Use InfluxDB with GitHub Actions for GitOps, CI/CD, and Data Transformation
By
Russ Savage
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
GitHub Actions are a powerful way to add automation to any source code repository. When you take that power and connect it with InfluxDB, you get an amazing combination that allows you to automate data generation, manage GitOps workflows, and a whole lot more.
This post will highlight some of the interesting ways to use InfluxDB and GitHub Actions.
Introducing the InfluxDB GitHub Action
I’ve been playing around with GitHub Actions a ton lately and noticed that the marketplace was missing one for working with InfluxDB. So I decided to remedy that and create a new InfluxDB Action that anyone can use. The process was very simple, and the documentation to create new actions is robust.
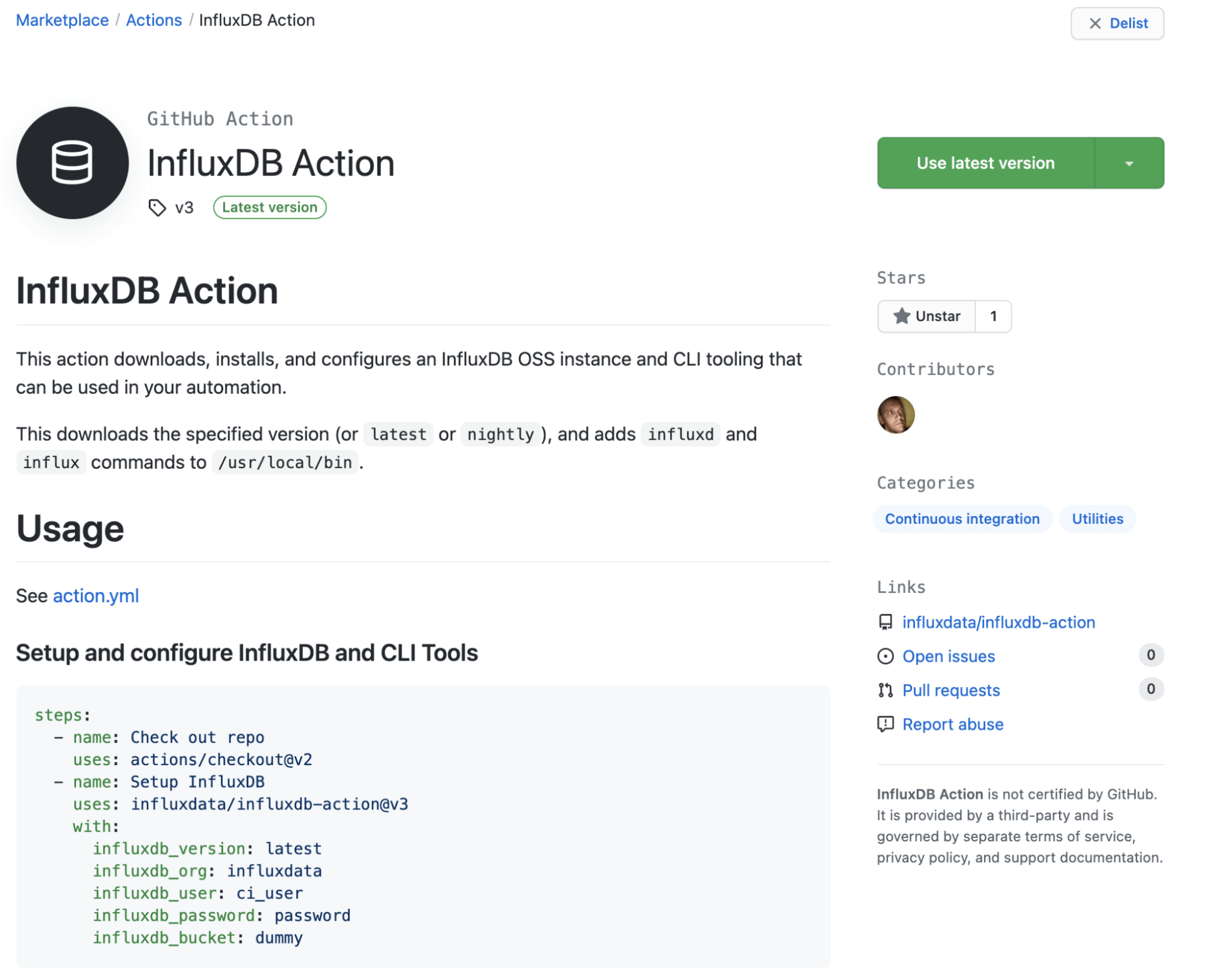
There are a few examples of how to set it up in the readme on the project. You can configure a specific version of InfluxDB, or use the keywords “latest” or “nightly” to always grab new versions (not recommended for production). The action will download InfluxDB and the InfluxDB CLI Tooling, unzip and move it into your path, then start and configure InfluxDB (unless you tell it not to). From there, you can run any influx command you would normally run.
