Table of Contents
One of the best things about getting started with InfluxDB over traditional relational databases is the fact that you don’t need to pre-define your schema in order to write data. This means you can create a bucket and write data in seconds, which can be pretty powerful to developers who care way more about the application they’re building than the mechanics of storing the data.
As your application grows, and more users are adding their own data, it can become tricky to ensure that the schema doesn’t get muddled up with junk. Some customers actually end up developing some sort of protection service to ensure only the right points make it to their production databases.
To help solve this problem for our users, we have introduced a new option to explicitly define the schema of the data that can be written to a bucket. The schema is specific to each measurement written to a bucket, which allows it to grow as new measurements are added.
In this post, I’m going to walk you through some of the concepts of the new explicit schema feature using one of my favorite datasets, the USGS Earthquake data. If you’re feeling antsy, feel free to jump directly to our documentation to learn all the details.
To follow along with this post, you’ll need a free InfluxDB Cloud account as well as the latest InfluxDB Cloud Command Line Tool (CLI) available on our Downloads page. You can quickly set up your CLI to work with cloud by following the instructions here just make sure the version of the CLI is 2.1 or greater. You can check using explicit.
Creating a bucket with an explicit schema
In order to work with an explicit bucket schema, you need to make sure that you create a new bucket with the schema type set to explicit (the default for new buckets is to allow any schema, aka implicit). You can do this using the influx command line tool.
influx bucket create \
--name usgs \
--description "Only USGS data allowed in here" \
--retention 7d \
--schema-type explicit
ID Name Retention Shard group duration Organization ID Schema Type
6f5781a53eed10f5 usgs 168h0m0s n/a 03921cbebef90000 explicitWhen you log into your InfluxDB Cloud account through your browser, you can see the new Bucket created with the Explicit Schema Type.
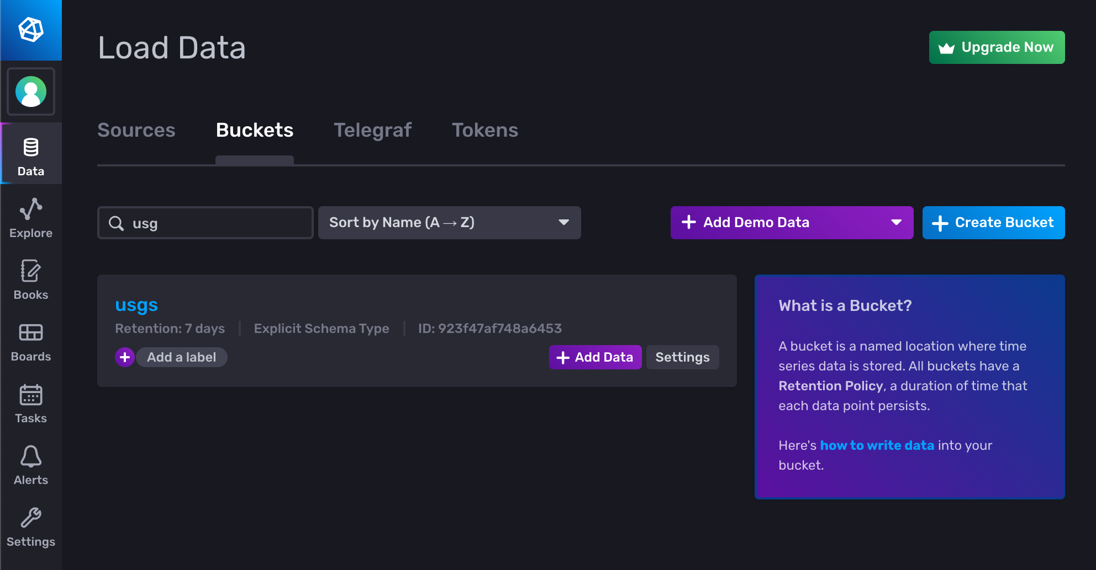
Adding measurement schemas to your bucket
Now that the bucket is created, we can start to add schemas for each of the measurements we want to store in that bucket. Any data that doesn’t match one of the measurement schemas will be rejected from the bucket.
