Table of Contents
Over the past few years, the IoT community has embraced InfluxDB as a cornerstone of the solutions they build. Whether modernizing or greenfield, InfluxDB has helped many in working with vast quantities of sensor and device data as we continue to deliver on our promise of time to awesome for IoT.
Today, let’s look at why you should consider InfluxDB for your IoT data architecture, how to plan your IoT architecture, and what we’ve built recently to make InfluxDB even better at handling IoT data.
So, let’s dive in!
Why use InfluxDB for IoT telemetry?
It boils down to a few things:
- Proven. Every IoT device generates time series data, and the explosion of these devices and the data they generate, fueled by the desire for more analytics, has driven the requirements for this type of data to be handled by a specialized platform. InfluxDB has proven its chops at some of the most demanding IoT customers in the world, such as Siemens and PTC, as a time series database at the core of their IoT stack.
- Scalable. IoT data volumes and the appetite to consume them are rapidly growing. InfluxDB scales to ingest and index massive volumes of IoT telemetry, while providing real-time analytics and fast query response times.
- Extensible. IoT telemetry comes in a wide variety of formats across many domains legacy standards, new datatypes, and everything in between. InfluxDB can ingest a broad range of data formats. If you need a format that isn't supported, InfluxDB's extensibility lets you ingest it.
- Flexible. InfluxDB's Flux language is incredibly powerful for building IoT solutions, since it gives you a single language to both shape and query your IoT data, and does so at the database layer so that you don't have to resort to expensive queries to download data to modify it.
- Contextual. InfluxDB blends rich metadata, such as IoT asset information, into time series measurements, making it easier to derive insights on past, current and future performance of assets and processes.
Every IoT use case is a time series use case
IoT - Internet of Things - is increasingly broad. The pace of deployment of sensors across nearly every industry from agricultural to oil & gas, power generation, and transportation, allows us access to time-stamped information at about the same efficiency with which products are made or grown, the potential need for maintenance and repairs, and more. Here are just a few examples to explore what’s possible today:
- Connected fleets: Solar power companies such as BBOXX regularly send measurements on the voltage produced by each of their installations, so they can tell when a particular one is in need of repair — sometimes before end customers themselves know.
- Smart spaces : Office tower managers like Aquicore track the amount of energy consumed across all floors of a building, a "Smart City" example of optimizing the amount of energy required to provide a comfortable environment for occupants.
- Smart products: Office water dispensers, for instance Bevi, measure the amount of flavoring used, so that their service personnel can automatically restock flavorings just before they run out.
IoT data architecture
We’ve had a large number of customers successfully use InfluxDB for IoT across a range of industries, but two architectural patterns continually emerge:
- Hub only
- Edge and hub
Hub-only IoT data architectures are where each of your “things” send their IoT telemetry to a central time series database (such as InfluxDB Cloud) for storage, enrichment and analysis. All devices are assumed to have a reliable, performant Internet connection to send their IoT telemetry, and thus all consumers of that data access it from that centralized database.
For example, tado°, a provider of connected home thermostats for efficient cooling and heating, sends all their thermostat telemetry to InfluxDB Cloud. tado° customers access their home’s temperatures from tado°’s mobile app, which pulls data from InfluxDB. This hub-only data architecture works given that a home thermostat will always be located within coverage of a house’s WiFi router.

Credit: tado°
Edge and hub data architectures are required when a piece of equipment doesn’t have a network connection that is fast and reliable, and where people are onsite and require access to the analytics to assist in operational decision making, while centralized visibility across all of the potential edge sites can be leveraged to understand trend analysis, operational efficiencies or identify potential issues. In these cases, it makes sense to dual-write time series telemetry to an onsite time series database, as well as to a centralized instance.
For example, Equinor, an energy producer, operates oil rigs in the North Sea. Their oil rigs require near real-time visibility into various aspects of the rig so that it can be run properly. In this case, it makes sense for Equinor to deploy InfluxDB on oil rigs, in order to make this data accessible to rig operators.
At the same time, these oil rigs transmit time series telemetry data often at a lower resolution than is being captured and stored locally to their corporate headquarters. The corporate HQ folks can analyze the data from all of the rigs and look at the similarities and differences between the operational characteristics of the equipment in the aggregate. This allows for analyses like predictive maintenance to be performed and those recommendations sent back to the rig operators. We find the edge-and-hub pattern especially common in use cases for IIoT (industrial IoT) and factories implementing Industry 4.0.

