InfluxDB for Network Monitoring
Track mission-critical systems and devices to gain better insights into network performance. Identify and resolve issues like speed degradations and connectivity failures before they impact users.
#1
Time Series Database
Source: DB Engines
1B+
Downloads of InfluxDB
Take the complexity out of time series data management
Try InfluxDBTurn high-volume, high-velocity, high-resolution time series data into actionable intelligence without sacrificing performance.
Get high-speed ingestion, real-time querying, and seamless scalability in a highly performant time series database that can handle unlimited volumes of time series data, even as data complexity and cardinality increases.
Run InfluxDB at scale in any environment in the cloud, on-premises, or at the edge. InfluxDB consists of the core database and storage engine, an API, and an ecosystem of tools and integrations to manage time-stamped data. Easily integrate with 5K+ prebuilt connections using Telegraf, our open source agent with 5B+ downloads.
Run InfluxDB 3 where you need it
Start for free, scale in seconds
Start NowFor small workloads and getting started
Deploy anywhere: on-prem, private cloud, edge, or multi-tenant cloud.
Secure, dedicated cloud infrastructure
Run a Proof of ConceptFor scaled workloads
Fully-managed, single-tenant service with unlimited scale, high availability, secure private connections, and enhanced Support.
Own your data with enterprise features
Run a Proof of ConceptFor scaled workloads
Control your infrastructure with unlimited scale, high availability, enterprise-grade security, and enhanced Support. On-prem, private cloud, and edge deployment.
Why InfluxDB
Limitless data collection
Ingest and analyze millions of time series data points per second without limits or caps.
Predict and prevent
Maximize uptime and prevent costly failures with real-time monitoring and preventative insights.
Real-time query
Data is immediately available for querying in InfluxDB, enabling real-time SQL queries and lightning-fast responses.
Why a purpose-built time series database?
Time series data are measurements or events that are tracked, monitored, downsampled, and aggregated over time. This could be server metrics, application performance monitoring, network data, sensor data, events, clicks, trades in a market, and many other types of analytics data.
Why InfluxDB for network monitoring?
Networks play a fundamental role in the adoption and growth of Internet applications. Penetrating enterprises, homes, factories, and even cities, networks sustain modern society. While assuring responsive and performant networks in today’s hybrid, distributed, and containerized application environments occurs behind the scenes in intangible clouds and diagram abstractions, network glitches are more visible and unforgiving than ever.
Network availability, responsiveness, and bandwidth consumption are the three pillars that separate unmonitored from monitored networks—and if you feed this data into a centralized time series platform you will be able to have a holistic view of your network performance monitoring.
Network availability refers to host reachability. If the network is unavailable, there could be something related to the endpoint health or network path (such as a load balancer’s sessions limit or expired SSL) preventing traffic from reaching the host.
Network responsiveness is the combination of latency and packet loss. Latency refers to the time it takes for traffic to cross the network to a target, and packet loss determines the error rate experienced. Latency and packet loss render the network suitable for all or some more sensitive applications. For instance, high latency will completely undermine unified communications (voice & video) services.
Network bandwidth consumption tracks metrics from the network interface, providing important information about bandwidth load, which can be used to set up alerts before the interface is completely saturated. Adding to the network interface metrics data from network traffic analysis appliances allows for the identification of bandwidth consumption struggles, providing precious insights about sessions and IPs/protocol/port troublemakers that are causing saturation, as well as identifying resource misuse and potential Denial of Service (DoS) attacks.
Related resources for developers
InfluxDB Integrations
Free InfluxDB training
“InfluxDB is the most powerful technology to fit the moment. We can store a lot of metrics and manipulate them in real time.”
Hans GustavsonSenior Director, Site Reliability Engineering, Coupa Software
Open data standards drive performance and interoperability
InfluxDB 3 is built in Rust and the FDAP stack—Flight, DataFusion, Arrow, and Parquet—leveraging Apache-backed technologies to efficiently ingest, store, and analyze time series data at any scale.
Try InfluxDBF
Flight for efficient columnar data transfer
D
DataFusion for high-performance querying

