Table of Contents
Have you started an InfluxDB project haphazardly? Have you created a database, but still don’t really understand the relationship between shard group duration and retention policies? Are you starting to recognize that you barely let yourself digest the documentation before trying to play with the tech? No? Fine then, maybe it’s just me who has trouble keeping my twitchy paws away from the keys.

As a new InfluxDB user, I want to avoid the most common stumbling blocks that others have encountered. This blog contains the most FAQ and some answers to guide us down the right path. Please be warned: a lot of these questions are open-ended. As a consequence, expect to find a list of considerations, resources, and questions that might inspire one (cough cough me) to go read the documentation closely.

Before we get started, please keep in mind that the good people at InfluxData already tried to help us. You can find all of the FAQs here. I also highly recommend looking at these TL;DR InfluxDB Tech Tips:
- InfluxQL Query Examples
- Query vs. Writing Booleans & Checking Field Types
- Identical Field Keys & Tag Keys, Existing Kapacitor TICKscripts in Chronograf & More
- InfluxQL Query Solutions on the SELECT Clause, Field Keys, and Selector Function
- Writing Historical Data, Setting Timestamp Precision in InfluxDB, and Finding Your Log Files
- Unwanted Series, Retention Policy, Bind Parameters
- Shard Group Duration Recommendations
- Convert Timestamps to Become Readable With InfluxDB's CLI
1) Why aren't my retention policies deleting my data?
This question suggests that the inexperienced user is unaware of one of two things: 1) what exactly retention policies are and 2) where to find the default settings.
If you find yourself in the first group, here’s an illustration that might help jog your memory. If you’re still confused, you might want to review shards and retention policies.
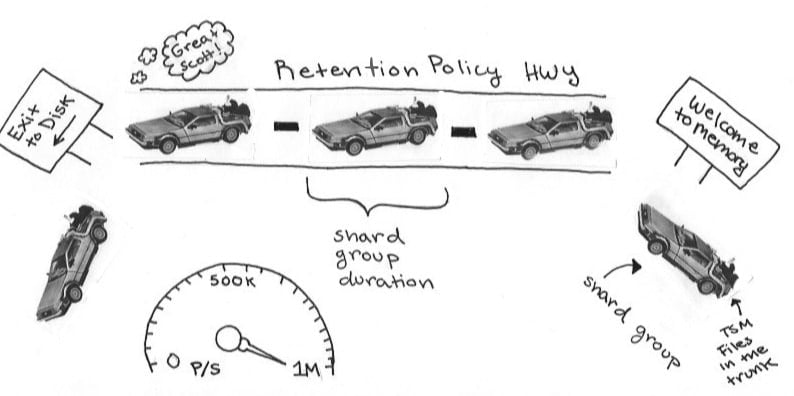
You’re onboard with shards and RP. You’re even following the shard group recommendations and best practices. Your shard group:
- duration is two times your longest typical query's time rangemakes sense. You're only interested in querying 4 days worth of traffic data today, but next week you discover that you're incredibly popular. You want to find out why the world finally gets you. You're grateful you gave yourself some query wiggle room by making your shard group duration twice as long.
- has at least 100,000 points per shard group
- has at least 1,000 points per series
Despite your knowledge, your data is still lingering! What gives? Well, maybe you didn’t configure your database properly. Existing shard groups and old RP’s could be messing you up. When you change a RP it only applies to shard groups moving forward. Before stressing, try allowing your old RP to expire. Also, you can’t drop a partial shard. If you changed your shard group duration, you might have to wait for your old shard to expire before seeing your changes in effect. Please be mindful of how InfluxDB defaults while you investigate these quandaries.
2) Why is InfluxDB using so much memory?
Let’s see…are you…
A. Looking at memory usage during a compression?
YES. Come back in a bit, usage will hopefully go down. Alternatively, if you are running InfluxDB on your local machine, do you know how many IOPS your disks can produce? Your machine might not be able to handle you.
B. Executing a poor query?
YES. “SELECT * FROM mydb.” is not a smart way to explore your schema, especially when dealing with high volume time series data. Try any one of these queries instead.
NEVER. You’re a star, you’re even running continuous queries to downsample your data. Tuning your Influx environment is tricky, especially without Enterprise level support. However, there are great tools that can allow you to monitor and tune your Influx environment. You’ve probably never heard of them. They’re called InfluxDB and Telegraf. Here’s a tutorial you can follow to do that.
I DON’T THINK SO. You’re right - your query might not be the problem. Rather take a look at your schema. You might have high cardinality (especially if you’re an Enterprise user).
InfluxDB can handle hundreds of thousands of unique tags in a normal dataset. If you’re on the OSS version and you have high cardinality (millions of unique measurements, tag sets, or field keys = high cardinality), your schema could be designed poorly.
For example, let’s say you want to create a database that contains financial time series data. A good schema design would include:
- One measurement ("financial_TS_data") containing tags and fields
- where the tags should include the instrument names ("APPL"),
- and the fields ("high", "open", "close", and "volume" ) contain the data itself.
Have you followed the recommendations for schema design?
3) How can I get human-readable timestamps returned to me?
Are your precision and epoch configurations good? Did you make sure that InfluxDB is returning timestamps in RFC3339 format? Alternatively, convert your timestamps in your preferred language before writing them to InfluxDB.
4) How to backup/restore?
I warned you that it would come up, so please just read this.
5) How does InfluxDB handle write/query loads?
- High performant*
- Write optimized (~750,000 p/s)
- Mostly AP, but also CP (CAP Theorem). Neither strictly both. Confused? Look at Jepsen's awesome review here.
- So much so that CERN used the OSS version to help them look for the Dog Particle? I don’t know, sounds right.

In reading this, I hope you feel a little bit more prepared to execute your time series projects. Let us know how it’s going by tweeting us @InfluxDB. Good luck!
