InfluxDB 2.0 Open Source is Generally Available
By
Russ Savage
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
Today, we are proud to announce that InfluxDB Open Source 2.0 is now generally available for everyone. It’s been a long road, and we couldn’t have done it without the amazing support and contributions of our community. This marks a new era for the InfluxDB platform, but it truly is just the beginning.
Before we talk about the future, let’s take a look at some of the amazing new capabilities our team has been working on.
For those of you who just want to get going, check out our downloads page for the latest release as well as our getting started and upgrade guides.
Easy to deploy and secure by default
For anyone familiar with our existing open source offerings (lovingly referred to as the TICK Stack — short for Telegraf, InfluxDB, Chronograf, and Kapacitor), the first thing you might notice is that there’s only one binary to download and install.
The new InfluxDB now contains everything you need in a time series data platform in a single binary. This simplifies the deployment and setup experience all while maintaining the power and flexibility of individual components.
A single binary means it’s also much easier to secure, and so we made InfluxDB secure by default. Every request to InfluxDB is accompanied by an authentication token that can be revoked, and the built in user interface is secured with a username and password.
With these changes, you never have to worry about accidentally exposing data stored in InfluxDB to the public internet.
Easy to deploy, simple to manage, secure by default. Developers expect these things from modern development platforms, and InfluxDB is no different.
Next-generation data exploration and analytics
We know how important it is for developers to get hands on with their data as quickly as possible. One thing we heard constantly from our community is that Chronograf, (the “C” of the TICK Stack), made it incredibly easy to quickly see the shape of the time series data coming into the system and simplified a number of common administrative tasks.
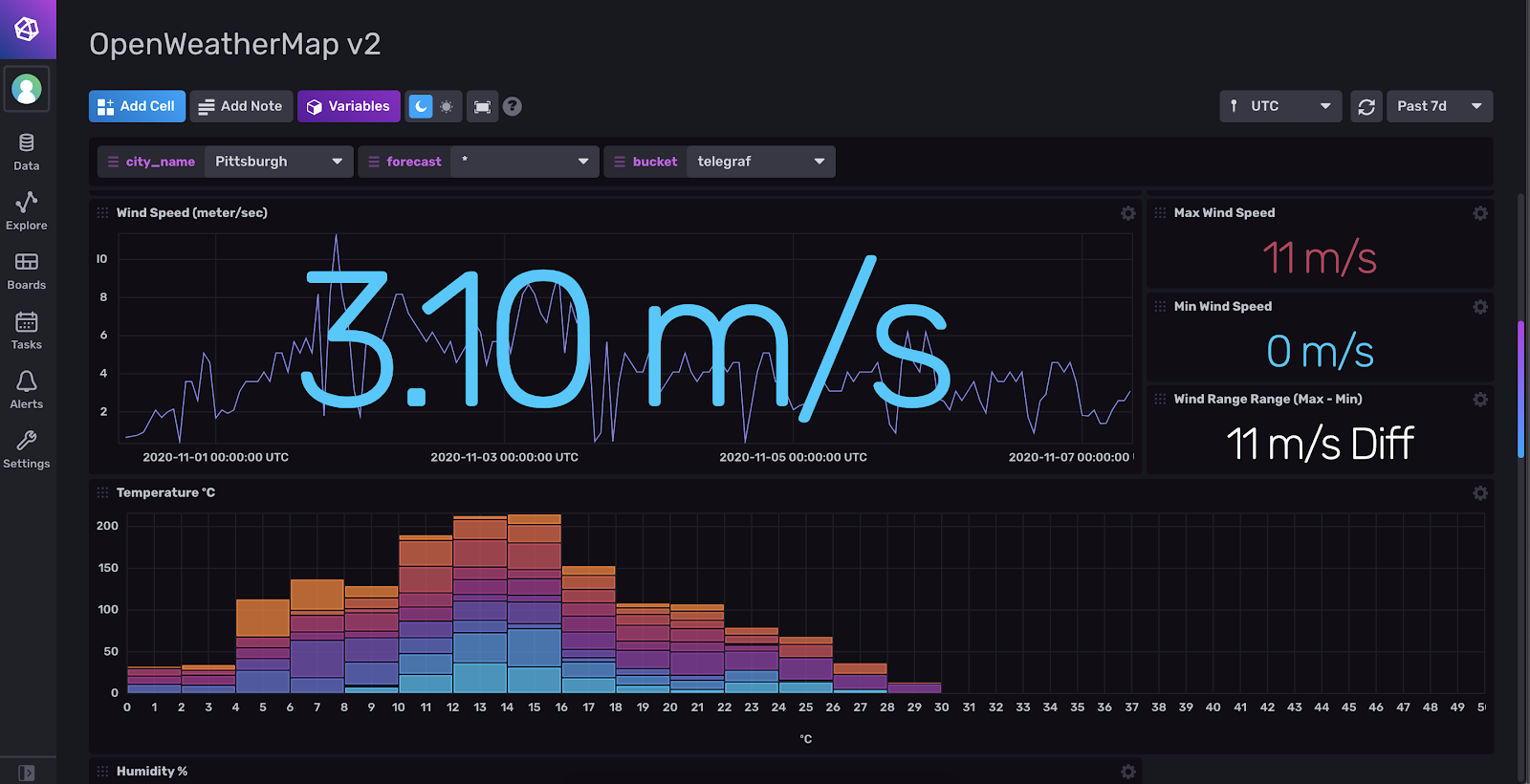
InfluxDB Open Source 2.0 continues that experience with an all-new Data Explorer, additional visualization types, and a powerful new query language called Flux that’s purposely built for time series data. You can quickly browse through all your measurements, fields, and tags, and apply common transformations to that data without reaching for your keyboard.