So, when planning your IoT data architecture, ask yourself which model makes the most sense for you and your organization’s needs. Speaking of questions…
How to plan your IoT data architecture
There are eight types of questions to consider when planning your IoT data architecture; here they are:
Data & decisions: What kind of IoT data are you collecting, and what decisions are being driven by this data? You’ll likely have three kinds of decisions to consider:
- Past: How did we perform previously? What impact did this have on quality, efficiency, or quantity, and what changes (if any) does it suggest? This analysis can be especially useful when rolled up across multiple sites (factories, wind turbines, etc.).
- Current: How are we performing right now? Are there corrective actions that need to be taken? These kinds of decisions are often taken by onsite operational staff.
- Future: How are we likely to perform in the future, based on the data we've seen so far? This can help drive decisions on predictive maintenance, by using data on mileage or usage to determine when a piece of equipment will need to be repaired or replaced.
Data & storage: Which data makes sense to be stored in a relational database, and which should be stored in a time series database? Data that changes over time, such as sensor readings (temperature, pressure, voltage, etc.) is typically best in a time series database.
However, data that is static over time, such as IoT asset metadata like machine IDs, sensor ID, make, model, purchase date, last repair date, or location of fixed equipment, is typically best stored in a relational database. After all, rewriting the same unchanging information over and over into a time series database would be a waste of storage.
When your time series data and metadata are stored in separate databases, it’s important to be able to blend this metadata into your time series data to provide context for better analysis — and we’ll see how to do that below.
It’s also crucial to work with a time series database that gives you a choice of cloud vendors and locations for storing your IoT data. This gives you the freedom to use whichever vendor has the cloud services you need, and the flexibility to address whatever data residency requirements you have. InfluxDB Cloud does this, running on AWS, Azure, and Google, in several regions globally (and we’re continually expanding).

Data & location: If you are using a hub-and-edge pattern, which data do you store at the edge, and which at the hub? For onsite operators to do their job, which data do they need, at what frequency does it need to be collected (once a second, every 10 seconds, etc.), and at what frequency does it need to be visualized to be best understood? Similarly, for analysts at corporate to do their job, what data do they need, how often does it need to be sent from edge to hub, and at what resolution?
Networks & data resolution: How does network performance and availability come into play in terms of when the data is sent, and what kinds of rollups are required? For example, BBOXX provides solar to developing countries and needs to collect data over slow 2G cellular networks; in these cases, downsampling data is often required. This is different from, say, tado°, where each connected thermostat is located next to a fast, reliable WiFi connection, which means that data can be sent more frequently, with less need for downsampling.

Data volumes: How many sensors are deployed, how often do they send data, how many IoT measurements and events do they send, and what (if any) downsampling is done? All this affects the amount of data you’ll need to ingest in a time series database. If you plan to store data at the edge using an onsite time series database, like InfluxDB OSS, you’ll need to plan your computing resource consumption (memory, disk, CPU) and size your hardware accordingly. And if you plan on storing data at the hub using InfluxDB Cloud, you don’t have to plan on how to scale, since InfluxDB Cloud scales automatically; simply use its usage-based pricing to determine your budgeted spend.
Existing data architecture: What are you currently using to transmit time series data from sensors? What (if anything) are you using to persist that data? And what are you using to store your static data (sensor ID, etc.)? You’ll want to choose a time series platform that provides you with plenty of options to fit with your current architecture, and give you options to upgrade your architecture in the future. (More on that below.)
Existing performance: How well is your existing data architecture performing? In the past, we’ve seen companies and organizations struggle to ingest the sheer volume of time series data they produce. This led Aquicore, which manages office buildings with IoT sensors, to switch off Postgres and move to InfluxDB for time series data. Query speeds also matter, both for onsite operators that need real-time telemetry to make critical adjustments, as well as corporate analysts looking to discern trends in large datasets. Query performance led tado° to switch from MySQL to InfluxDB, since the latter provided a 200x reduction in query times.
Architecture & authority: Even the best architecture can be derailed without taking human and organizational factors into account. You want to understand who has authority and influence over decisions around data architecture, including who has a stake in keeping things as-is, and who is pushing for change. This includes looking broadly at people both in OT (operational technology) and IT (information technology), and both in the field (factories, power plants, etc.) and at corporate offices. If you’re in a regulated industry, it may include people on legal and compliance teams, who may want data transformed to remove PII (personal identifying information) more on that below.

