Table of Contents
For time series workloads, the ability of serverless functions to scale up and down is a major advantage, especially for something like IoT devices that may have intermittent connectivity and might suddenly send data in bursts. In this type of situation, it doesn’t make sense to be paying for a server to be running 24/7 when you can use a serverless function and only pay for the computing resources that you use.
In this article, you will learn how you can use serverless functions with InfluxDB, while also learning about some of the features provided by the InfluxDB platform.
- Tutorial requirements
- Write data to InfluxDB with AWS Lambda
- //grab environment variables
- //lambda event handler
- Working with data stored in InfluxDB
- Query InfluxDB using AWS Lambda
- Use InfluxDB alerts and tasks with AWS Lambda
- Wrapping up
- FAQ
Tutorial requirements
To follow this tutorial, you will need a working instance of InfluxDB and an AWS account. The fastest and easiest way to get a working InfluxDB account running is to create a free InfluxDB Cloud account. The other option is to install the open source version of InfluxDB.
For our serverless functions this tutorial uses AWS Lambda, which requires an AWS account to use. You can also use another serverless service like Google Cloud Functions or Azure Functions; once set up, the code will largely work the same way.
Write data to InfluxDB with AWS Lambda
The first thing you need to do is get some data into InfluxDB. There are a number of ways you can do this:
- Use the InfluxDB UI – The InfluxDB user interface lets you either upload CSV or text files formatted in line protocol or directly type line protocol and submit it through the UI.
- Telegraf – Telegraf is a server agent that has plugins with over 200 different tools and services that can be used to collect data and output it to over 50 different destinations. One output is the HTTP plugin which sends the data as an HTTP post request which could be defined as an AWS Lambda function
- InfluxDB CLI – The InfluxDB CLI can be used for writing data to InfluxDB and doing many other tasks from the command line.
- InfluxDB Client Libraries – InfluxDB provides client libraries for 14 different programming languages.
For this tutorial, we will use the Javascript client library with AWS Lambda to write data to InfluxDB. For this example, we will do this with an HTTP request using API Gateway.
Inside the AWS console, you want to create a Lambda function. Once that is done, you will need to create a Lambda Layer, which will allow you to use the InfluxDB client library and any other NPM packages you want to use in your Lambda function. To do this, you will need to create the node modules and package.json file you want to utilize locally on your computer and then upload it as a zip file. Here is what you want the folder structure to look like:
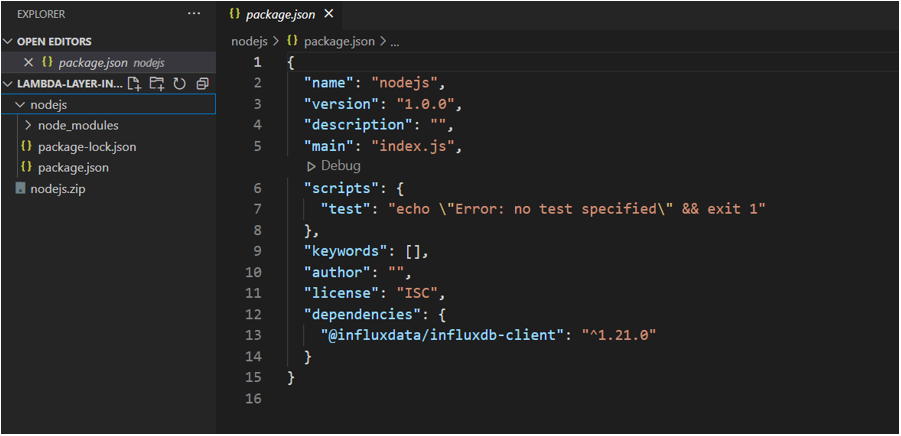
The key things to note here are that the outer director MUST be named ‘nodejs’. Inside that folder you just need to run npm init and install your dependencies like you would for any normal nodeJS project. The only package needed to follow this tutorial is the InfluxDB javascript client library which can be installed using the following command:
npm install --save @influxdata/influxdb-client
You can then use whatever zip compression utility is provided by your operating system to zip up the nodejs directory and upload it as a layer. To do this you just need to go to the AWS Lambda dashboard and look at the sidebar where it says “additional resources” and click on the “Layers” tabs. Once there you can click the orange “Create Layer” button. Give it a name, upload the zip file, and then choose the NodeJS version runtime that matches whatever version you want to use for your Lambda function.