Here’s what our new Data Explorer looks like:

Of course, for those looking to unlock the full potential of their data, we have included a script editor that includes auto completion, real-time syntax checking, and plenty of examples and documentation to get you started. This editor is used across InfluxDB — Data Explorer, Dashboards, and Tasks — and uses Monaco, the same editor in Visual Studio Code.
Wait, but you already have a ton of applications and integrations built on InfluxQL? Not a problem. InfluxDB 2.0 is designed to be a drop-in replacement for your existing InfluxDB instances. That means if you are using an external visualization tool for dashboarding, or writing data into the database, it will still work after you upgrade. Of course, we recommend migrating those connections to the latest v2 APIs, but they will continue to work just fine as-is. Backward- compatible APIs are in place to help you move as quickly as you desire.
Flux: Next-generation data processing language to work with data where it resides
Many users love the simplicity of accessing their data via InfluxQL, our SQL-like query language. As an easy on-ramp to the platform, that was a great place to experience the power of InfluxDB. But, over time, as the complexity of use cases increase beyond something more than a simple select statement, there were challenges. As a result, developers ended up writing custom application logic to do much of the complex transformations often required for modern applications.
That has a few drawbacks. For one, we want to build a platform that makes developers more productive, and any time spent writing common data transformation logic is time taken away from building value for their own users and customers. The second drawback is performance. The further the data gets from the storage layer, the slower the transformations tend to become.
Flux at its core is meant to solve those problems. Flux isn’t a SQL-like language; it’s a functional programming language similar to JavaScript or Python. That means you can customize and structure queries just like programming applications, separating common logic into reusable functions and libraries, reducing the overall amount of code you need to write. That code is also executed as close as possible to the storage layer, pushing down many operations directly, which gives you the fastest possible performance from the system.
Data is better together
Flux is also built to work with more than just time series data (although that’s its bread and butter). It can directly pull data from SQL data stores, such as Postgres, Microsoft SQL Server, SQLite, and SAP Hana along with cloud-based data stores like Google Bigtable, Amazon Athena, and Snowflake. This lets you enrich time series data to provide additional context. Here are a few examples:
- For IoT users, Flux lets you combine time series data from sensors with information from relational tables like manufacturer, model number, device age or mileage.
- For real user monitoring (RUM), you can use Flux to look up customer IDs and connect customer name, pricing plan, and firmographics like company name and location.
- In IT infrastructure monitoring, Flux can resolve server IDs to software version and configuration parameters.