What's new with InfluxDB and IoT
Over the past months, we’ve invested in expanding our product-market fit for IoT customers with devices in motion as well as fixed equipment. This includes investments in geotemporal data enrichment that are available today, and visualizations (maps) that will be landing soon in InfluxDB Cloud.
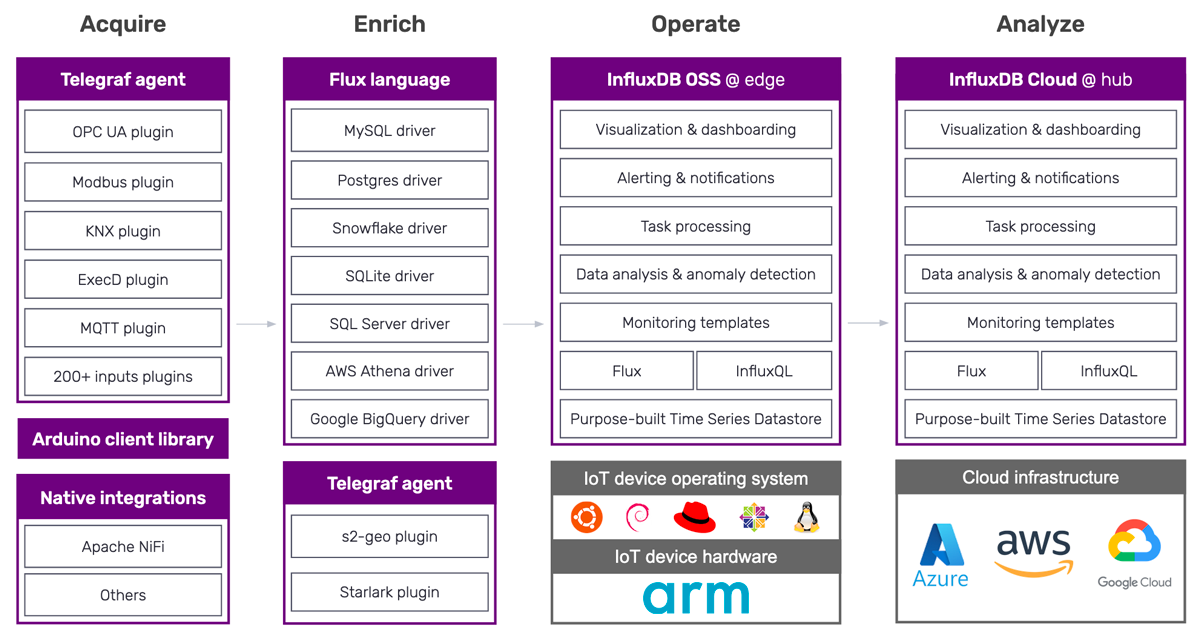
These IoT-related product investments span our time series data platform, which includes:
- Telegraf, to acquire and enrich IoT telemetry data
- InfluxDB Cloud, to persist, enrich, and analyze IoT data at the hub
- InfluxDB OSS, to persist, enrich, and analyze IoT data at the edge
