Relational Databases vs Time Series Databases
By
Charles Mahler
updated October 20, 2023
Product
Use Cases
Navigate to:
Databases are often the biggest bottleneck when it comes to application performance. Over the years a number of new database designs have emerged to help with not only basic scalability and performance but also to help improve developer productivity and make building certain types of applications easier.
That isn’t to say these new databases are magical — there are always trade-offs being made and certain things are sacrificed for gains in other areas. The important thing is to know what options you have available and then choose the best tool for your specific use case. In this article, you will learn about time series databases and how they compare to more traditional relational databases.
Why choose a specialized database for your application?
In recent years there has been an explosion of specialized databases optimized for specific use cases:
-
Graph database - Used for storing and analyzing highly connected data efficiently.
-
Search database - Database designed for storing unstructured or semi-structured data and being able to efficiently search that data.
-
Time series database - Optimized for supporting high write throughput common for time series workloads and queries based on time ranges.
-
Key-value database - Supports high write and read performance while being highly scalable. The most basic type of NoSQL database, simply a key pointing to a value with no additional metadata.
-
In-memory database - Databases designed for working with data stored in RAM only, which results in not having to compromise performance due to no worries about disk access.
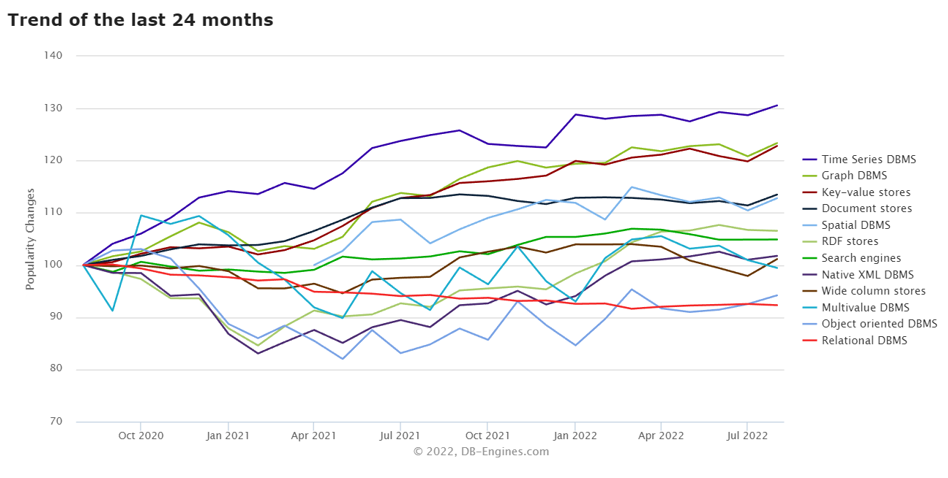
While relational databases are still dominant in terms of market share, we can see from the above chart that NoSQL databases are rapidly gaining adoption, with time series, key-value, and graph databases growing the fastest in the last 2 years.
There are several reasons developers have begun using more specialized databases for their applications. The first is that users are demanding better performance and more advanced features from software and every company is expected to meet expectations for performance set by the biggest tech companies in the world.
The second reason is that with the rise of microservice architectures, it has become easier for teams to select the best tools available for their application’s function. Because microservices are deployed independently and implementation details are abstracted away from other services, picking a more specialized database becomes easier because other teams don’t need to become familiar with the underlying technologies of the microservice they are interacting with.
The key thing to keep in mind is that adding another database to your architecture brings complexity. You always need to consider whether the benefits of using a specialized database are worth the costs. Make sure to weigh all the pros and cons before making a decision that will have a significant impact on your application long term.
Relational database overview
Relational databases store data in a tabular format consisting of rows and columns. Data is organized in tables and stored on disk as rows and data can be queried using SQL. Relational databases are versatile and by far the most commonly used database across many different types of applications.
Time series database overview
Time series databases are designed from the ground up for working with time series data. The result is a number of design tradeoffs made to improve the performance for time series workloads, which involves the ability to handle massive write throughput and unique query patterns for ranges of data based on timestamps. On the other hand when it comes to updating data or deleting specific data points, performance is sacrificed as a tradeoff because for most time series use cases, updating and deleting data points is rarely done or an outright anti-pattern.
In addition to being optimized for performance, time series databases include additional functionality that saves developers time and makes working with time series data easier than with a non-specialized database. Some examples of this include methods for managing the life cycle of data, retention policies, bulk data deletion, query languages with built-in methods for analyzing or forecasting with time series data, and alerting or other automation functionality to act on time series data.
Time series databases vs relational databases
In this section we will look at some of the technical aspects of each database to see why they have the performance characteristics they are known for and some of the advantages and disadvantages of each.
Relational vs time series database indexing
At the most basic level, the job of a database is to allow users to store data and then access it later. Everything else comes down to tradeoffs between how fast data can be written vs how fast data can be queried. Indexes make data retrieval faster but must be maintained and updated as data is written or updated. The overhead of maintaining indexes will result in slowing down how fast data can be written.
From an architecture perspective, for their primary index relational databases typically use a B Tree variation. On the other hand, NoSQL databases tend to use an LSM tree. B-Trees map well to underlying hardware storage and give balanced performance for reads and writes. LSM trees allow for very high write performance while read performance tends to be worse than a B-Tree based index.
Because write performance is critical for time series workloads, almost all storage engines for time series databases use LSM trees. Specialized secondary indexes are then optimized specifically for querying data across time ranges and other common time series data access patterns. To maintain these indexes the ability to delete or update specific data points takes a performance hit, but this is an acceptable tradeoff for time series databases because users should rarely do this anyway and know ahead of time the performance consequences and can plan around them.
Compression
Relational databases store their data in rows on disk, with the different data types next to each other. This limits what type of compression algorithms can be used and how much data can be compressed. In comparison time series databases often store their data in such a way that data points of the same type are next to each other, which allows for optimal compression algorithms to be used. The result is major savings on storage costs as in some cases data can be compressed 90% or more.
Schema
Relational databases have defined schema; any changes to table schema like adding or removing columns require database migrations. On the other hand, time series databases tend to be schemaless and allow new fields to be added quickly and easily.
Time series database use cases
Relational databases are versatile and can be used for almost any type of application with reasonable performance. By design, time series databases are optimized for working exclusively with time series data and won’t perform well when used in other situations. Let’s look at a few common areas where time series databases are used when scalability, performance, and efficiency are essential.
Application monitoring
One of the first areas time series databases were adopted is for monitoring applications. Being able to store large amounts of metrics and analyze that data in real time allows developers to build more reliable software and give their users a better experience.
IoT applications
The number of IoT devices being deployed all over the world is increasing every year, and they are all collecting or generating data. Most of that data is time series data, whether it’s a smart thermostat in your home or a sensor in a factory monitoring million dollar machinery. Being able to collect large volumes of data and query it efficiently allows for consumers and enterprises to be more efficient in many different ways.
Security
Cybersecurity becomes more important every year, with major hacks happening almost constantly it seems. One way businesses are mitigating security threats is by constantly monitoring activity on their networks and time series databases are a critical tool. They allow finer granularity data to be stored in a cost-effective way and allow that data to be monitored in real time. Current data can be compared to historical data and anomalies can quickly be detected to prevent or reduce the impact of security breaches.
Conclusion
Modern software development is changing fast on many different levels, from the development cycle itself, to the architecture of software, and the tools used to build individual pieces of software. Databases are one aspect of that, and knowing about some of the new types of databases that are available and how they might impact your work is critical to making wel-l informed decisions when making long-term design decisions.