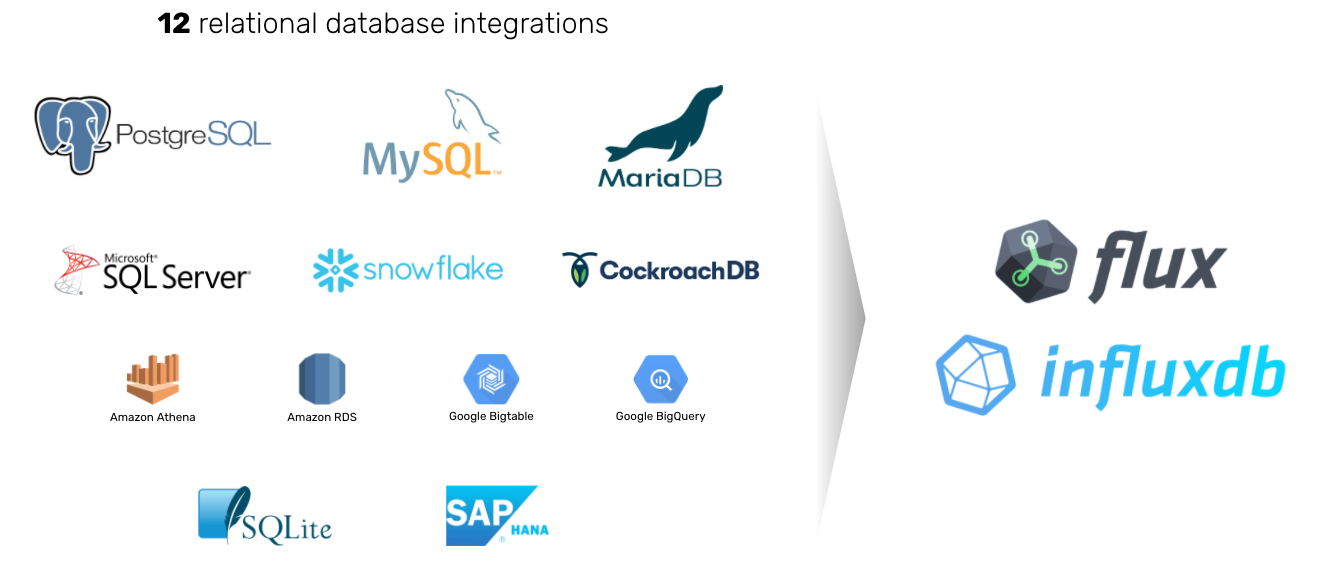 <figcaption> InfluxDB and Flux let you enrich time series data using relational databases</figcaption>
<figcaption> InfluxDB and Flux let you enrich time series data using relational databases</figcaption>
Time meet space: Geotemporal queries with Flux
Flux also lets you perform geotemporal queries, so you can filter by both time and location. This is essential for many IoT use cases where you need to track devices or vehicles that are on the move. For instance, the straightforward Flux query below lets you query all points bounded by the triangle with points at the three coordinates.
from(bucket: "example-bucket")
|> range(start: -1h)
|> filter(fn: (r) => r._measurement == "example-measurement")
|> geo.filterRows(
region: {
points: [
{lat: 40.671659, lon: -73.936631},
{lat: 40.706543, lon: -73.749177},
{lat: 40.791333, lon: -73.880327}
]
}
)Using the query above, you have data for the visualization below:
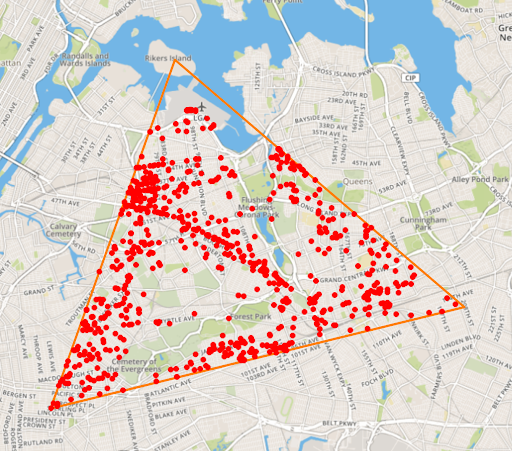 <figcaption> Flux’s geotemporal library lets you query by location as well as time</figcaption>
<figcaption> Flux’s geotemporal library lets you query by location as well as time</figcaption>
Developers are looking for more than just the ability to query their data. They want to build with it. Flux gives our community the fastest and most powerful way to analyze and build applications with data, and we can’t wait for you to give it a try.
Background processing for calculated metrics, downsampling, and more
Interactively working with your data can provide powerful insights, but in modern systems, those interactive queries account for only a tiny fraction of the overall processing happening. Most of the data flowing into your application is more powerful when combined with other information to produce knowledge about what’s happening. That processing needs to continuously and reliably happen in the background while you focus on leveraging the insights.
InfluxDB 2.0 contains a powerful new background processing system called Tasks that are built and executed using the same Flux language used to access data stored within the platform. These Tasks can do a lot of powerful things, including aggregating commonly accessed metrics to improve performance of your dashboards, calculating custom metrics based on data stored in completely different systems, or downsampling your data to save money on long-term storage.