Measurement schemas are just text files in either CSV, JSON, or NDJSON formats that tell InfluxDB what tags, fields, and types to allow in the measurement. Some example files are in the documentation. For this USGS dataset, you can find the schema files in our sample data repository. Here’s the one for the earthquake measurement in NDJSON format.
{"name": "time", "type": "timestamp"}
{"name": "alert", "type": "field", "dataType": "string"}
{"name": "cdi", "type": "field", "dataType": "float"}
{"name": "depth", "type": "field", "dataType": "float"}
{"name": "detail", "type": "field", "dataType": "string"}
{"name": "dmin", "type": "field", "dataType": "float"}
{"name": "felt", "type": "field", "dataType": "integer"}
{"name": "gap", "type": "field", "dataType": "float"}
{"name": "ids", "type": "field", "dataType": "string"}
{"name": "lat", "type": "field", "dataType": "float"}
{"name": "lon", "type": "field", "dataType": "float"}
{"name": "mag", "type": "field", "dataType": "float"}
{"name": "mmi", "type": "field", "dataType": "float"}
{"name": "nst", "type": "field", "dataType": "integer"}
{"name": "place", "type": "field", "dataType": "string"}
{"name": "rms", "type": "field", "dataType": "float"}
{"name": "sig", "type": "field", "dataType": "integer"}
{"name": "sources", "type": "field", "dataType": "string"}
{"name": "status", "type": "field", "dataType": "string"}
{"name": "tsunami", "type": "field", "dataType": "integer"}
{"name": "types", "type": "field", "dataType": "string"}
{"name": "url", "type": "field", "dataType": "string"}
{"name": "code", "type": "tag"}
{"name": "id", "type": "tag"}
{"name": "magType", "type": "tag"}
{"name": "net", "type": "tag"}
{"name": "title", "type": "tag"}The format here is pretty straightforward. The three types are timestamp, field, and tag and the only type you will need to add the data type to are the fields, since tags are always strings.
To create these schema files, I’ve found that it’s useful to ingest the data into a temporary bucket with an implicit schema type, then use the schema package in Flux to inspect the tags (schema.measurementTagKeys) and field keys (schema.measurementFieldKeys) in the data.
If you aren’t sure about the data types for the fields, you can also run a simple Flux query to fetch that information.
import "influxdata/influxdb/schema"
from(bucket: "temp_bucket")
|> range(start: v.timeRangeStart, stop: v.timeRangeStop)
|> filter(fn: (r) => r._measurement == "earthquake")
|> schema.fieldsAsCols()
|> group()
|> limit(n: 1)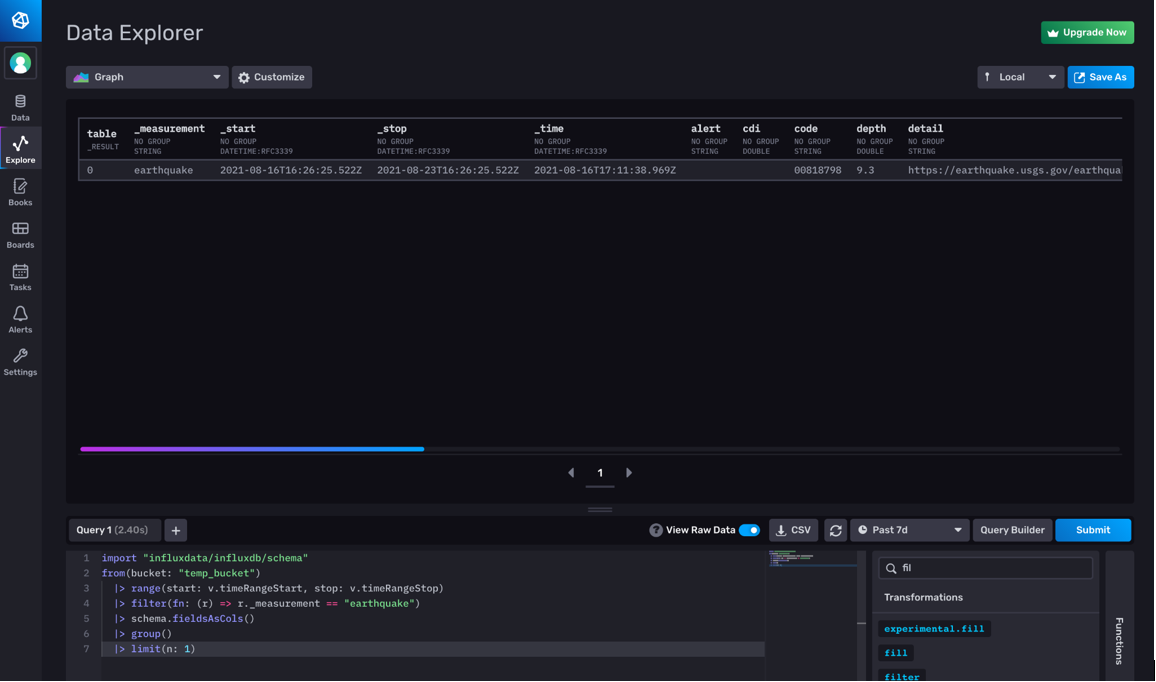
You can see the column types in the raw data view of the Data Explorer, just under the grouping information.
Once you have your schema files ready to go, you can use the InfluxDB Cloud CLI tool to add that measurement schema to the bucket.