So we have an InfluxDB instance up and running, but what can we do with it? Well, turns out, we can do a lot.
GitOps integrations
I’ve written previously about how to set up a GitOps workflow with InfluxDB, but with this GitHub action, it’s even easier. I’ve updated the version of the GitHub action configuration from that blog post to use the new InfluxDB Action.
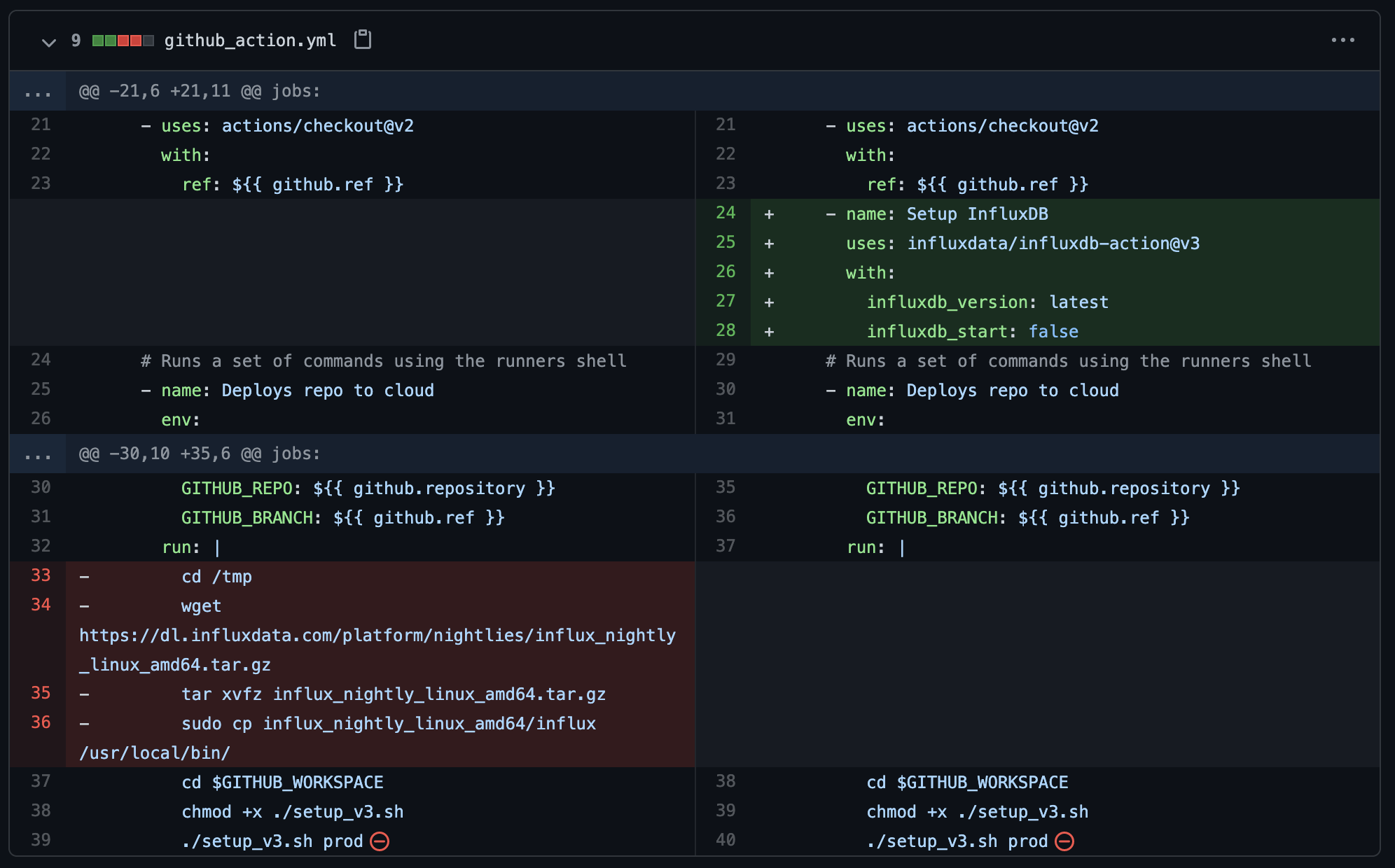
For these GitOps flows, I don’t need a local instance of InfluxDB running, since all I’m doing is using the CLI tooling to deploy resources into InfluxDB Cloud, so I’ve set influxdb_start: false on line 28. It moves the influx command into the path so I can leverage it as I normally would.
