How to Expand Data Collection for InfluxDB with CloudFormation Templates
By
Nate Isley
updated December 14, 2025
Product
Use Cases
Developer
Navigate to:
In a previous post, I demonstrated how to call InfluxDB APIs from AWS Lambda, but the setup is fairly manual and the results are not portable. Ideally, we as a community can expand and share ways to collect and process time series data. To that end, I want to share a CloudFormation template.
CloudFormation is AWS’ infrastructure as code service that lets you define almost any AWS component in a configuration file. The result is a service that provides a concrete, repeatable definition of your environment that can prove useful in many scenarios. For example, if someone accidentally deletes your Simple Queue Service topic or an EC2 instance, you can easily recreate them by running your CloudFormation template.
A geo-temporal CloudFormation template
CloudFormation templates create AWS stacks that wrap the AWS components defined in the template. AWS stacks are easy to create, update, recreate, and remove.
The CloudFormation template that I’ll walk through below pulls earthquake data from the United States Geological Survey (USGS) every hour and writes it to InfluxDB. I will not attempt to give you a full CloudFormation tutorial, but it’s helpful to understand a breakdown of the different sections if you’d like to use this template to create your own:
- The first ~20 lines define variables that the template asks for when it's installed.
- Lines 21?–120 handle a quirk of Lambda deployments that requires the Lambda assets to be in your region before deployment. As there is no elegant workaround, these 100 lines create an S3 bucket in your account in the region you are creating the stack and copies in the resources.
- Lines 121?–132 define a role with basic permission to run the Lambda.
- Lines 133?–144 define a Python library layer. Lambda layers are really handy at decoupling your functions from supporting libraries. In this layer, I packaged the Python HTTP library, a Python S2 Geometry library, and the InfluxDB Python client library.
- Lines 146?–165 define the Lambda function. The Lambda is a short Python script that is zipped up in a file called geo_lambda.zip.
- Lines 166?–188 define an event rule with permission to run the Lambda. The rule will run the Lambda every hour.