influx bucket-schema create --bucket usgs --name "earthquake" --columns-file ./schemas/earthquake-schema.ndjson --columns-format ndjson
ID Measurement Name Bucket ID
0808dd6fa216b000 earthquake 923f47af748a6453For full documentation of the command, you can use the -h option or check out our documentation. You can repeat the process to add additional measurement schemas to the same bucket. For this example, there are five measurements for the USGS data, and once they’re all added, you can verify them using the list command. If you need the full output, you can add the --json flag to the end of the command as well, which is also useful for automation.
influx bucket-schema list -n usgs
ID Measurement Name Bucket ID
0808dd50522a1000 chemical explosion 923f47af748a6453
0808dd6fa216b000 earthquake 923f47af748a6453
0808dd84f0551000 explosion 923f47af748a6453
0808dd96d876c000 ice quake 923f47af748a6453
0808ddaf8156a000 quarry blast 923f47af748a6453Writing data to an explicit schema bucket
Once the schemas are set up and ready to go, you can test that things are working by first trying to write some invalid line protocol to the bucket, to verify it is rejected.
influx write --bucket usgs "m,f=f1 v=1"
Error: failed to write data: 400 Bad Request: unable to parse 'm,f=f1 v=1': schema: measurement "m" not permitted by schemaThis verifies that incorrect data will get rejected from the bucket, but let’s write some data as well to make sure our schemas are correct. Then we can query to verify that data was written.
influx write -b usgs -u https://raw.githubusercontent.com/influxdata/influxdb2-sample-data/master/usgs-earthquake-data/all_week.lp
influx query 'from(bucket: "usgs") |> range(start: -1d) |> count() |> group() |> sum()'
Result: _result
Table: keys: []
_value:int
--------------------------
5076You might get a different number of results, but anything greater than zero means things are working.
As you start to write more data to the same bucket, you can add additional measurement schemas or update existing ones, as long as you are only adding tags or fields. You can’t edit a measurement schema in such a way that it invalidates the existing data in the bucket.
Conclusion
Using explicit bucket schemas can help protect your bucket against unwanted writes. Once you go through the process of creating the schema files, you can manage the bucket schemas quickly and easily using the latest influx CLI tooling. These explicit schemas are also compatible with InfluxDB Templates, so you can also manage these as part of your GitOps workflows.
If you have any questions or comments about explicit schema buckets, please join us on our Community Slack workspace or you can file issues directly in GitHub.