Another way the InfluxDB Action can help in your GitOps workflows is through validating that the changes you’ve made to your InfluxDB Template files are valid. We do this internally with our Community Templates repository, where all changes to a Template are validated by loading a local InfluxDB instance and installing the template. If the template installs without issue, then it is assumed to be correct, and the test passes. Check it out here in our Community Templates repository.

Data validation and conversion
Recently, I’ve been playing around with GitHub’s Flat Data project and looking for ways to leverage it for projects and demos. In a nutshell, GitHub Flat Data allows you to quickly configure a GitHub action to fetch and commit a public data feed into your GitHub repository at a regular interval. The example they use is Bitcoin data.
So I updated the InfluxDB Data Examples repository and started loading in some public data streams that I had used in the past, namely, NOAA National Buoy Data Center data and USGS Earthquake data.
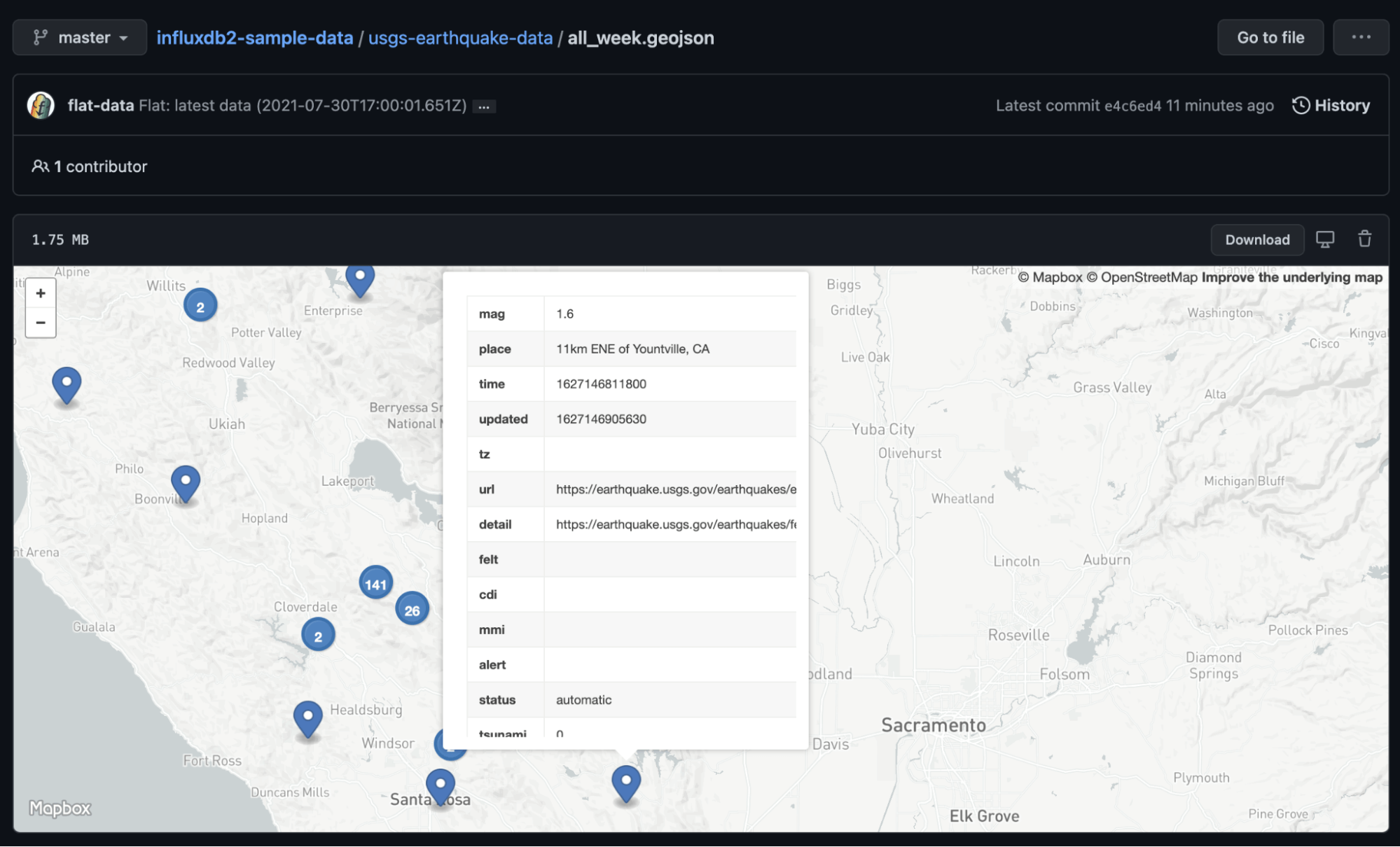
Next, I created a few post processing scripts to convert the data files into something that was usable for InfluxDB. For the buoy data, I enriched the data with the active station information and converted it into a CSV file, and for the Earthquake data, I converted it directly into line protocol.
Now that I had these data feeds regularly being updated and in a format that InfluxDB could read easily, I started playing around with using GitHub actions for doing some data conversions.
