Table of Contents
InfluxDB clustering is available as part of InfluxData’s commercial product offered in both managed and self-managed capacities.
Architectural overview
An InfluxDB Enterprise installation (the latest at the time of writing is v.1.8.2) allows for a clustered InfluxDB installation which consists of two separate software processes: data nodes and meta nodes. To run an InfluxDB cluster, both the meta and data nodes are required.
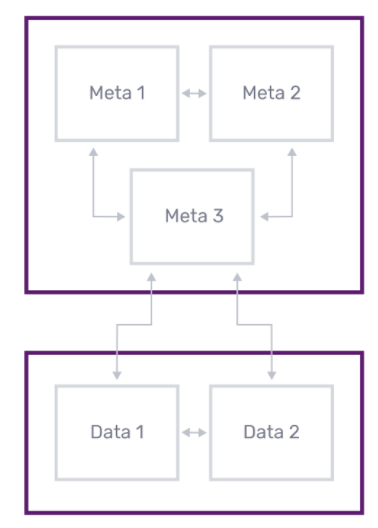
The meta nodes expose an HTTP API that the influxd-ctl command uses. This command is what system operators use to perform operations on the cluster like adding and removing servers, moving shards (large blocks of data) around a cluster and other administrative tasks. They communicate with each other through a TCP Protobuf protocol and a Raft consensus group.
Data nodes communicate with each other through a TCP and Protobuf protocol. Within a cluster, all meta nodes must communicate with all other meta nodes. All data nodes must communicate with all other data nodes and all meta nodes.
The meta nodes keep a consistent view of the metadata that describes the cluster. The meta-cluster uses the HashiCorp implementation of Raft as the underlying consensus protocol. This is the same implementation that they use in Consul. The meta nodes can run on very modestly sized VMs (t2-micro is sufficient in most cases).
The data nodes replicate data and query each other via a Protobuf protocol over TCP. Details on replication and querying are covered in the documentation. Data nodes are responsible for handling all writes and queries. Sizing is dependent on your schema and your write and query load.
Optimal server counts
For optimal InfluxDB Clustering, you’ll need to choose how many meta and data nodes to configure and connect. You can think of InfluxDB Enterprise as two separate clusters that communicate with each other: a cluster of meta nodes and a cluster of data nodes.
Meta nodes: The magic number is 3!
The number of meta nodes is driven by the number of meta node failures they need to be able to handle, while the number of data nodes scales based on your storage and query needs.
The consensus protocol requires a quorum to perform any operation, so there should always be an odd number of meta nodes. For almost all use cases, 3 meta nodes is the correct number, and such a cluster will operate normally even with the loss of 1 meta node. Losing a second node means the remaining two nodes can only gather two votes out of a possible four, which does not achieve a majority consensus. Since a cluster of 3 meta nodes can also survive the loss of a single meta node, adding the fourth node achieves no extra redundancy and only complicates cluster maintenance. At higher numbers of meta nodes, the communication overhead increases exponentially, so a configuration of 5 meta nodes is likely the max you’d ever want to have.
Data nodes: based on scalability requirements
Data nodes hold the actual time series data. The minimum number of data nodes to run is 1 and can scale up from there. You always want to run a number of data nodes that is evenly divisible by your replication factor. For instance, if you have a replication factor of 2, you’ll want to run a node count of 2, 4, 6, 8, 10, etc.
As a rule of thumb: InfluxDB clustering should have 3 meta nodes with an even number of data nodes.
InfluxDB clustering and where data lives
The meta and data nodes are each responsible for different parts of the database.
Meta nodes: Meta nodes hold all of the following meta data:
- all nodes in the cluster and their role
- all databases and retention policies that exist in the cluster
- all shards and shard groups, and on what nodes they exist
- cluster users and their permissions
- all continuous queries
Data nodes: Data nodes hold all of the raw time series data and metadata, including:
- measurements
- tag keys and values
- field keys and values
Further steps:
- Try out our InfluxDB clustering solution by either starting an InfluxDB Cloud or InfluxDB Enterprise Trial.
- Read the documentation on Clustering
- Learn about the features and usage of InfluxDB Cloud and InfluxDB Enterprise.
