows industrial operators to make informed decisions and solve urgent issues on the fly. Furthermore, centralized data views help industrial operators avoid performing a range of tasks that are unpleasant or unsafe.
- Decentralized decisions – The ability for systems to perform their tasks autonomously based on data collected. These systems only require human input for exceptions.
Compare these concepts and goals with some of the IIoT use cases for time-series data, and you can start to see how time-series data touches almost every aspect of industrial operations, both physical and virtual.
| IIoT use case | |
| Metrics | Temperature, pressure, flow, valve state, etc. |
| Resolution | (Sub) seconds |
| Retention | 5 to 10 years (or longer), no downsampling |
| Main goals | Quality guarantee, Overall Equipment Effectiveness (OEE), predictive maintenance |
Incorporating time
Industrial operators want greater observability into their machinery and processes, and time-series data provides the raw data for that. Transforming that raw data into actionable insights is one of the key objectives for time-series data in Industry 4.0. Having the right tools in place for processing, transforming and analyzing that data can make or break Industry 4.0 initiatives.
The challenge here is that many factories and manufacturers use legacy data historians, the time-series databases common in Industry 3.0. There are several reasons why these solutions are not ideal for an Industry 4.0 system.
- Cost – These solutions are expensive to set up and maintain, plus they charge annual license and support fees. Most installations of legacy data historians require custom development work to fit the needs of a specific business or process and may require external consulting resources. The proprietary nature of these systems means this work is time consuming and expensive.
- Vendor lock-in – These solutions are often Windows-based and do not offer a simple, open API to interface with other software. Therefore, you need to buy all integrations and components from a single vendor, locking you into a proprietary solution.
- Scalability – Scalability issues can stem from both commercial and technical problems. On the technical side, these legacy data historians were built with a limited dataset in mind. This creates problems when introducing advanced capabilities like artificial intelligence or machine learning (AI/ML). These capabilities require a lot more data to train the models, which legacy systems cannot handle.
- Poor developer experience – Most legacy solutions have a traditional closed design with limited API support. As a result, it takes a lot of time and money to implement or integrate these systems. These closed-design solutions provide few built-in tools, no developer community and do not support a modular development approach, thereby limiting developers' ability to pick and choose the tools that best fit the needs of their organization.
- Siloed data – SCADA makers may provide a data historian for their devices, but most industrial organizations that use a traditional manufacturing execution system (MES) consolidate all their data to a single on-premises data historian. However, the lack of microservices architecture and open APIs, and an extensive use of firewalls and subnets, typically separate the data at the site level.
Without the ability to integrate with modern IT, cloud, or open source software (OSS) solutions, legacy data historians do not provide the flexibility and connectivity necessary to evolve industrial operations. This significantly reduces the efficacy of the operational technology and IT systems involved, and the data they contain, in an Industry 4.0 context because the lack of interoperability between the data historian and other systems inhibits innovation and limits observability.
Replacing legacy data historians
So, if legacy data historians aren’t the answer, what should companies use instead?
It may be tempting for manufacturers to fall back on familiar technology, like relational databases, to replace their legacy data historians. However, relational databases can’t scale for the high-volume data and lack of fixed schema that characterize time-series data.
A more suitable replacement for legacy data historians is an open source time-series platform. InfluxDB, for example, is purpose-built to handle the volume and velocity of time-series data. It uses APIs so it’s able to integrate with virtually any other connected device. InfluxDB is a schemaless platform, so it automatically adjusts to changes in the shape of incoming IIoT data.
Another open source tool that complements InfluxDB is Telegraf, a plugin-based collection agent. Telegraf is written in Go, compiles into a single binary with no external dependencies and requires a minimal memory footprint. With hundreds of plugins, many of which cater to the most popular IIoT technologies and protocols, such as OPC-UA, MQTT, Modbus, AMQP and Kafka, Telegraf connects directly to, or scrapes data from, virtually any database, application, system or sensor.
Managing and leveraging time series data
This broad connectivity also enables manufacturers to monitor and manage distributed systems and networks and remote devices in the field more easily. For example, if a manufacturer has three different facilities spread across the country, Telegraf and InfluxDB allow them to collect data from every sensor on every machine in each facility.
The data generated at each facility can be aggregated and stored on site. Those aggregations can also be sent to a central storage instance that collects data from all three sites and be rolled up to generate company-wide insights.
These same principles apply to any connected devices on the edge, whether that includes rural solar panels or ocean buoys with GSM (Global System for Mobile) connectivity. No matter how your company defines “the edge”, Telegraf and InfluxDB can handle data collection from the devices there.
InfluxDB has a mature ecosystem for IIoT systems. Some of the leading industrial systems, including PTC Kepware, PTC ThingWorx, Siemens WinCC OA and Bosch ctrlX use InfluxDB as their time-series platform. Preconfigured integrations already exist with these systems, so companies, like those making the transition to Industry 4.0, can quickly and easily upgrade their time-series database to InfluxDB.
Getting data into InfluxDB is one part of the equation to managing and leveraging time-series data. Analyzing and acting on that data are equally important parts. The Flux query language works with all components of the InfluxDB platform (i.e., InfluxDB, Telegraf). Flux allows you to slice and dice time-series data to produce actionable insights, set thresholds and alerts, and output data to any desired end points. By using Flux and InfluxDB, you can create visualizations for your data that assist with identifying usage patterns and areas for optimization or predicting maintenance.
The bottom line
Ultimately, incorporating an open source time-series database into your Industry 4.0 technology stack helps to bridge the gap between operational technology and information technology, delivering greater observability for both physical and virtual plant and providing critical data about all aspects of the manufacturing process. A solution like InfluxDB empowers industrial operators to harness data, providing critical information to workers on the factory floor and adding measurable value throughout the manufacturing process.