First, I grabbed the CSV file and used the InfluxDB command line interface (CLI) to parse and generate a line protocol version of the data. Here’s the command for converting that CSV data into line protocol.
/usr/local/bin/influx write dryrun -f $GITHUB_WORKSPACE/noaa-ndbc-data/latest-observations.csv --format csv --header "#constant measurement,ndbc" --header "#datatype double,double,double,double,double,double,long,double,double,double,double,double,double,double,tag,double,double,double,tag,tag,tag,tag,string,string,string,string,dateTime:number" > $GITHUB_WORKSPACE/noaa-ndbc-data/latest-observations.lpI’m using the dryrun command here to spit out the line protocol data to a file. Check out our documentation for more information and examples about parsing CSV data with the InfluxDB Command Line Tooling.
The line protocol data is helpful, but I didn’t see any Flux capabilities for reading it directly, so I wanted to convert that to Flux’s Annotated CSV format so that I could leverage the csv.from(url: "" capability to pull the data into my InfluxDB Cloud account.
The quickest way to do that is to just ingest the data into the InfluxDB OSS instance running in the background and then query it back out again into its own file.
/usr/local/bin/influx write -f $GITHUB_WORKSPACE/noaa-ndbc-data/latest-observations.lp -b dummy
/usr/local/bin/influx query "from(bucket: \"dummy\") |> range(start: -1y) |> drop(columns: [\"_start\",\"_stop\"])" --raw > $GITHUB_WORKSPACE/noaa-ndbc-data/latest-observations-annotated.csvThe range of 1y (one year) here is just a fake range since I know this data is all very recent.
