Table of Contents
If you’re an InfluxDB user you’ve almost certainly used the aggregateWindow() function. The aggregateWindow() function calculates an aggregated value by applying a mean, sum, or any other aggregate function to fixed windows of time. It’s most commonly used to downsample your data or to create materialized views of your data. Some new optimizations have been added to this function to make it even more performant.
Previously the aggregateWindow() function wasn’t performant enough for users who:
- Are querying large amounts of data
- Have high cardinality data
- Want to group like series together before calculating the aggregate to calculate the aggregate across multiple series
Pushdown patterns and native Go
Flux is able to query data efficiently because some functions push down the data transformation workload to storage rather than performing the transformations in memory. Combinations of functions that do this work are called pushdown patterns. Previously only the from() |> range() |> filter() |> aggregateWindow() was a pushdown pattern. Now from() |> range() |> filter() |> group() |> aggregateWindow() is also a pushdown pattern, which means that:
- It’s more performant
- You can now group like series before applying the aggregateWindow() function and calculate aggregations across multiple series with ease.
Previously the aggregateWindow() function was written in Flux. Now it’s implemented in native Go for specific functions. This change means that the aggregateWindow() function will be even more performant if you’re using it to calculate the following aggregations:
- mean
- sum
- count
- (min and max are expected to land shortly)
Please note: To gain even more performance from the aggregateWindow() function, make sure to set the createEmpty option to false. The createEmpty option is set to true by default which creates empty windows of time.
The performance of aggregateWindow() was tested against 50,000 points with a cardinality of 50, and here were the results:
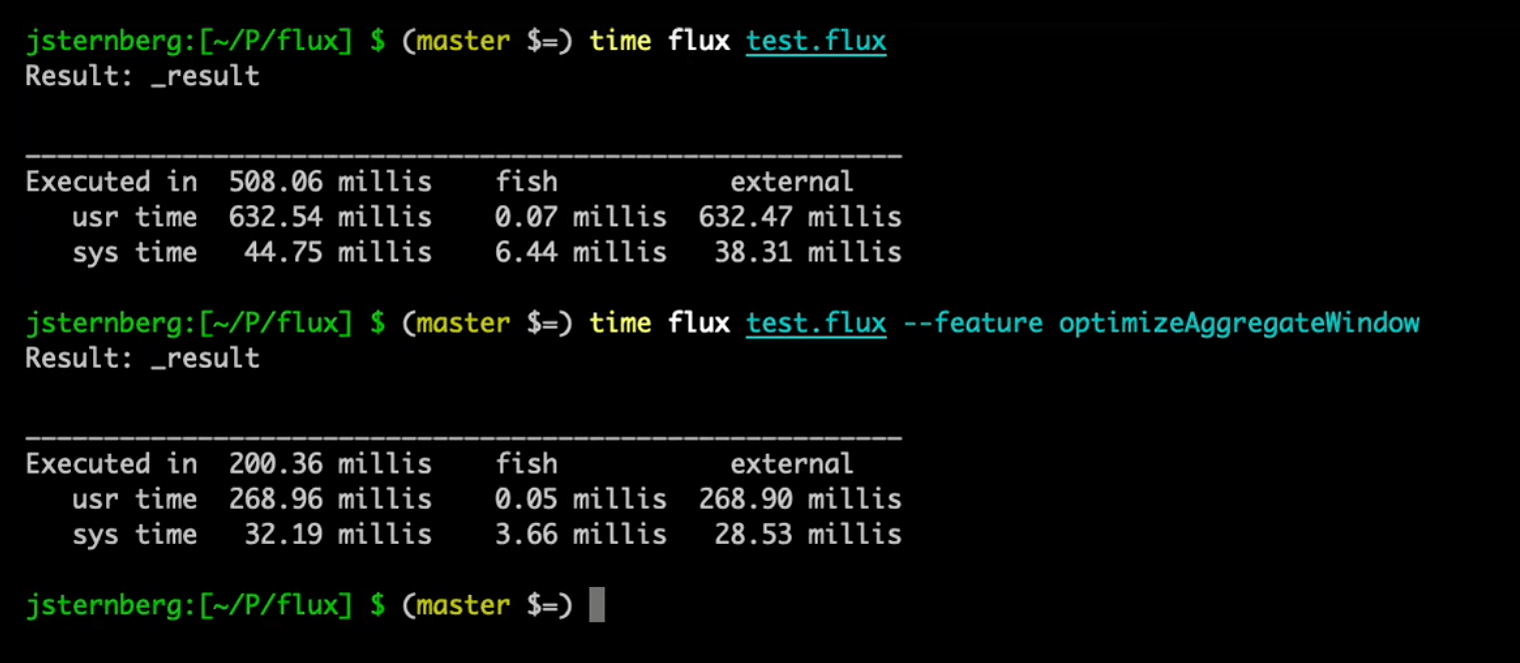
Previously a from |> range |> group |> aggregateWindow pattern took ~508 ms. Now the execution time is reduced to ~200 ms! That’s a dramatic improvement in the speed of that query.
Final thoughts on optimizations to aggregateWindow()
I hope this InfluxDB Tech Tips post inspires you to take advantage of Flux to perform aggregateWindow() functions across grouped data. If you are using Flux and need help, please ask for some in our community site or Slack channel. If you’re developing a cool IoT application on top of InfluxDB, we’d love to hear about it, so make sure to share your story! Additionally, please share your thoughts, concerns, or questions in the comments section. We’d love to get your feedback and help you with any problems you run into!
