Table of Contents
Hopefully, you caught Part 1 of this series. If you didn’t, don’t read any of the spoilers below and check out Part 1 here. All caught up? Good! Let’s move on.
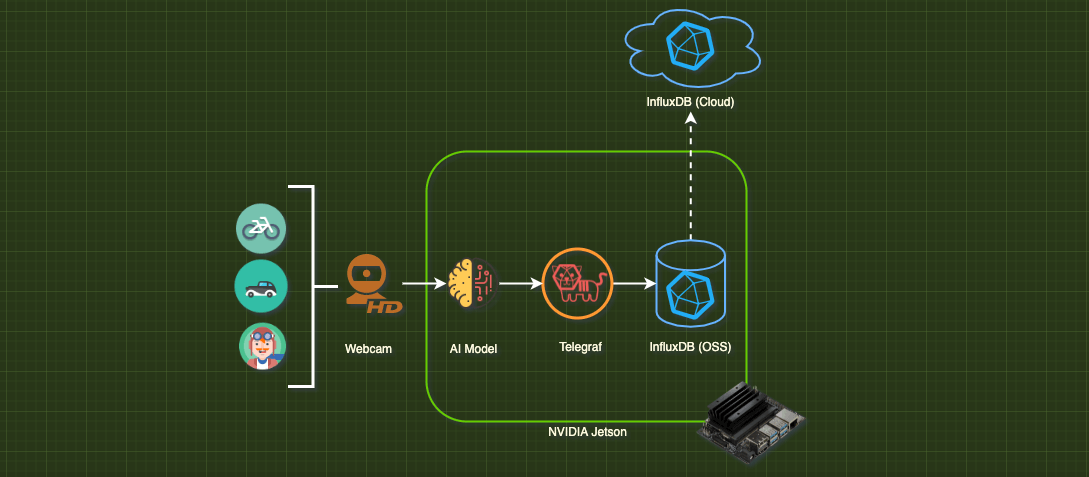
In Part 2, our goal is to build a Vision AI Pipeline that can be used as part of a do-it-yourself home security system. Here is the plan:
NVIDIA DeepStream
So what is NVIDIA DeepStream?
In its simplest form, NVIDIA DeepStream is essentially a series of GStreamer (Click here for my summary of Gstreamer) elements that have been optimized to make use of NVIDIA GPU acceleration.
As well as GPU acceleration, NVIDIA has provided an ecosystem of Vision analytics (Tensor RT) and IoT plugins (MQTT, Kafka) that abstract you from learning base libraries and systems. This is not to say developing a Vision AI solution is a walk in the park. Hopefully, this guide will show how InfluxDB and Telegraf can be used to accelerate your development of complex solutions such as this.
Vision AI Pipeline
Now that you have enough background knowledge to be dangerous, let’s take a look at our vision pipeline. I am going to break it down into two diagrams:
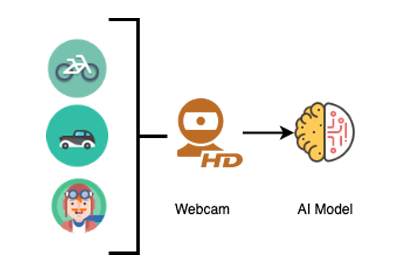
For this solution, we will be using a USB webcam attached to our NVIDIA Jetson. Our Vision AI Pipeline will ingest the raw frames produced by the USB webcam and feed them through an object detection model. The model is trained to detect four categories: people, cars, bikes and road signs. The produced inference results are then used within two parallel output plugins:
- RTSP (Real-Time Streaming Protocol) Server: This allows us to send our video frames to a network-accessible endpoint, which means we can remotely monitor the output from the webcam. The RTSP Protocol has commonly been used within CCTV (closed-circuit television) architectures.
- MQTT Client: In short the MQTT client allows us to send our detection results (otherwise known as inference results) to Telegraf and to InfluxDB for further analytics. We will discuss this in further detail later.
So what does our Vision AI pipeline look like in GStreamer components?