Now, with this annotated CSV file, it’s really easy to pull that data into my InfluxDB Cloud account with the following query:
import "experimental/csv"
csv.from(url: "https://raw.githubusercontent.com/influxdata/influxdb2-sample-data/master/noaa-ndbc-data/latest-observations-annotated.csv")
|> filter(fn: (r) => r._field == "dewpoint_temp_degc")And visualize it with the Map graph type:
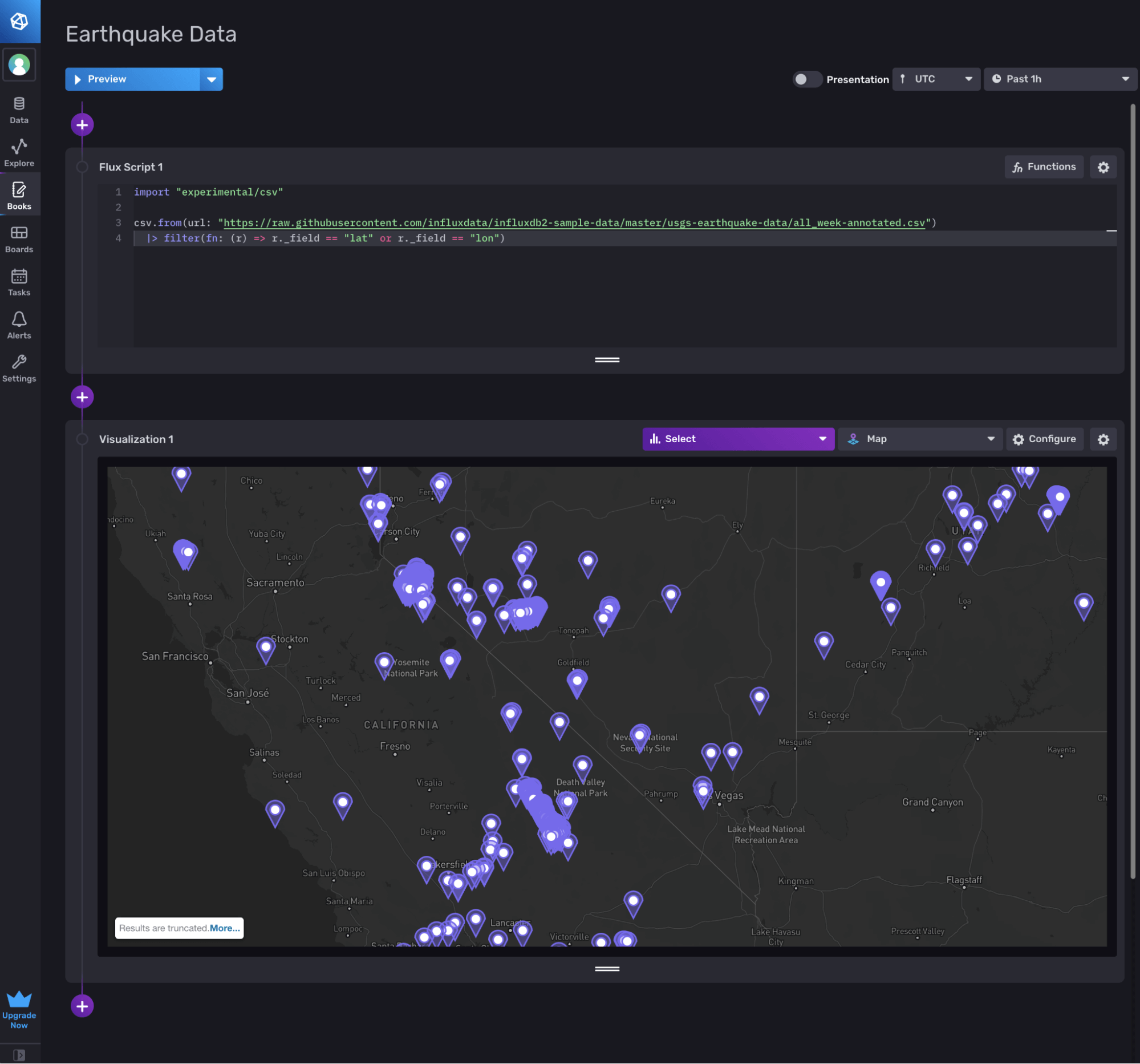
I did a similar thing for the USGS earthquake data.
This data is also now available in your InfluxDB Cloud instance using the new Sample Data library.
Conclusion
GitHub Actions are a powerful way to automate CI/CD pipelines for your projects, but it can also be used to automate data collection and transformation. We are using it internally in a variety of ways, and we’d love to hear how you’re using it.
Please join us on our Community Slack channel and let us know what you think!