Deploying the Lambda Stack
Now that we have explored the template, let’s deploy it. First, log into your free AWS account and search for the CloudFormation service. Make sure you’re in the AWS region you want to deploy the Lambda to? I have deployed more stacks in the incorrect region than I would like to admit. The following screenshot shows a search for CloudFormation while in the N. Virginia region (upper right):
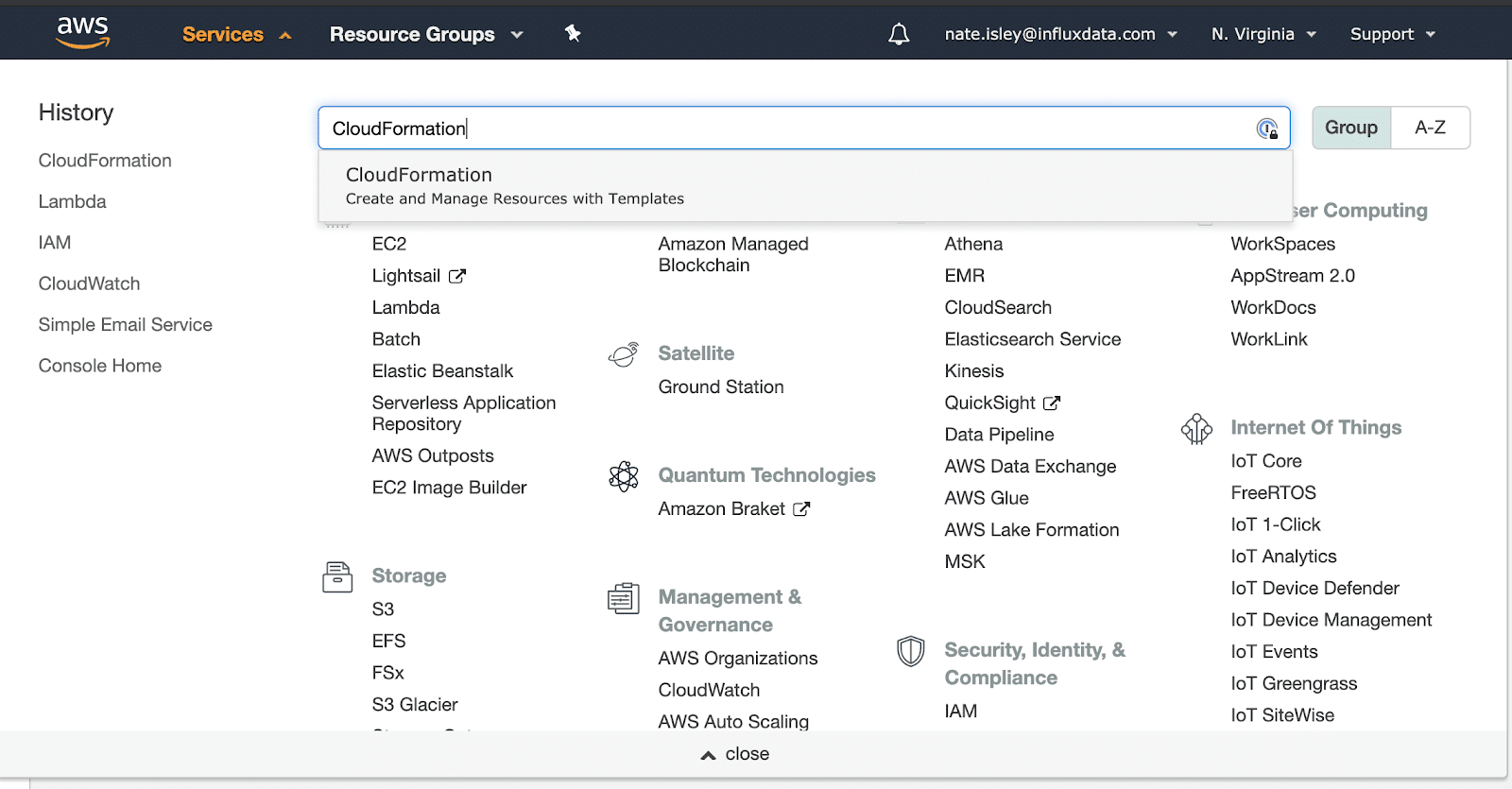
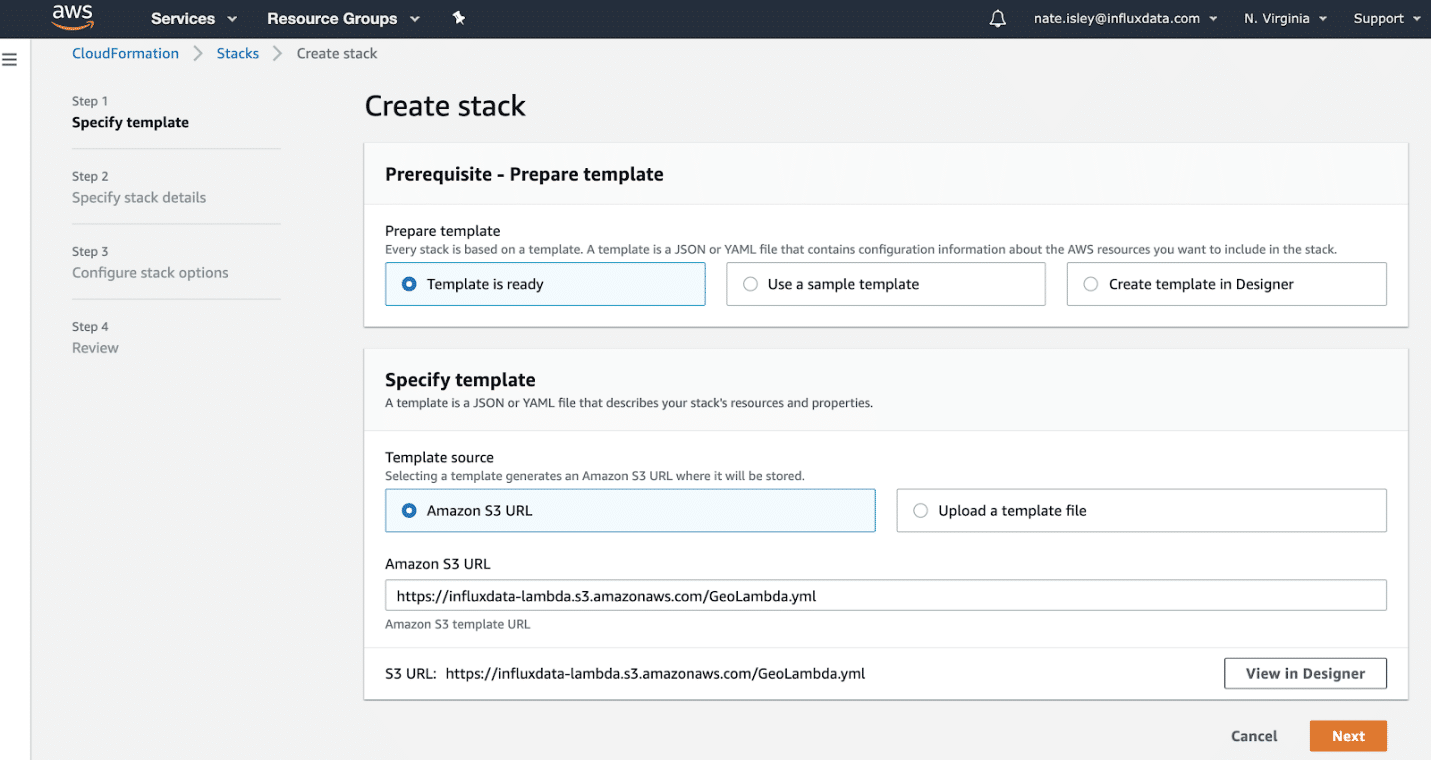
Once you navigate to CloudFormation, click the Create Stack button. Select Template is ready and Amazon S3 URL options, and then copy and paste the following URL into the Amazon S3 URL field:
https://influxdata-lambda.s3.amazonaws.com/GeoLambda.yml
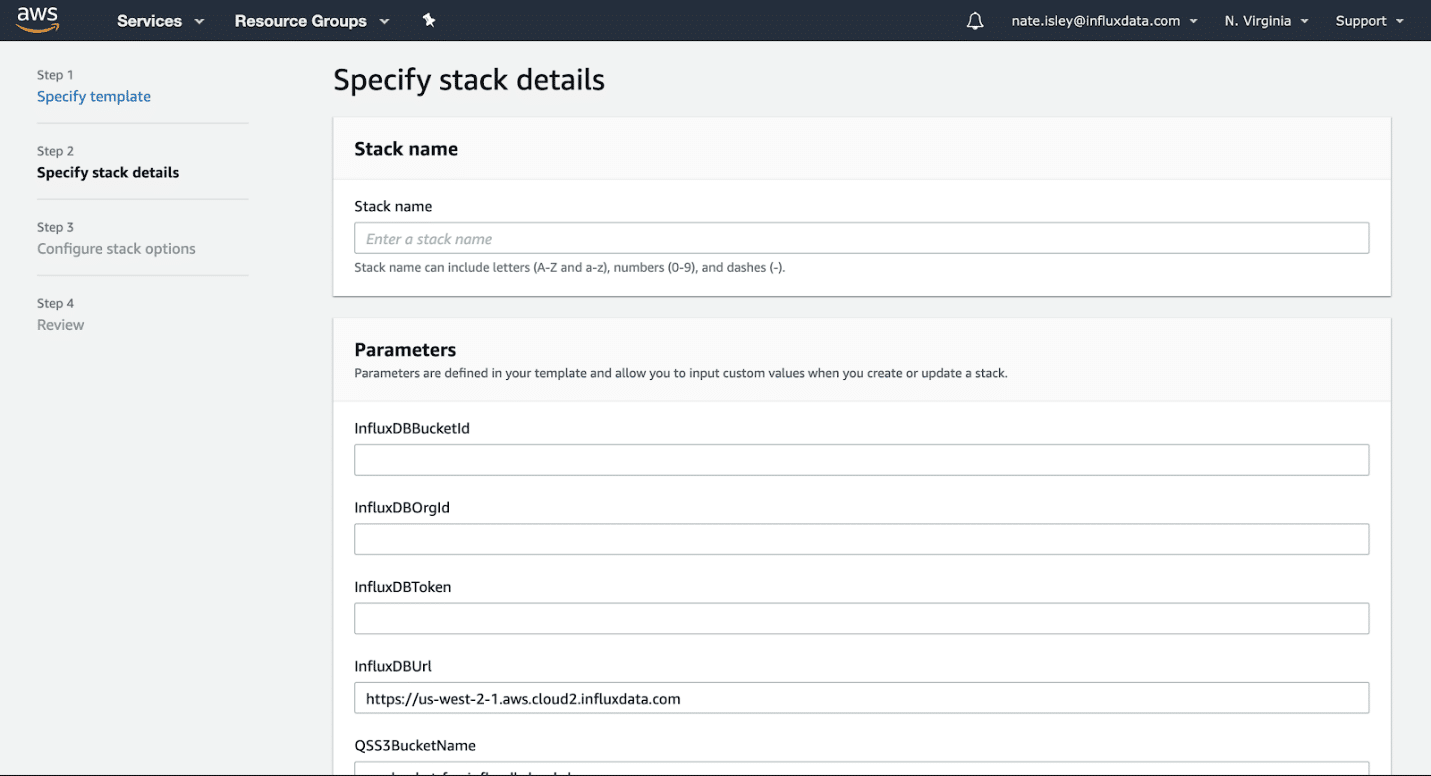
Click Next, and then name your stack. Provide the following InfluxDB details:
- Your organization ID
- Bucket ID of the bucket the Lambda writes to
- Token with permission to write to the bucket
- Your InfluxDB URL
There are also two other parameters (QSS3BucketName, QSS3KeyPrefix) with default values that you should not change. These parameters are helpers for asset copying.