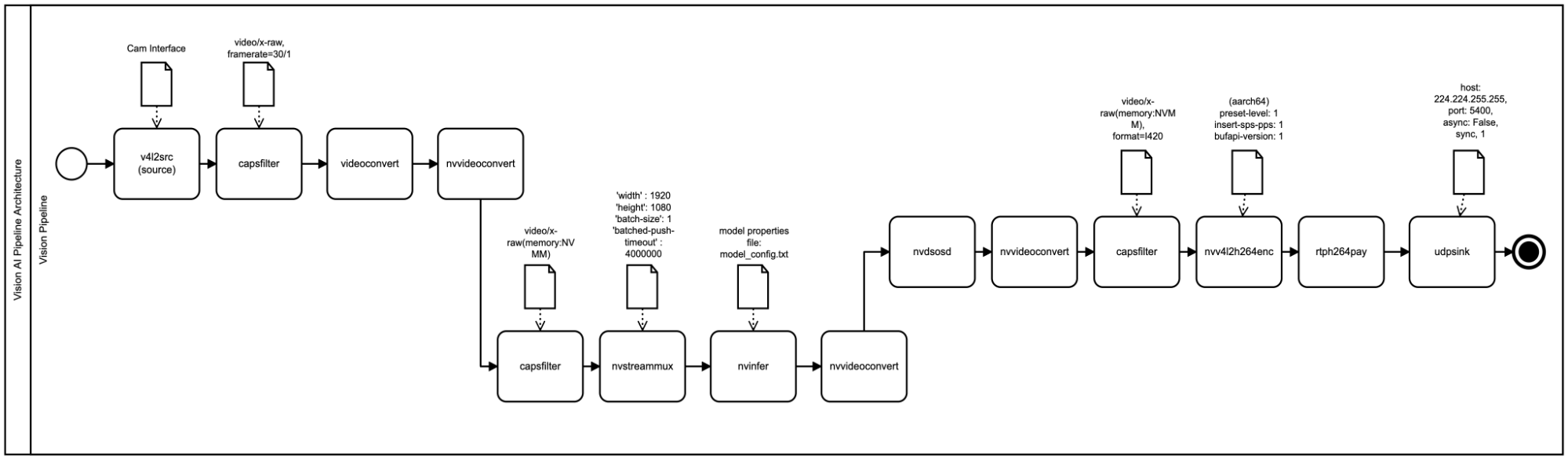
Feels like a lot right? If you want to learn more, check out my deep dive document here.
The inference engine and model
So what is an inference engine and model?
- Inference Engine - provides the necessary functions and optimizations for running a neural network on our chosen device (CPU, GPU, etc.). An inference engine's API provides simplified methods for interfacing with your model such as inputting frames for processing and producing the output tensor.
- Model - Our model is essentially a pre-trained neural network. In traditional programming, we provide the rules for our algorithms to act upon to generate an answer (if it has four legs and barks then equals dog). Neural networks are provided with the input data and the answers and deduce their own rules for achieving the answer.
In our solution, the NVinfer plugin does most of the heavy lifting when it comes to model deployment. NVinfer features include:
- Optimization - NVinfer will automatically optimize model frameworks (Caffe, UFF and ONNX) using the TensorRT library.
- Transformation - NVinfer ensures that frames are scaled and transformed appropriately based on the input requirements of the model.
- Processing - NVinfer deploys the TensorRT inference engine which runs our optimized model. This produces a meta containing the prediction results of the model. The TensorRT engine supports multi-class object detection, multi-label classification and segmentation).
If you want more information on the TensorRT engine, I highly recommend you check out this blog on Medium.
Pipeline code
The code is pretty lengthy, so I won’t go through it all in this blog. For the full code, check out my repo.
Note: A fair chunk of the code comes from NVIDIA DeepStream examples which can be found here. My demo is based on version 5.1, so please note that when 6.0 releases it may contain breaking changes.
My aim was to improve the readability and overall modularity of the code, as we will be extending to include our own data model for Telegraf and InfluxDB. I have created a class diagram and highlighted some of the core mechanics of the pipeline here.