A
Arrow for optimized in-memory columnar analytics

P
Parquet for high-compression storage
InfluxDB’s columnar database supports time series data at a lower TCO
See ways to get started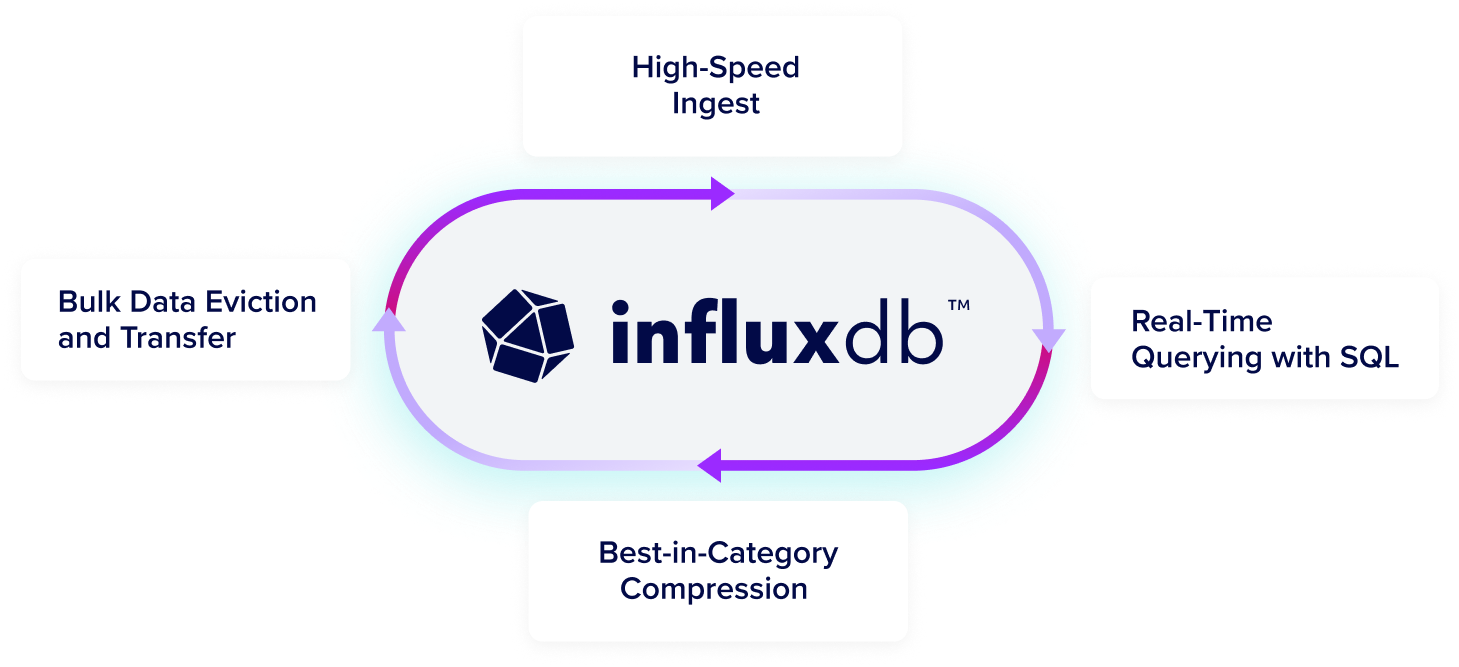

Loved by developers, trusted by enterprises

65M+
daly events processed
45x
more resource efficient
Siemens Energy
“[We] long used InfluxDB open source... Moving to commercial InfluxDB was a strategic move to unify our data infrastructure, ensuring we have the reliability, scalability, and real-time performance to keep pace with production... and proactive maintenance.”
Jan Petersen
Senior Manufacturing Engineer
500M+
Metrics collected daily
Mission-critical monitoring
Real-time data access for queries
LOFT ORBITAL
Space Made Simple: How Loft Orbital Delivers Unparalleled Speed-to-Space with InfluxDB Cloud
Read Case Study65M+
daly events processed
45x
more resource efficient
CAPITAL ONE
"InfluxDB is a high-speed read and write database. The data is written in real-time, you can read it in real-time, and while reading, you can apply your machine learning model. So, in real-time, you can forecast and detect anomalies."
Rajeev Tomer
Sr. Manager of Data Engineering
50%
lower total cost of ownership
100K
real-time metrics with simplified deployment
TERÉGA
Teréga Replaced Its Legacy Data Historian with InfluxDB
Lorem ipsum
Lorem ipsum dolor sit amet consectetur.
65M+
daly events processed
45x
more resource efficient
WIDEOPENWEST
"I was blown away with how easy it was to install and configure InfluxDB. The clustering was easy. The documentation was great, and the support has been second to none."
Dylan Shorter
Engineer III, Software and Product Integration Engineering
45%
Less equipment downtime
10%
Reduced waste
MAJIK SYSTEMS
From Reactive to Proactive: How MAJiK Systems Embraced Predictive Maintenance with InfluxDB and Time Series Data
Dylan Shorter
Engineer III, Software and Product Integration Engineering
65M+
daly events processed
45x
more resource efficient
JU:NIZ ENERGY
“With InfluxDB Cloud Dedicated, the great thing is that we don't need to think about data storage costs or usage anymore because data storage gets way cheaper.”
Ricardo Kissinger
Head of IT Infrastructure and IT Security