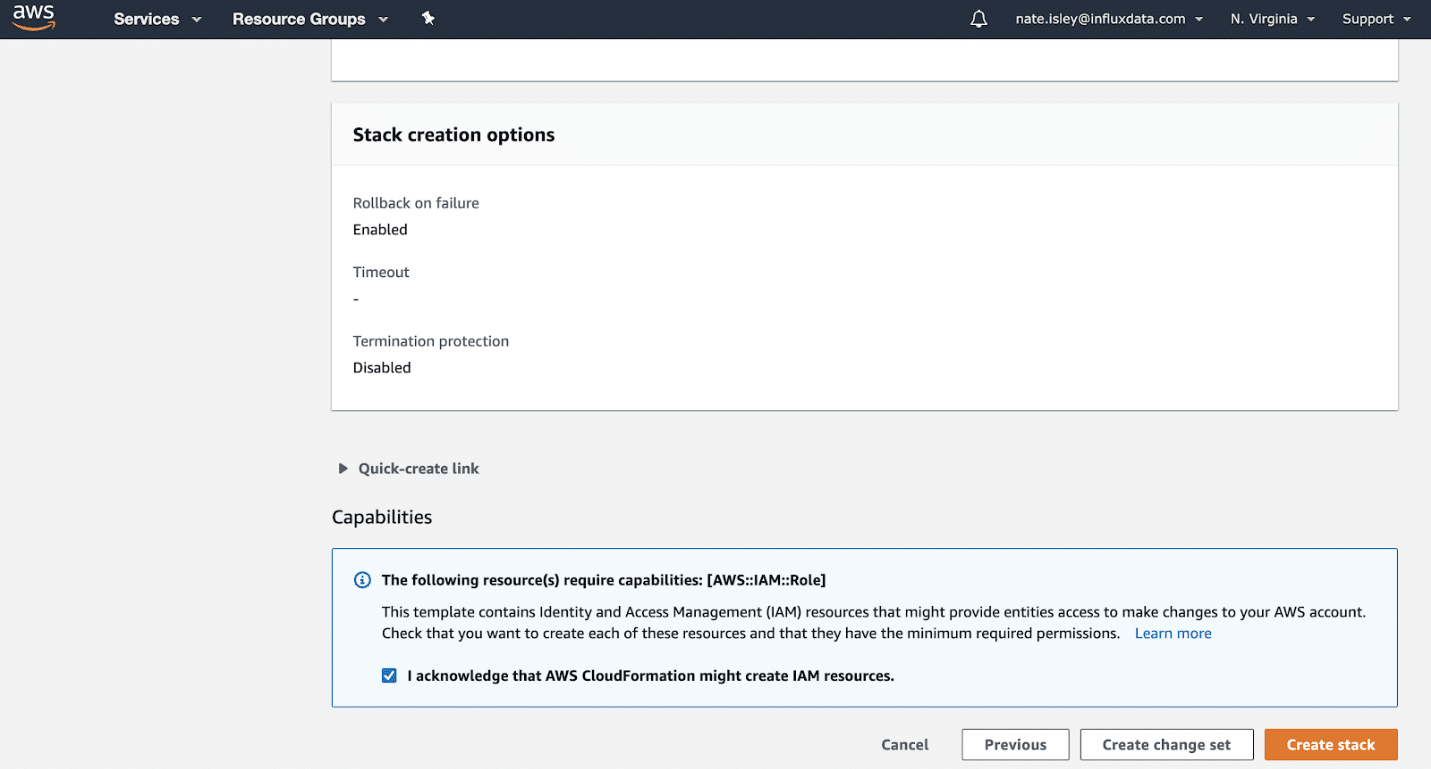
On the Specify stack details page, leave the fields blank and then click Next. Select I acknowledge creating this stack will create resources, and then click Create stack.
After a few minutes, the stack deploys to your region. To navigate to your new Lambda, click Services -> Lambda. On the Lambda functions page, you should see your new Lambda listed there. The CopyZipsFunction is the helper copy function, and the GeoPythonLambda does the data collection and writing work:
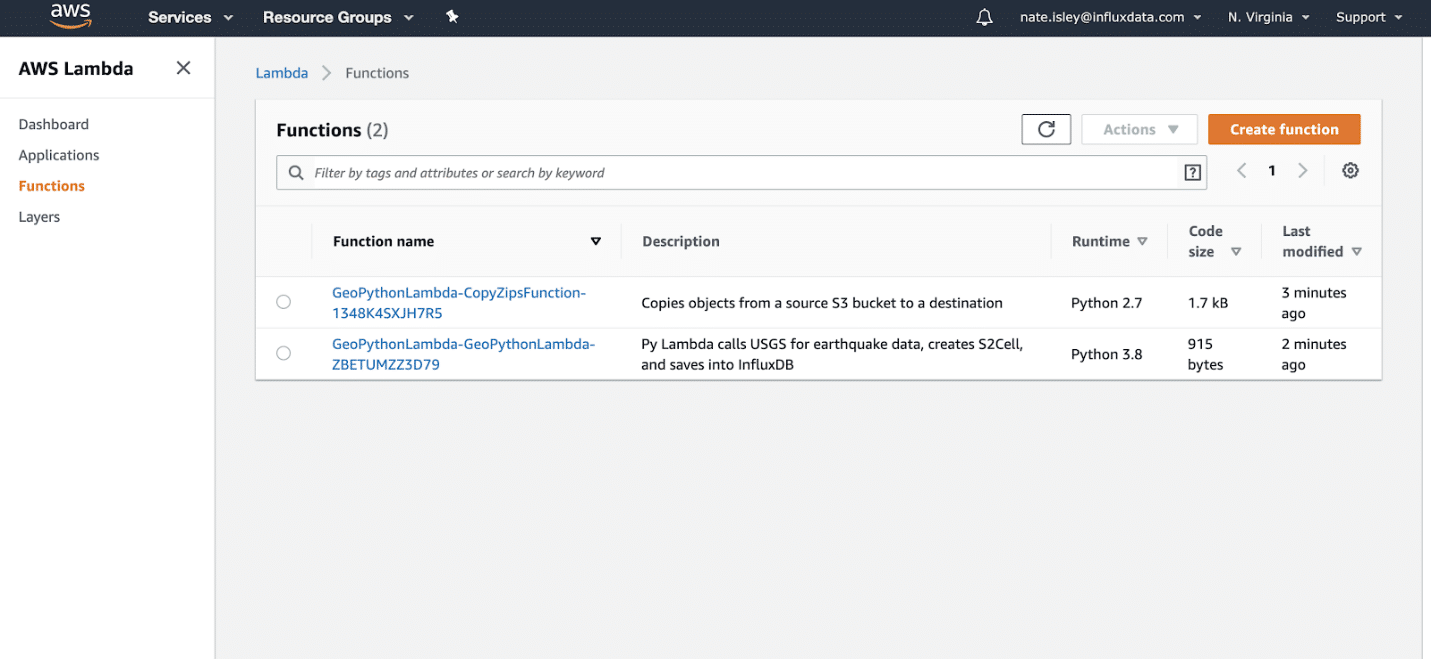
GeoPythonLambda should run every hour based on the AWS Rule we set up, but you should test and confirm it works. To test, click GeoPythonLambda, and then click Test. Test requires an input definition, but this Lambda has no input requirements, so click through and save the default dataset.