Tasks can also be leveraged to automatically push data to other systems, which enable notifications or alerting on your data. Because they are based on the Flux language, as we add new libraries, functionality, or tooling, that can be leveraged in Tasks automatically.
InfluxDB Tasks are similar in concept to Kapacitor (the “K” in TICK). But unlike Kapacitor, which uses a language called TICKscript that’s separate from InfluxQL that’s used in Chronograf, Tasks use Flux. This simplifies life for developers, since they can use one language for both queries in Data Explorer and Dashboards, and data processing in Tasks.
Tasks are the processing backbone of the platform, and we think you’re going to find some amazing ways to use them.
Real-time alerting and notifications
Our motto around the company is that our teams should never have to look at a dashboard to know something is wrong. Monitoring and alerting are crucial to any application platform, and we’re no exception.
InfluxDB 2.0 includes a powerful monitoring and alerting system that’s based on the same technology as Tasks and Flux. Our native UI provides a way to quickly define threshold and deadman alerts on your data, but if you need more flexibility, you can build your own custom alerting using the underlying Tasks system.
 <figcaption> InfluxDB and Flux let you send alerts to a broad range of endpoints</figcaption>
<figcaption> InfluxDB and Flux let you send alerts to a broad range of endpoints</figcaption>
Notifications from these alerts can be sent to any number of external systems including PagerDuty, Slack, Microsoft Teams, email, MQTT, or a custom HTTP endpoint (webhook) that you control. We provide an intuitive user interface for defining and managing these alerts, but every bit of functionality offered through the UI is exposed through our API, so you can build automation that works for you.
A common API with uncommonly good tooling
Time is the ultimate scarce resource, and it’s pretty common for developers to constantly balance ease of use with power and flexibility for the future. With InfluxDB 2.0, we wanted to make it dead-simple to get going, but also give our community the confidence that as their use cases evolve and their usage grows, we’ve got you covered.
Our next-generation platform is built around a single, common API. Whether you’re building an application locally on your laptop, or scaling to millions of users across the globe, the APIs you build your application around are the same.
That also allows us to provide a powerful set of command line tools and language-specific client libraries across 10 languages and SDKs that work across all our products. If you’re building an application, the fastest way to get up and running with InfluxDB is through one of our client libraries.
 <figcaption> InfluxDB client libraries are available in several languages</figcaption>
<figcaption> InfluxDB client libraries are available in several languages</figcaption>
No matter what you’re building now, or what scale you need in the future, you can rest assured that you won’t need to rewrite your application to take advantage of the power of InfluxDB.
Modern GitOps workflows via InfluxDB Stacks and Templates
Kubernetes has taken over the world, and it has brought along with it the rise of GitOps workflows that make managing and deploying applications as simple as checking in code. InfluxDB 2.0 is designed to integrate seamlessly into your GitOps deployment strategies leveraging InfluxDB Stacks and Templates.
Using the command line tooling, you can quickly manage the state of all resources in the platform, with declarative configurations and git-based change management. This also allows you to build powerful continuous integration and deployment pipelines to make deploying (and more importantly rolling back) changes painless.
That technology powers the InfluxDB Templates capability which provides out-of-the-box full-stack monitoring for a wide variety of popular technologies. InfluxDB Templates are free to use and the template gallery continues to grow as contributions are made by experts looking to share their expertise with others. You can tap into the collective knowledge of the InfluxDB community while maintaining the freedom to extend and customize the template to fit your exact needs. Think you’ve got the right stuff? You can contribute your expertise as well!
 <figcaption> InfluxDB Template Gallery</figcaption>
<figcaption> InfluxDB Template Gallery</figcaption>
InfluxDB 2.0 allows you to deploy changes with confidence and stand on the shoulders of experts, allowing you to focus on building your application.
Where we go from here
As I said in the very beginning of this post, this release represents a lot of hard work by our engineering team across nearly two years of engaging with and listening to our community, but it is only the beginning. Going forward, you can expect a few things. We plan on standardizing our release cadence so that the community knows when to expect new features and bug fixes.
Our roadmap for InfluxDB Open Source will start to focus on unlocking use cases that require software to be deployed locally but continue to work in conjunction with the other parts of the InfluxDB Platform, including InfluxDB Cloud. Look for simple ways to unlock data replication and aggregation to the cloud as well as more ways to ingest and analyze data at the edge.
We are extremely excited about the future of open source software and humbled by our amazing community that helps us build great software. We hope you join us on this journey and come say hello on GitHub or in our community forums and Slack.