Telegraf and InfluxDB
Our pipeline is currently processing image frames from our webcam, running them through our detection model and producing a network stream of the results. It’s great if you can watch the stream 24 hours a day. So how do we collect our inference results and use them within a wider solution? Telegraf and InfluxDB pretty much provide everything we need out of the box. Let’s take a look:
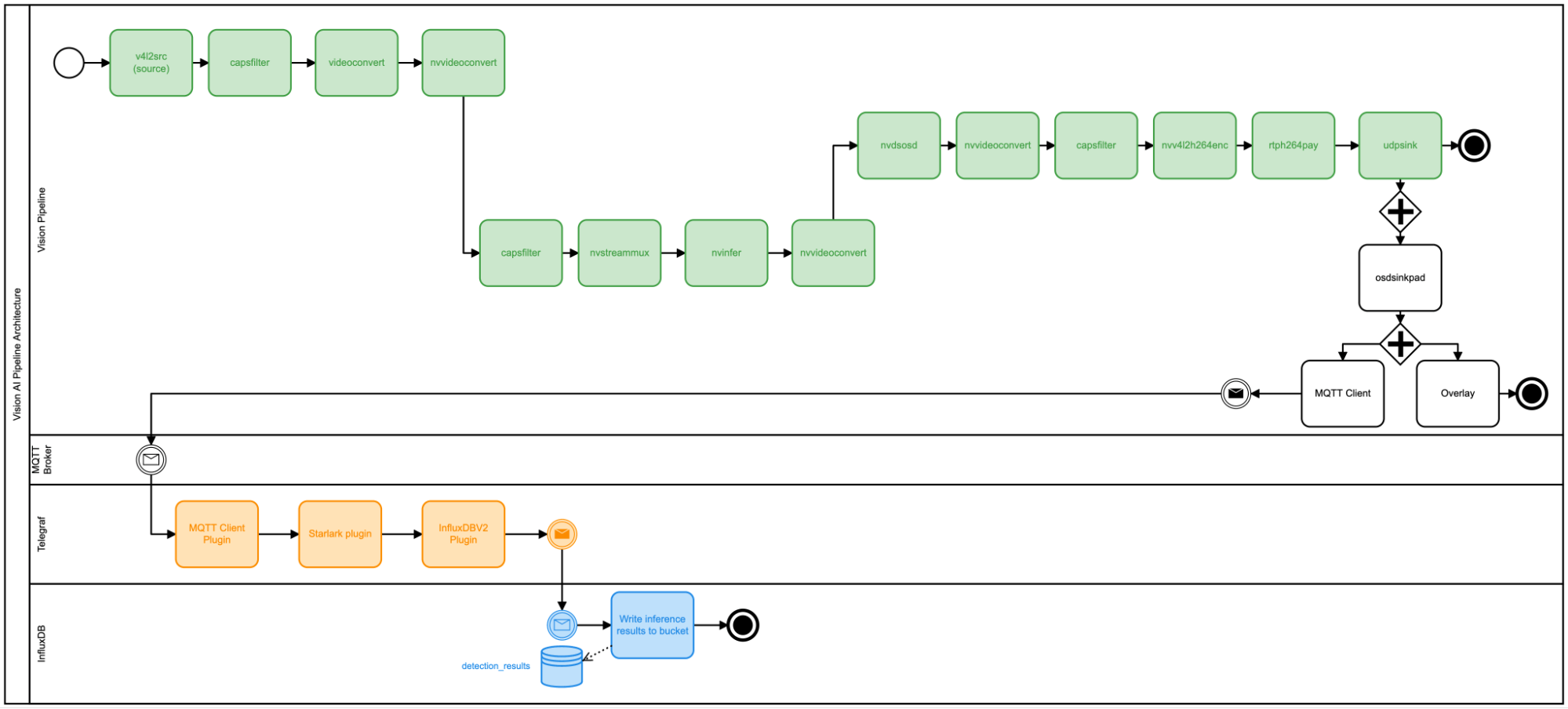
MQTT Client
There were two options I could have taken here:
- Write the data directly to InfluxDB using the Python Client Library
- Write the data to a generic protocol and use Telegraf to ingest the data
The pro’s of option 1 is that we have one less solution component to maintain. We also gain a strong level of control over when and how we send data to InfluxDB. The downside is that we reduce the interoperability of our solution. Telegraf provides a huge level of scope for sending our inference results to so many other systems. I opted for option 2, we already use Telegraf to collect our Jetson Stats so we would simply add another input plugin to this Telegraf instance.