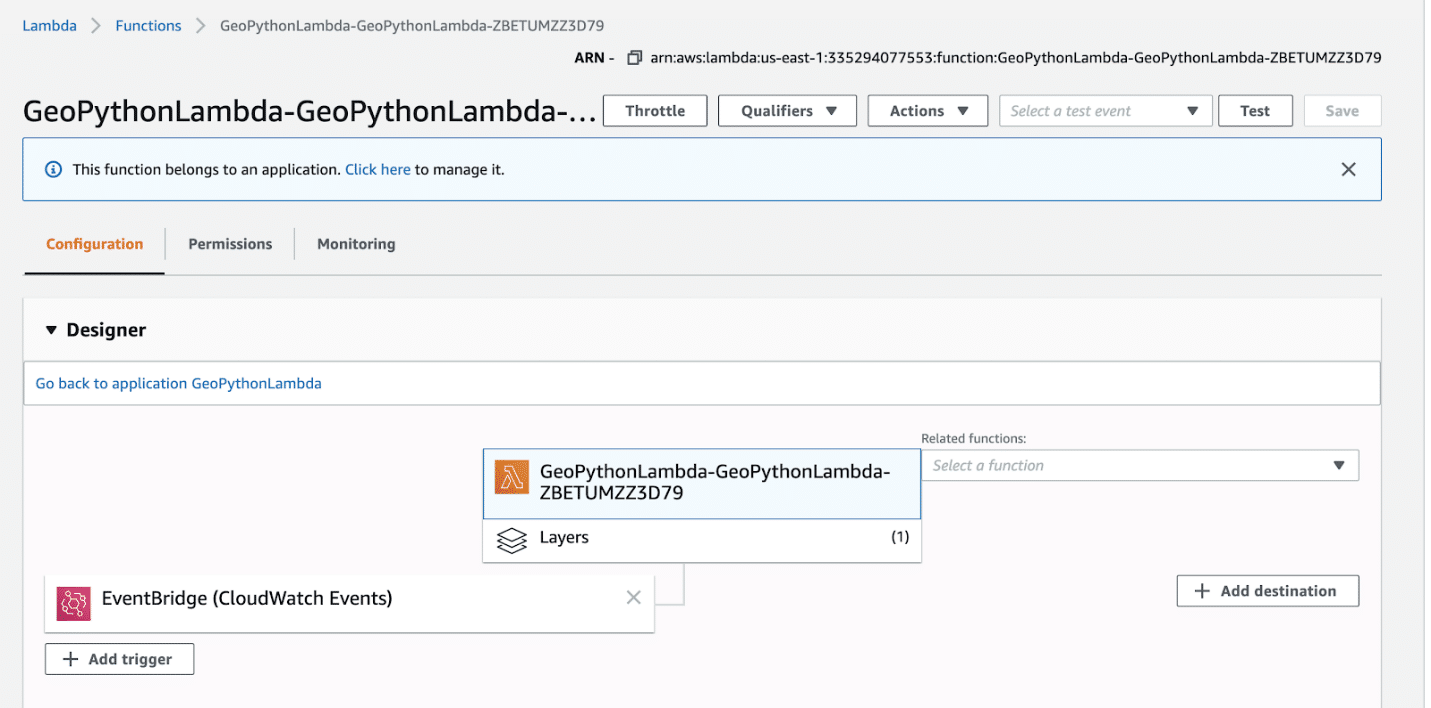
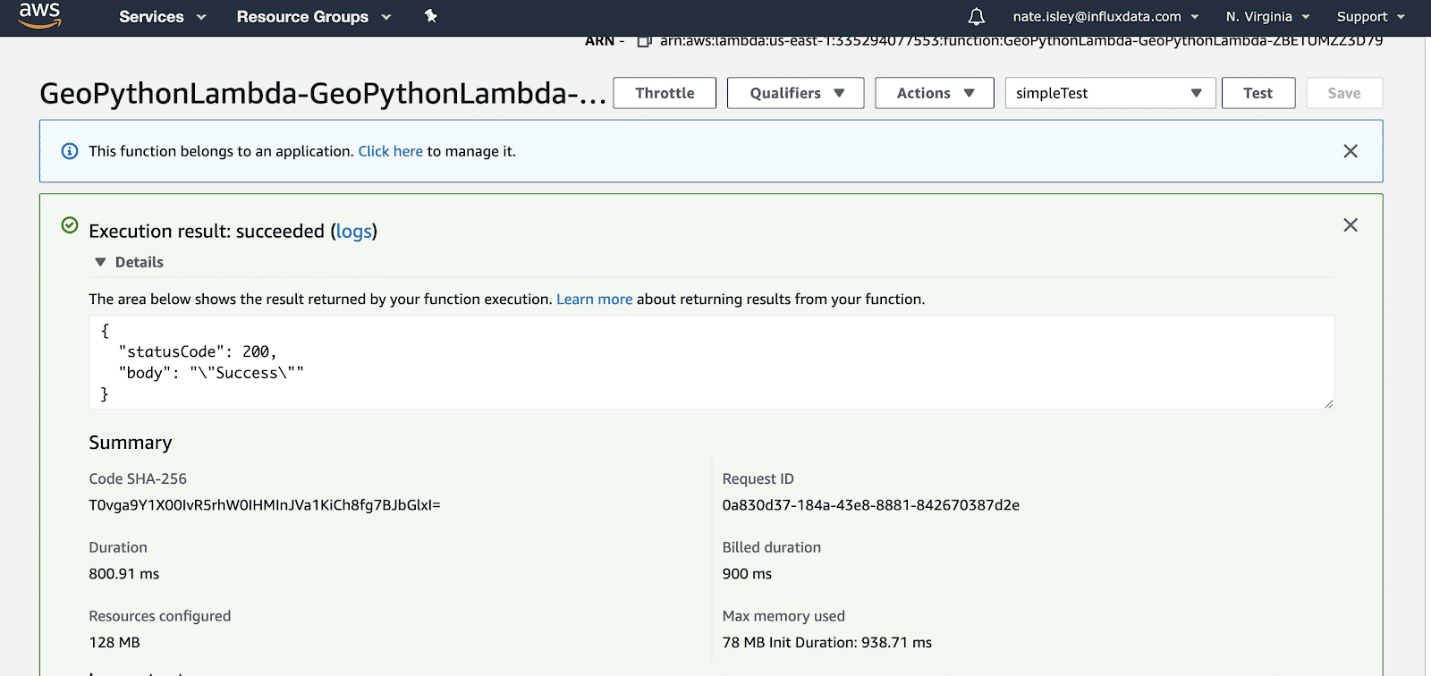
Here is what you should expect after a successful test a green Execution result: succeeded.