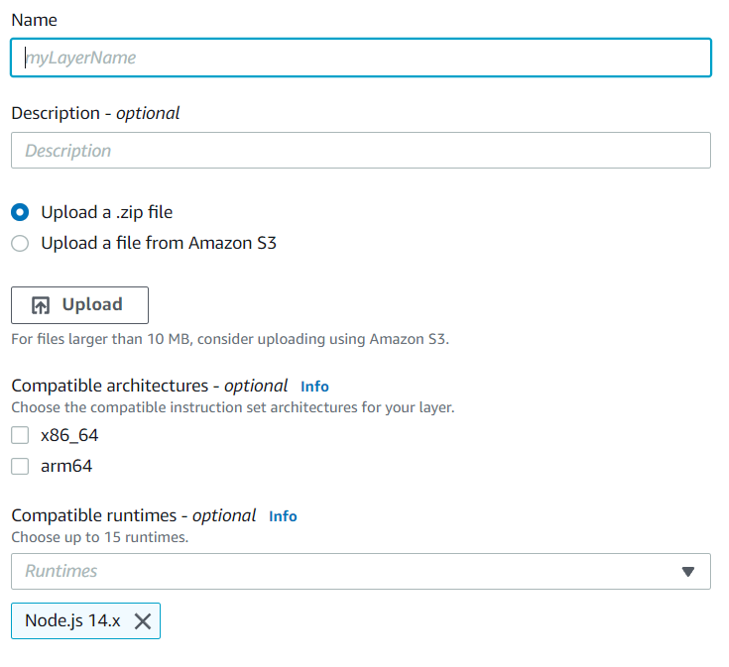
The good thing about creating this layer is that you can reuse it so you have access to the InfluxDB client library across multiple Lambda functions without having to go through this process again. You can also use multiple layers for functions, so that you can “layer” different functionality and environments for your use case.
With that setup, you now need to create your Lambda Function from the main Lamda dashboard. Give it whatever name you want, select the Node.js 14.x runtime and then hit the ‘create function’ button.
Inside the function-specific dashboard, you will want to add the layer you just created. This can be done by scrolling to the bottom of the dashboard and clicking “add a layer”, then on the page that opens up, you will click on the “custom layer” tab and choose the layer you created earlier.
For a trigger, you will want to use the Amazon API Gateway trigger so you can invoke the function via an HTTP request. Select ‘create an API’ and make it an HTTP API type with Open security. Once the Amazon API Gateway has been created, click on it and copy the API endpoint URL, this will be used later for making our API requests.
Before writing code for the Lambda function, you will need to authenticate using your InfluxDB account token and credentials. To set all that up you can check out this tutorial which goes through the basics. You will need 4 things specifically to run the code:
- Account organization name – This is made when you create your account and can be found in your settings
- Bucket name – The name of the InfluxDB bucket where you want to store the data
- Token – API token used to authenticate your requests
- InfluxDB instance URL – If you are using a cloud account this URL will depend on which cloud region you chose during account creation, this URL will be the subdomain of your dashboard URL. You can find the whole list of cloud URLs here. If you are using the open source version it will be on localhost, the URLs can be found here.
Inside your Lambda function, you will want to go into the ‘configuration’ tab and create some environment variables for each of these values so they can be assigned to variables.