Implementation
I opted to use the Paho MQTT Client, as the library is extremely easy to configure and is a well- supported Eclipse project. I decided to create a mqtt_client class for initialization:
class mqtt_client:
def __init__(self, address, port, clientID) -> None:
self.mqttBroker = address
self.port = port
self.clientID = clientID
self.client = None
def connect_client(self):
MQTT_KEEPALIVE_INTERVAL = 45
self.client = mqtt.Client(self.clientID)
self.client.connect(host=self.mqttBroker,port=self.port, keepalive=MQTT_KEEPALIVE_INTERVAL)
def connect_client_secure(self, username, password):
MQTT_KEEPALIVE_INTERVAL = 60
self.client = mqtt.Client(self.clientID)
self.client.connect(host=self.mqttBroker,port=self.port, keepalive=MQTT_KEEPALIVE_INTERVAL)
self.client = mqtt.Client(self.clientID)
self.client.connect(self.mqttBroker)
self.client.tls_set() # <--- even without arguments
self.client.username_pw_set(username=username, password=password)
def publish_to_topic(self, topic: str, data: dict):
message = json.dumps(data)
self.client.publish(topic, message)We then initialize the MQTT connection within osd_sink_pad_buffer_probe function (inference_results.py):
try:
mqttClient = mqtt_client("localhost", 1883 , "Inference_results")
mqttClient.connect_client()
except:
print("could not connect to MQTT Broker")
BROKER_CONNECT = FalseThe inference results are sent during the l_frame loop. Note a few things here:
- We conditionally only send results every 30 frames. Since our webcam produces 30 frames per second, it does not make sense to report on each frame since most objects will not have changed within 1 second.
- Our metadata is saved based upon the INFERENCE data structure we have created. We will discuss this next.
Note: You may be wondering why I did not decide to use the nvmsgbroker plugin. This was a personal preference as I wanted more control over the data structure we were providing to Telegraf. The same results can be achieved but with more work required in Starlark.
Broker
To keep things simple I installed the Eclipse Mosquitto MQTT broker directly on my Jetson device. Here are the install instructions:
sudo apt-get update
sudo apt-get install mosquitto
sudo systemctl enable mosquitto
sudo systemctl start mosquittoThis will install Mosquitto as a service on your device. We then use systemctl enable to make sure the broker boots on device startup.
Note: This configures the broker into its default insecure state on port 1883. Consult the Mosquitto documentation for further information on configuration.
Data model
As discussed previously, writing our own MQTT client gives flexibility over the data model we deliver. Here is a sample using the custom model:
{
"detection_frame_number":2280,
"total_num_obj":1,
"inference_results":[
{
"classID":2,
"label":"Person",
"confidence":0.67747300267219543,
"coor_left":1303.7781982421875,
"coor_top":139.6199951171875,
"box_width":467.4754943847656,
"box_height":937.4452514648438,
"objectID":18446744073709551615,
"unique_com_id":"OBJ1"
}
]
}Let’s break it down:
- detection_frame _number - Tells us the frame number for which the detection was taken. Frame number resets if the application restarts.
- total_num_obj - total number of objects detected by the model
- Inference_results - An array that holds an object for each detection in the current frame. Each object contains the following:
- classID - unique identifier for the detection classification (1 = car, 2 = person).
- label - human-readable version of the classID
- confidence - a numerical value between 0 and 1 containing a percentage of how confident the model is in its detection (0.6 = 60%)
- coor_left - the distance between the left edge of the frame and the top left corner of the bounding box.
