Welcome to InfluxDB IOx: InfluxData’s New Storage Engine
By
Paul Dix
updated October 20, 2023
Product
Use Cases
Navigate to:
Two years ago I announced that InfluxData was working on a new core for InfluxDB, a project we named InfluxDB IOx. InfluxDB IOx is a cloud-native, real-time, columnar database optimized for time series data built in Rust on top of Apache Arrow and DataFusion. Today I’m excited to announce that we deployed our next-generation storage engine that’s built on InfluxDB IOx in our InfluxDB Cloud platform. The new storage engine is a massive leap forward for our core database technology, with the removal of cardinality limits so users can bring in massive amounts of time series data with unlimited scale, SQL query capabilities, tiered data storage, and fast analytical queries. In this post I’ll highlight some of the core technology choices and the exciting features coming in the near future that InfluxDB enables.
A new InfluxDB
Today’s announcement represents the largest leap forward for InfluxDB since we introduced our TSM storage engine in 2016. At that time, we built a storage engine optimized for what our users most wanted from InfluxDB: fast performance for ingesting and querying metrics data. However, we’ve always had the vision that InfluxDB should be useful for event data (i.e. irregular time series) as well as metric data (i.e. regular time series). The new storage engine represents the next phase of InfluxDB’s life where we bring metric data and event data time series into a single database core, giving users the ability to create time series on the fly from raw, high-precision event data.
When we first started thinking about rebuilding the core of InfluxDB in early 2020, we also thought about what technologies we’d use. InfluxDB originally started in 2013 and there have been many exciting developments since then. We decided the new core should be built in Rust because of its many advantages with high-performance systems software. We also decided to build it around the Apache Arrow ecosystem for greater interoperability and collaboration with a much wider group of developers. Both of those bets from two and a half years ago worked out very well as both the Rust and Arrow projects matured and gathered momentum in the time since. We’re happy to be contributing extensively to Arrow to help drive it forward as the building block for new data and analytics projects of all kinds.
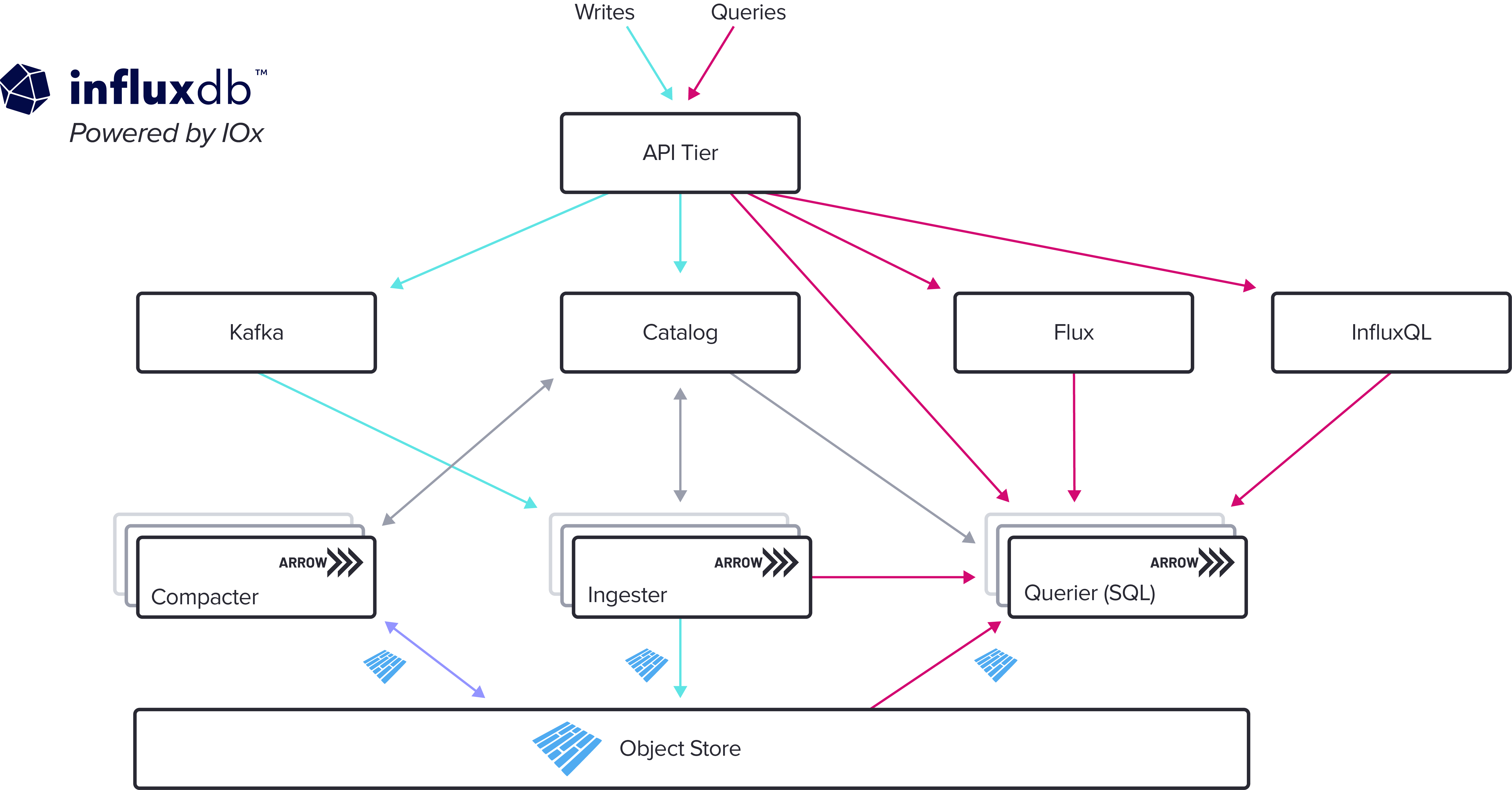
Unbounded cardinality, SQL, and real-time analytics
InfluxDB Cloud customers using the new storage engine have their cardinality limits lifted completely. Users can write any kind of event data with infinite cardinality and slice-and-dice data on any dimension without sacrificing performance. This opens up use cases such as events, tracing, and all sorts of ephemeral unbounded cardinality data.
The engine’s support for high cardinality isn’t just limited to ingestion. Queries that touch many time series are orders of magnitude faster in IOx than in our previous versions of InfluxDB. Querying across 10 series or 1 million series is all the same. This makes analytics across high-cardinality data possible.
IOx supports SQL natively and our cloud customers can connect using Postgres-compatible clients like psql, Grafana’s Postgres data source, and BI tools like PowerBI and Tableau. We will also be rolling out Apache Arrow FlightSQL as the standard matures, giving users high- performance access to millions of rows of time series data.
Coming soon
The new storage engine represents an advanced core that we intend to build many new features on top of. Bulk data ingest, bulk data export, and integrations with other third-party systems are all planned for the near future. We’ll also be launching dedicated cloud tiers and a new on-premises Enterprise product based on IOx.
We’re very excited about this release today as it represents years of hard work and effort. To take advantage of all these advancements, sign up here.