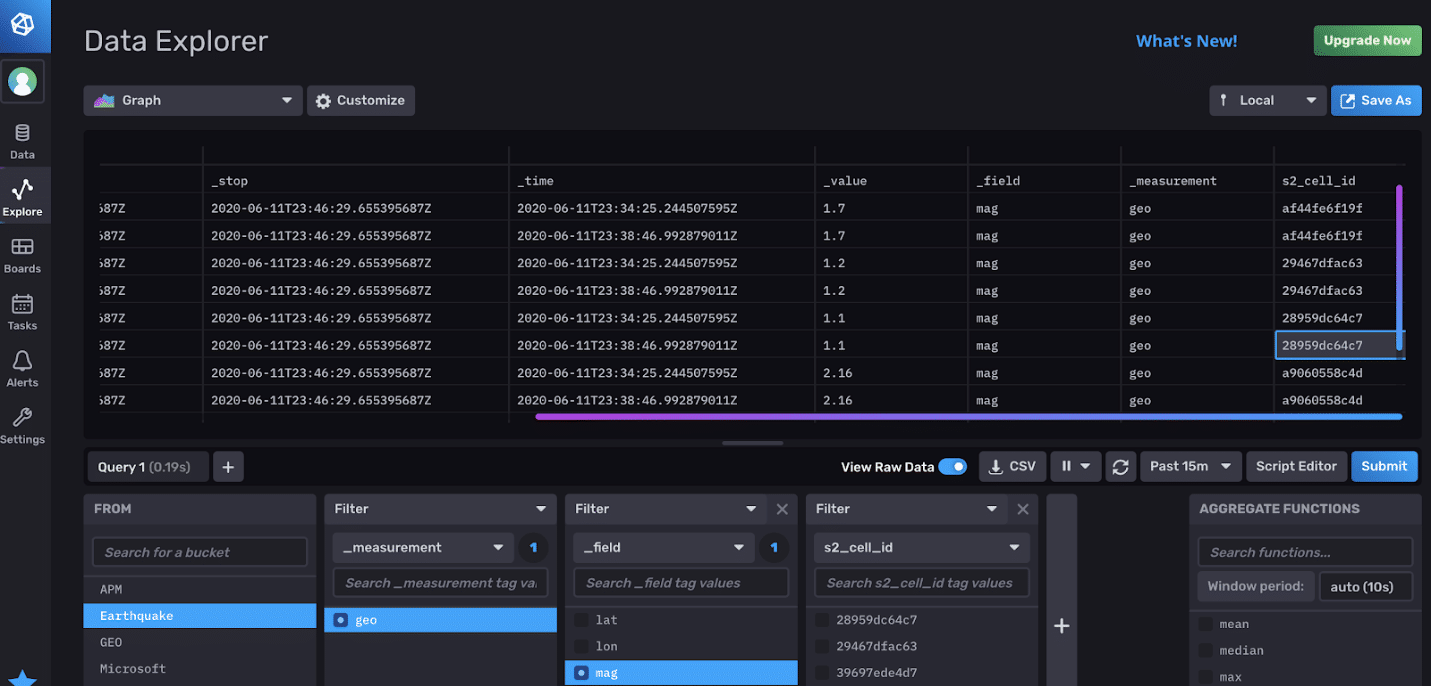
With the data points written, when you log into your InfluxDB UI, you’ll be able to explore the geolocation earthquake data.