With all the setup out of the way, let’s get to the code. Here is all the code for the Lambda function. This module will write data to our InfluxDB instance, with inline comments explaining what is happening at each stage:
//import InfluxDB client, this is possible thanks to the layer we created
const {InfluxDB, Point, } = require('@influxdata/influxdb-client')
//grab environment variables
const org = process.env.org
const bucket = process.env.bucket
const token = process.env.token;
const url = process.env.url
//lambda event handler, this code is ran on every external request
exports.handler = async (event) => {
//parse the expected JSON from the body of the POST request
var body = JSON.parse(event.body)
//create InfluxDB api client with URL and token, then create Write API for the specific org and bucket
const writeApi = await new InfluxDB({url, token}).getWriteApi(org, bucket);
//create a data point with health as the measurement name, a field value for heart beat, and userID tag
const dataPoint = new Point('health')
.tag('userID', body['userID'])
.floatField('heartRate', body['heartbeatRate'])
//write data point
await writeApi.writePoint(dataPoint)
//close write API
await writeApi.close().then(() => {
console.log('WRITE FINISHED')
})
//send back response to the client
const response = {
statusCode: 200,
body: JSON.stringify('Write successful'),
};
return response;
};
To test this function and make sure everything is working, you can use any tool you want for making HTTP requests. I’ll be using Postman. If you want to learn more about how to use Postman you can check out this guide that covers the basics of Postman and using the InfluxDB REST API. The request in Postman will look like this:
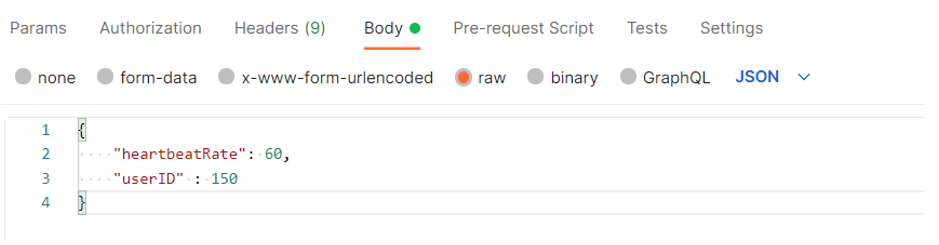
If everything works correctly, you should get a response saying “Write successful”. After making a few requests to the function with different values and user IDs, you can go to the data explorer tab in the InfluxDB UI and check out your data. Click on the bucket name you created, and you should see the “health” measurement available. You can see two different colored lines here because I submitted requests with two different User ID tags. Try playing around with the filtering options and different chart styles in the dashboard and see what you can do.
Working with data stored in InfluxDB
Now that you have some data in InfluxDB, let’s go over some examples of what you can do with that data.
Query InfluxDB using AWS Lambda
Just like you can use the InfluxDB client libraries to write data to InfluxDB, you can also use them to query data. One reason you might want to do this is to display a custom UI to end users. For an example of this, you can check out this tutorial showing how to use the Nivo ReactJS charting library. With this method, you can display data by using the JavaScript client library.
Using the example ‘heartbeat data’ we wrote above, you could filter data based on a user ID and then display their health data to them. To do this, you could use AWS Lambda functions to make the API requests for your app. While you can query InfluxDB from the browser using JavaScript, this would expose your API key to the public which is a security risk. By using a serverless function, you can keep your API key secure while also not having to worry about managing a server. All you have to do is write the code for requesting the data.
Another use case for the client library might be data analysis. While Flux is able to do just about anything you want in terms of data analysis, you might be more comfortable with another programming language or want to take advantage of certain libraries and the language ecosystem. You can check out this guide for pulling data from InfluxDB with Python and then transforming that data using Pandas dataframes. A more complex example building off that would be this stock market example which shows how to use Sci-kit learn and Keras to make price predictions.
Use InfluxDB Alerts and Tasks with AWS Lambda
Other common use cases for data stored in InfluxDB relate to advanced data handling. For instance, you can include some kind of data transformation and alerting based on stored data. For data transformation, InfluxDB provides Tasks, which allow you to run scheduled Flux scripts on a certain bucket of data, and then output that data into a new bucket. Some common examples of this would be downsampling data to reduce storage costs by decreasing the precision of the stored data. In another example, you could enrich data by joining data from another source like a relational database. Some other common use cases are sanitizing data, forecasting, creating reports, event triggers, and generating data.
Many of these data transformation tasks could also be done using a serverless framework and functions. You might use an auxiliary service to schedule a function to run at a regular interval, but from a cost and performance perspective it’s hard to beat doing this type of work inside the database using InfluxDB tasks, and connecting everything is a chore from a usability perspective.
You can also monitor your data and create alerts if defined thresholds and parameters don’t meet your defined conditions. You can set how frequently these thresholds are checked, and then take action by adding an endpoint to send an alert if your data is out of range. InfluxDB provides built-in integrations with Slack and PagerDuty for alerts in the UI, with Flux also having a number of other 3rd party integrations available like Discord, Telegram, ServiceNow, and others. You also have the option of defining an HTTP endpoint if you want maximum flexibility. You could create a serverless endpoint and then handle your alerts using that serverless function. An example could be creating AWS Lambda functions that take the alert and then send a text message to whoever is on-call using Twilio or another SMS service.