- coor_top - the distance between the top edge of the frame and the top left corner of the bounding box.
- box_width - the width of the bounding box from the left point to the right point.
- box_height - the length of the bounding box from top point to bottom point.
- objectID - this will become important if you introduce a tracker. A unique identifier for each object.
- Unique_com_id - since we are not using a tracker, the objectID produced is equivalent for all detections. I introduced this field to distinguish between detections.
So you may be wondering in the current data structure how we distinguish the different parallel detections at a given time interval. InfluxDB would simply overwrite the field. Read on to see how in the Telegraf section.
Telegraf
So we have our MQTT Client publishing samples based on the custom data model to the MQTT Broker. The next step is getting the data into InfluxDB:

Input Plugin: MQTT_Consumer
The config for our ingest plugin is pretty simple:
alias = "vision_pipeline"
interval = "5s"
name_override = "BW_Inference_results"
servers = ["tcp://localhost:1883"]
topics = [
"inference"
]
qos = 2
connection_timeout = "30s"
client_id = "1"
data_format = "json_v2"
[[inputs.mqtt_consumer.json_v2]]
[[inputs.mqtt_consumer.json_v2.object]]
path = "@this"
disable_prepend_keys = trueMost of the above plugin settings speak for themselves. If you want to learn more about them, then check out the plugin readme. What I did want to cover is the json_v2 parser. I have seen this surface in the community quite a bit. In this case, @this represents the topmost layer of our JSON object. disable_prepend_keys will prevent any of the field names from heading their parent names. Here is an example of converting the parsed JSON to line protocol:
JSON:
{'detection_frame_number': 0, 'total_num_obj': 2, 'inference_results': [{'classID': 0, 'label': 'Car', 'confidence': 0.40576171875, 'coor_left': 650.953125, 'coor_top': 361.28204345703125, 'box_width': 171.03515625, 'box_height': 190.78953552246094, 'objectID': 18446744073709551615, 'unique_com_id': 'OBJ1'}, {'classID': 0, 'label': 'Car', 'confidence': 0.2666015625, 'coor_left': 977.8388671875, 'coor_top': 512.3947143554688, 'box_width': 249.580078125, 'box_height': 259.200927734375, 'objectID': 18446744073709551615, 'unique_com_id': 'OBJ2'}]}Line Protocol:
BW_Inference_results,host=jetson-desktop,topic=inference detection_frame_number=0,total_num_obj=2,classID=0,label="Car",confidence=0.40576171875,coor_left=650.953125,coor_top=361.28204345703125,box_width=171.03515625,box_height=190.78953552246094,objectID=18446744073709552000,unique_com_id="OBJ1" 1635940856224413650
BW_Inference_results,host=jetson-desktop,topic=inference detection_frame_number=0,total_num_obj=2,classID=0,label="Car",confidence=0.2666015625,coor_left=977.8388671875,coor_top=512.3947143554688,box_width=249.580078125,box_height=259.200927734375,objectID=18446744073709552000,unique_com_id="OBJ2" 1635940856224413650As you can see the above JSON sample produced two line protocol entries with the exact same timestamp. One for OBJ1 and the second for OBJ2. This presents a problem as OBJ2 will overwrite OBJ1 when written to InfluxDB2. We can fix this with a processor plugin.
Processor Plugin: Starlark
Starlark is a Python-like scripting language that allows you to manipulate metrics in realtime. This could be anything from performing custom calculations to converting timestamps (check out this great blog for more information). In our case, we will use Starlark to add a tag to our metric which will act as a unique identifier:
[[processors.starlark]]
namepass = ["BW_Inference_results"]
source = '''
def apply(metric):
v = metric.fields.get('unique_com_id')
if v == None:
return metric
metric.tags['obj'] = v
return metric
'''Breakdown:
- namepass - we will cover this in routing.
- source - This parameter expects a Starlark script. Our script takes the incoming metric as input and stores the value in unique_com_id field in v (OBJ1, OBJ2, etc.). If the value returned is none (no detections), we simply return the metric as this is a valid result. Otherwise, we create a new tag called obj and assign in it the value stored in v. We then return the modified metric.
