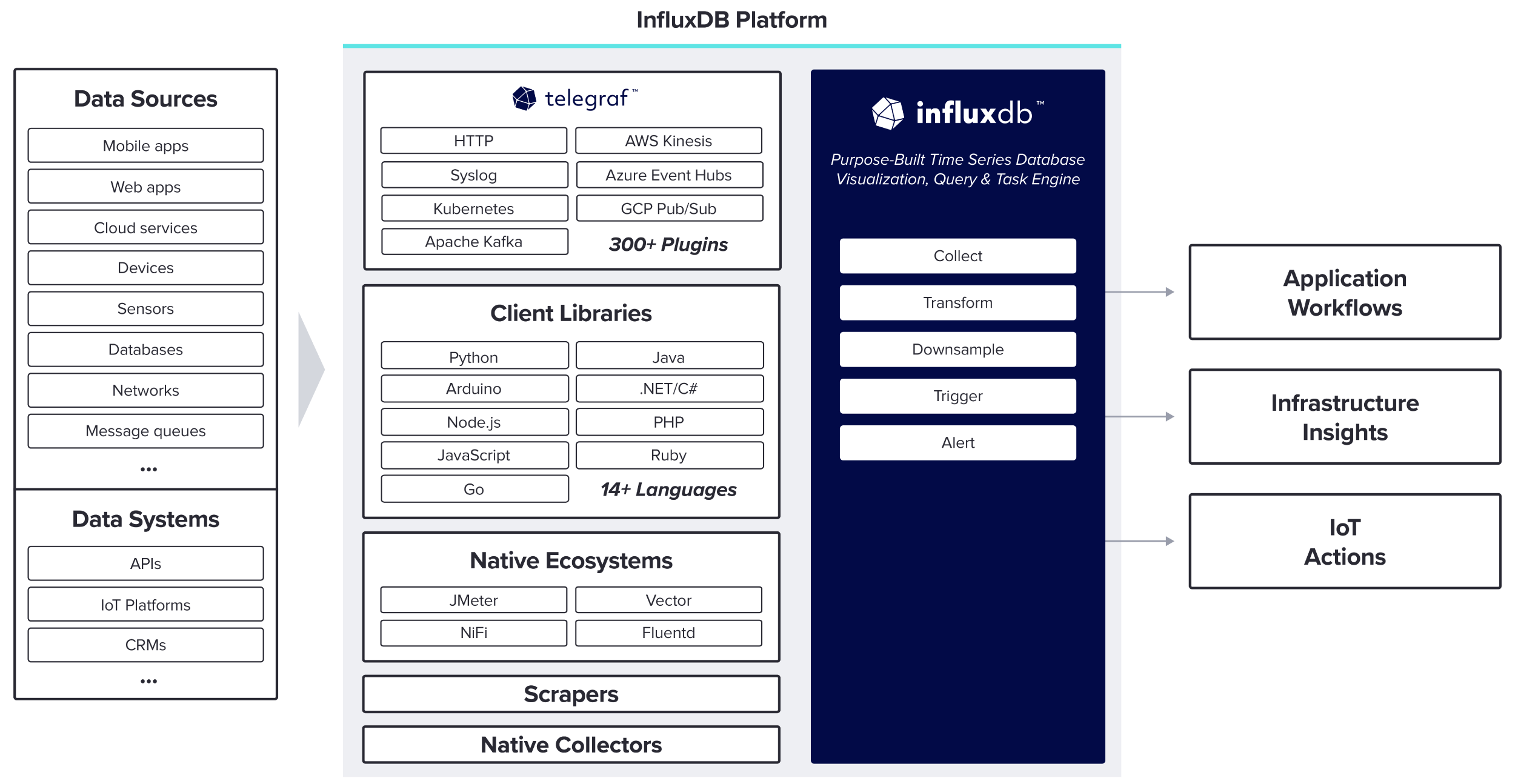
Data Collection
Ingest data into InfluxDB with developer tools like client libraries, popular pub-sub protocols, or low-code options that include Telegraf, scrapers, or native integrations from third-party technologies.
Why ingest data with InfluxDB Data Collectors?
Getting time series data from its source to a place where developers can use it starts with data ingestion. Data ingestion involves collecting data from its source, performing transformations, and storing it. InfluxDB Data Collectors offer many data ingestion methods to support different data sources, protocols, and formats.
Telegraf
Telegraf is a plugin-driven server agent for collecting and sending metrics and events from databases, systems, and IoT sensors.

Client Libraries
Language and platform-specific packages that provides a programmatic way to interface with InfluxDB.

Scrapers
Scrape Prometheus-formatted metrics from an HTTP-accessible endpoint and store them in InfluxDB.


InfluxDB API
Build your own with the InfluxDB API, which provides a programmatic interface for interactions with InfluxDB.
How to Ingest Data with InfluxDB
Key capabilities

Data diversity

Transformation

Robust delivery

Scale and fidelity
Integrations
InfluxDB Data Collectors offer many ways to collect a variety of metrics, events, and logs from popular containers and systems.