Wrapping up
The real takeaway here is that by using InfluxDB, you have maximum flexibility as a developer. You can get comfortable with Flux and take advantage of all the built-in functionality provided by InfluxDB while also having the option to use your favorite programming languages when the need arises.
If you want to learn more about how you can use InfluxDB with serverless functions and some other great resources for how to use the InfluxData platform, you can check out these links:
- Extend InfluxDB with serverless functions
- What is time series data and why is it important?
- Streaming time series data with Jupyter and InfluxDB
- Intro to time series forecasting with InfluxDB and Tensorflow
- Learn more about Flux
- Get started with Telegraf
FAQs
What is the difference between ‘serverless’ and AWS Lambda Serverless Functions?
The difference is that Lambda is a specifically AWS vendor service for offering serverless functioning capabilities.
By contrast, ‘serverless computing’ simply refers to the use of any vendor system to outsource functions to a remote server.
Some experts explain that ‘serverless’ is the generic term and Lambda is the AWS-specific term.
Why is Lambda serverless?
Lambda is not serverless because the functions run without using any server at all. AWS lambda is serverless because instead of having to use their own server, a client can get individual functions running on the vendor’s server, so it is serverless from the viewpoint of the client.
How do you deploy Lambda functions with serverless?
The short answer is that you integrate AWS lambda service into your apps and APIs in order to utilize that serverless function within a given serverless framework.
What are the benefits of AWS serverless functions?
Serverless functions are a serverless computing service provided by AWS. It is an event-driven, computing platform that lets you upload code to build serverless applications without the need to manage infrastructure. In a serverless architecture all infrastructure maintenance such as operating system configuration, patching and security updates is handled by the AWS cloud provider. There are several benefits to serverless functions:
- Cost Savings: Serverless functions are cost-effective because you are only charged for data processing when an event takes place and the code runs.
- Security: Serverless functions are run in containers that isolate their runtime environment from other serverless applications and external sources.
- Speed: Serverless functions have high performance because they allow for automatic scaling up or down depending on the application’s traffic.
- Simplicity: Instead of worrying about infrastructure management, capacity provisioning and hardware maintenance, teams can use aws services to focus on application design, deployment, and delivery.
- Reliability: Serverless functions are less prone to failure. Serverless applications are a series of interconnected services in the cloud that make them naturally redundant.
- Scalability: Instead of increasing the total resource allocation for your entire serverless application, you can use a Function-as-a-Service (FaaS) model to scale up individual processes as needed. This flexibility reduces unnecessary costs for data processing and improves overall app efficiency.
Which services are serverless in AWS infrastructure?
- AWS Lambda Functions: AWS Lambda Functions are a part of the serverless framework. These functions run event-driven serverless applications where compute resources are automatically managed by the cloud provider.
- Amazon API Gateway: Amazon API Gateway is an AWS service in the serverless framework that lets developers build, test, deploy and monitor APIs.
- Amazon DynamoDB: Amazon DynamoDB is a part of the serverless stack that is a fully managed NoSQL database service that lets you offload administrative tasks such as setup, configuration, scaling
- Amazon S3: Amazon Simple Storage Service (S3) is the Amazon Web Services (AWS) storage platform that provides S3 storage for objects.
- Amazon Kinesis: An Amazon Kinesis is a real-time event based streaming service
- Amazon Aurora: Amazon Aurora is a fully managed Amazon Relational Database Service (RDS) that handles all management tasks. It provides granular point-in-time recovery.
- AWS Fargate: AWS Fargate is a serverless compute engine that uses a pay-as-you-go model where compute time is charged on your compute instance only when you are using the service.
- Amazon SNS: Amazon Simple Notification Service (SNS) is a simple, fast, reliable, highly scalable messaging service
How does the AWS Lambda API work and why is it used with AWS resources?
AWS Lambda is a serverless event based service for running code. Lambda applications automatically manage compute resources for you. It differs from Fargate in the pricing model. Lambda charges per invocation and duration of each event. Fargate, on the other hand, charges for CPU and memory per second.
Are AWS Step Functions serverless?
Yes. Step Functions are serverless. It is an orchestration service that lets you create functions to build serverless workflows for a web application by combining AWS Lambda and other AWS services. Serverless workflows help you monitor each step in the workflow to verify that it runs in the order expected.