Here is our metric after being passed through our script:
BW_Inference_results,host=jetson-desktop,obj=OBJ1,topic=inference detection_frame_number=0,total_num_obj=2,classID=0,label="Car",confidence=0.40576171875,coor_left=650.953125,coor_top=361.28204345703125,box_width=171.03515625,box_height=190.78953552246094,objectID=18446744073709552000,unique_com_id="OBJ1" 1635940856224413650
BW_Inference_results,host=jetson-desktop,obj=OBJ2,topic=inference detection_frame_number=0,total_num_obj=2,classID=0,label="Car",confidence=0.2666015625,coor_left=977.8388671875,coor_top=512.3947143554688,box_width=249.580078125,box_height=259.200927734375,objectID=18446744073709552000,unique_com_id="OBJ2" 1635940856224413650As you can see, the new tag has been applied to each metric thus making them unique entries.
Output Plugin: InfluxDB2
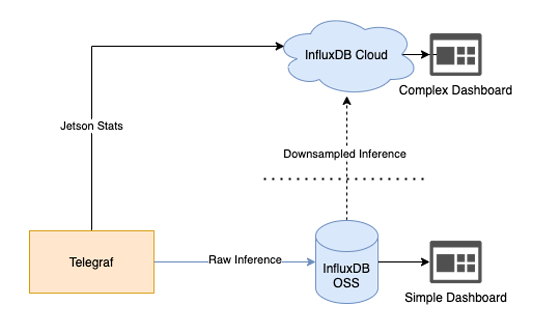
We discussed the configuration in Part 1 of The Jetson Series. The main point to consider is an architecture change. Since we will be receiving at least one sample a second, I thought it best to run an edge instance of InfluxDB to store my inference results. This is located directly on my Jetson device. From there we can downsample our data and send it to the cloud for more intensive calculations:
[[outputs.influxdb_v2]]
alias = "edge_inference"
namepass = ["BW_Inference_results"]
urls = ["http://localhost:8086"]
token = ""
organization = "Jetson"
bucket = "edge_inference"Routing
As we know, there are currently two unique data streams being processed through Telegraf:
- Jetson Stats
- Inference Results
The problem is we do not want our Jetson Stat results being processed through our Starlark Plugin, and we don’t want our raw inference samples heading to the cloud.
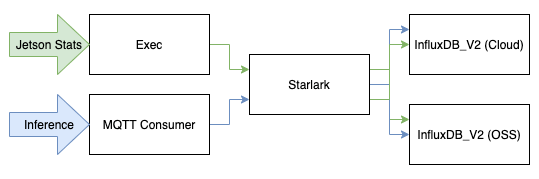
Luckily, you can deploy routing features in Telegraf called pass and drop. Pass and drop can either be applied at a measurement (name), tag (tag) or field level (tag). In our case, we only need routing from the highest level (measurement) so we use namepass and namedrop.
Namepass
Since we only expect one type of measurement (BW_Inference_results) to pass through our Starlark plugin, the namepass plugin is a good choice for us:
[[processors.starlark]]
namepass = ["BW_Inference_results"]The above config will only allow measurements with the name BW_Inference_results into the Starlark Plugin. We also apply the same namepass to our InfluxDB_v2 (OSS) Plugin.
Namedrop
Now it might be the case that we only want to block a specific measurement (BW_Inference_results) to pass through a plugin and let the rest process as normal. We can use namedrop to block BW_Inference_results from reaching the cloud:
[[outputs.influxdb_v2]]
namedrop = ["BW_Inference_results"]The above config will drop all measurements with the name BW_Inference_results before they reach the InfluxDB_v2 (Cloud) plugin.