What else?
As an aside, now that the layer asset with the Python client library is in your environment/region, you can easily create new Lambdas and experiment with the client. Create a new Python 3.8 Lambda and select Layers and Add a layer.
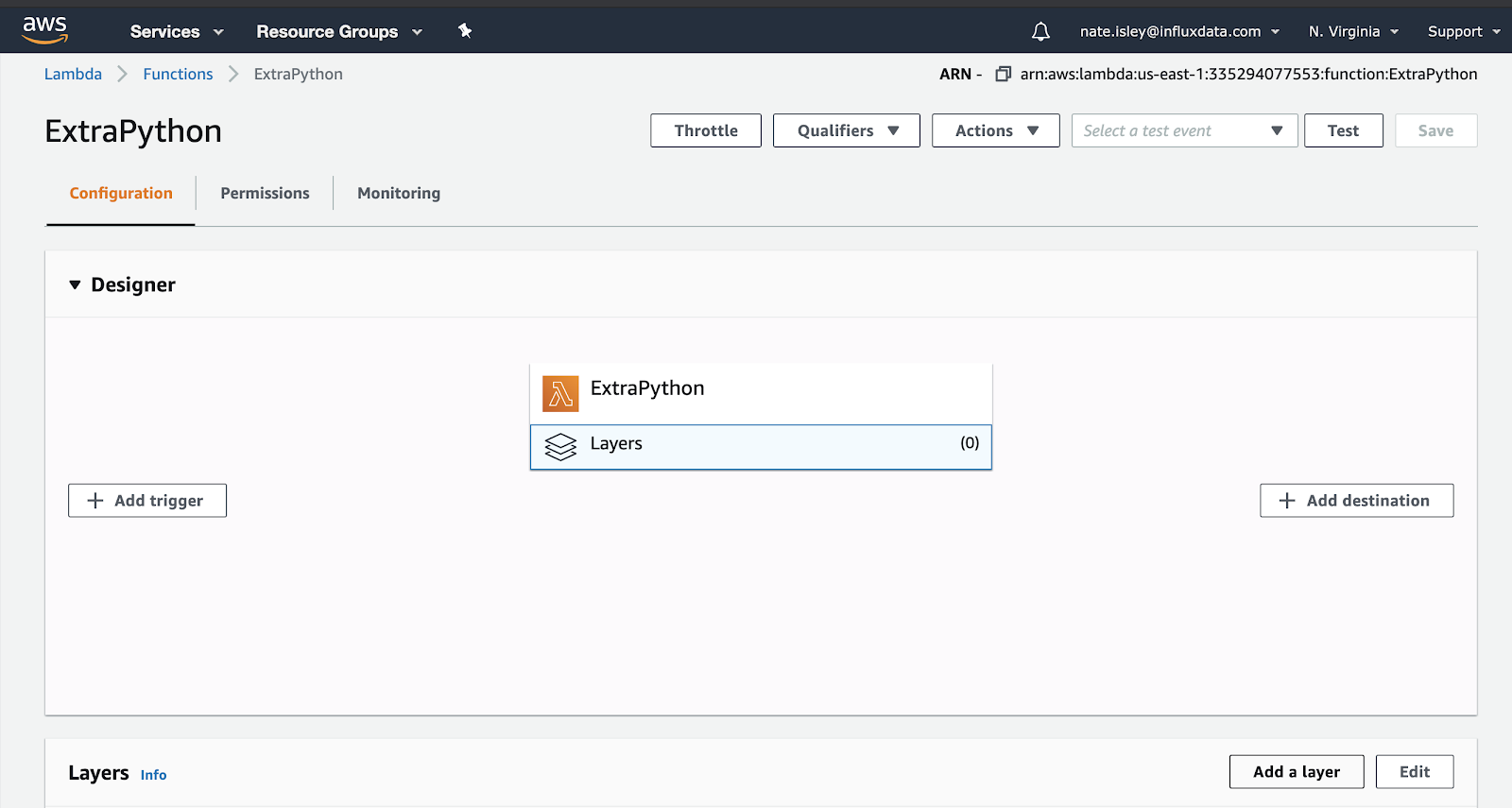
In Add layer to function, “my-layers” is an option under the list of runtime compatible layers:
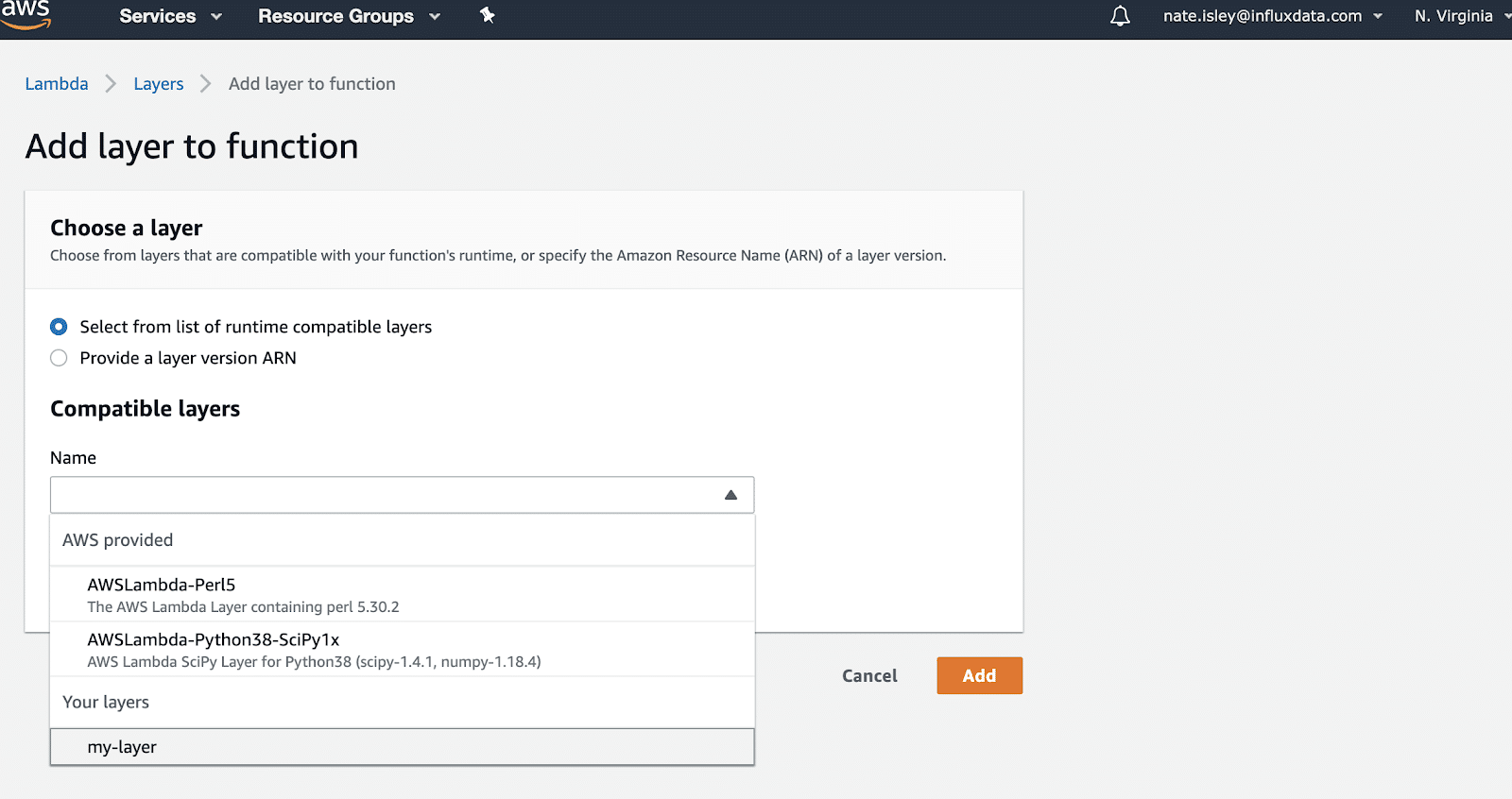
Once added, import and use the client library in any of your Lambda code.
What's next?
This blog covered how to distribute a data collector on AWS via CloudFormation. If you have data collection needs and workloads that run on AWS, this template could jumpstart your AWS stack creation efforts.
Apart from a data collection discussion, this Lambda also directly supports an in-depth review of Flux’s new geo-temporal query capabilities. Now that you have the USGS earthquake data reporting in, you can explore using Flux to analyze your data over time and space.
As always, if you have questions or feedback, please reach out to me in our community forum or join us in Slack!