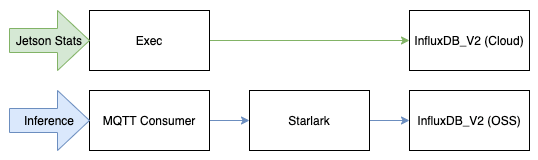
InfluxDB
We are now ingesting inference metrics into InfluxDB. There are two goals we want to reach:
- Simple dashboarding for our raw inference data
- Downsampling and transmission to our cloud instance
Dashboarding
As we did in Part 1 of this series, we will install the dashboard via a template found here. If you need a reminder on how to do this, check back to section InfluxDB Cloud in Part 1.
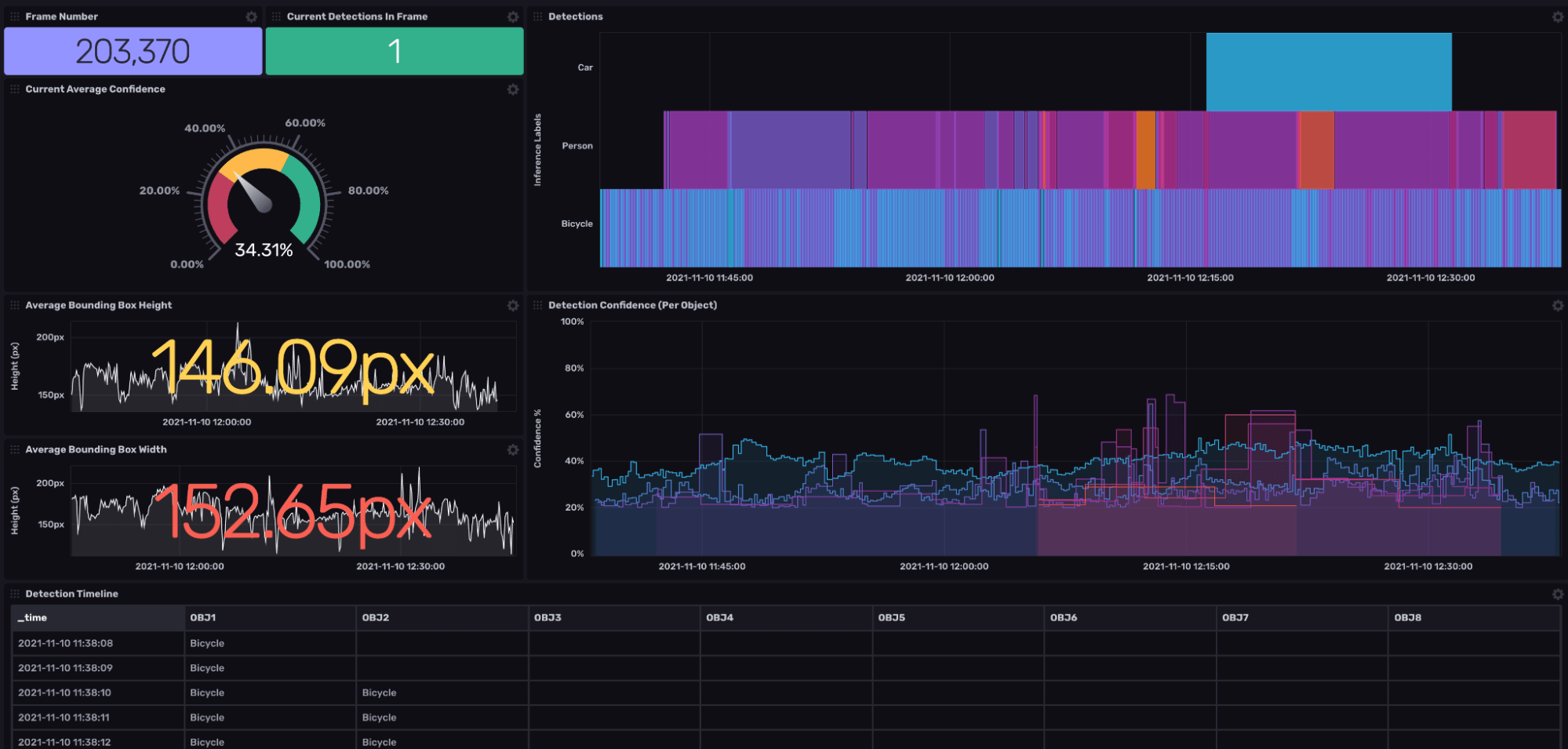
Once imported, your dashboard will look similar to the above dashboard. Let’s take a whistle-stop tour:
- Frame Number & Current Total Detect - Single value cells which display the last known frame number and the total amount of objects detected.
- Average confidence - This performs a mean aggregation over all samples (does not consider tags). From there I perform a map() function to multiply the average by 100 to give us a human-readable percentage.
- Timeline - Takes the detection label and performs a pivot() on the tag columns (OBJ 1, OBJ2, etc.) This provides us with a timeline of what objects were detected at what time.
- Detection State Changes - This makes use of our mosaic tile. It keeps track of object state changes by detecting how long an object was a certain type. As we can see, the majority of car detections OBJ 1 is denoted by the purple bar.
- Bounding Box Width & Height - These graphs don't tell us much except the average height and width of our objects over time. I chose to leave them in to show that not all raw data makes for good visual data. We will be doing further processing of this data in the cloud to provide more interesting insights.
Downsampling and RemoteTo
The last task on our list is to transform our solution from an edge and cloud solution to a hybrid of both. Why would we want to do this?
Answer: Our Edge device simply can’t handle the extra workload. It’s already running our pipeline, broker, Telegraf and local InfluxDB instance. That’s quite a bit of work for an entry-level arm processor (excluding the pipeline components running on the GPU). Plus, our visibility to the local dashboard is only accessible on our local network unless we expose this endpoint to the greater WAN.
To achieve our hybrid, we need to deploy two Flux features via a Task (I will not cover tasks in-depth, but check out the docs to learn more):
- Downsample
- RemoteTo (officially known as the experimental.to() function with the added feature of remote support)
Here is the task:
import "experimental"
import "influxdata/influxdb/secrets"
option task = {
name: "edge_to_cloud",
every: 1h,
offset: 0s,
}
from(bucket: "edge_inference")
|> range(start: -1h)
|> filter(fn: (r) => r["_measurement"] == "BW_Inference_results")
|> aggregateWindow(every: 10m, fn: last, createEmpty: false)
|> pivot(rowKey: ["_time"], columnKey: ["_field"], valueColumn: "_value")
|> drop(columns: ["_start", "_stop"])
|> group(columns: ["_measurement", "obj"], mode: "by")
|> experimental.to(
bucketID: "13dd5e3bc3998a75",
orgID: "05ea551cd21fb6e4",
host: "https://us-east-1-1.aws.cloud2.influxdata.com",
token: secrets.get(key: "cloud"),
)The above task runs on the hour and performs the following operations:
- Queries the edge_inference bucket for the last hour's worth of data.
- Aggregates the data to 10-minute intervals and selects the last non-null value for that interval.
- We then pivot by the _field column. This turns our fields into columns based upon the time entry. To learn more about pivot, check out this blog.
- We then group by our measurement and tag columns. This is a structural requirement of experimental.to().
- Now the interesting part. We use experimental.to() to send our downstream table to the cloud instance. To do this, you require the following parameters; bucket/bucketID, org/orgID, host and token (check out the secret store docs). Note that parameter names differ when using ID's over names.
There we have it! We have downsampled data being offloaded to our cloud instance for further processing. I shall leave you waiting till Part 3 for some interesting Flux transformation.
Conclusion
That was a lot! But as most of us know that architecting and creating IoT projects from the ground up is a huge task upon which many companies build their entire businesses. What we have learned here is that through the combination of three open source projects (NVIDIA DeepStream, Telegraf, and InfluxDB), you can accelerate your time to awesome!
I hope this blog gives you the confidence to jump in at the deep end and start to experiment with Vision AI. The field will only improve if more talented individuals with domain-specific knowledge get involved.
Once you get up and running, reach out to me on the InfluxData Slack and Community forums (just make sure to tag me @Jay Clifford). Let’s continue the chat!