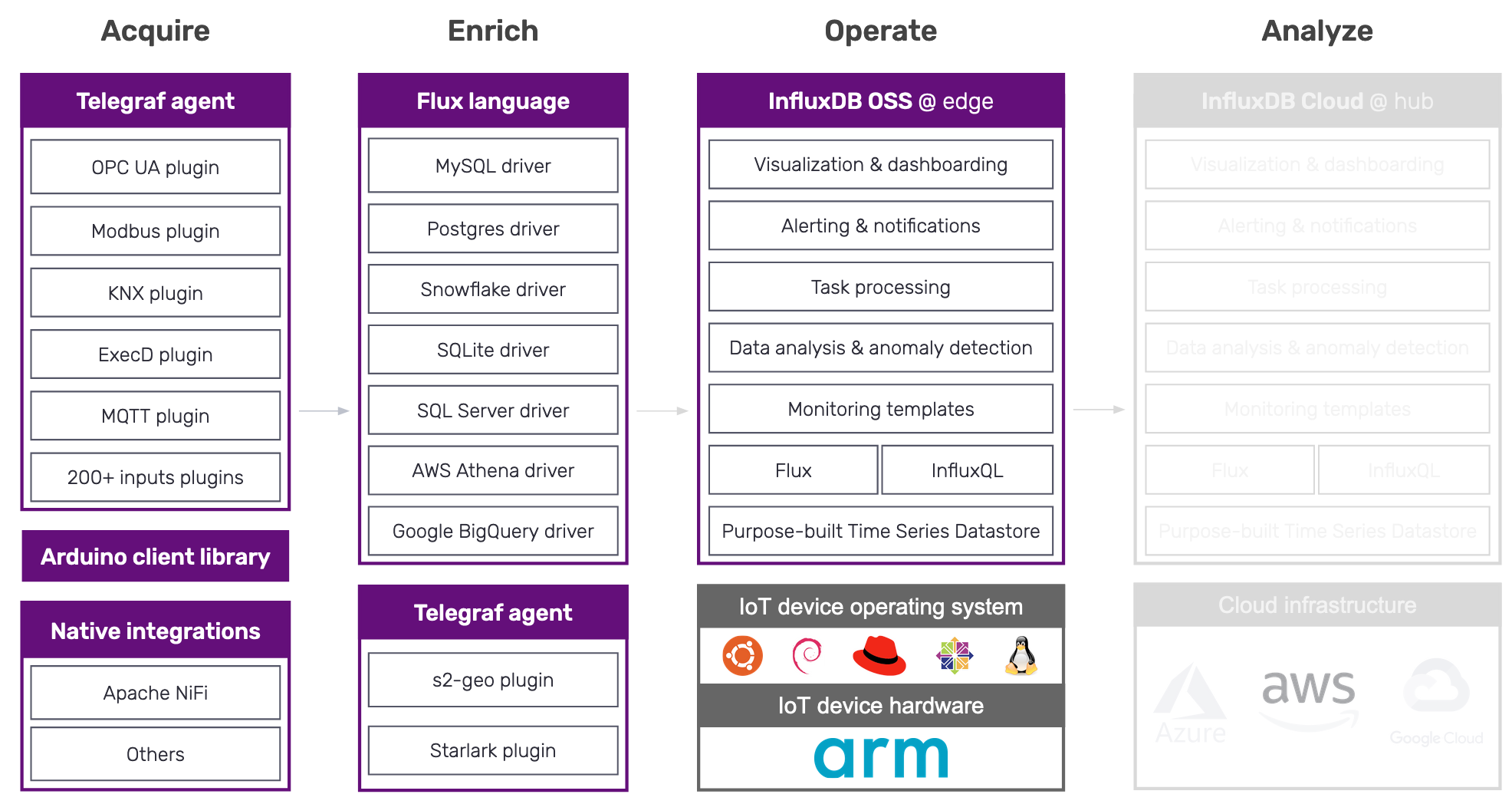
And they break into four areas: Acquire, Enrich, Operate, and Analyze.
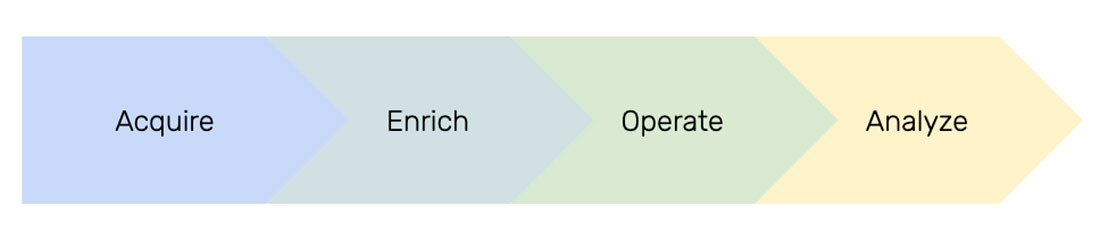
Let’s jump in and look at each.
Acquire IoT telemetry data
We’ve worked hard to enhance Telegraf and InfluxDB so that you have the flexibility to connect to a broad range of existing IoT sensors and devices. With these enhancements, InfluxDB can:
- Acquire data from the majority of commonly used IIoT (industrial IoT) telemetry protocols like OPC-UA;
- Support open, standards-based protocols like MQTT; and
- Provide extensibility to gather data from other protocols.
Our recent additions include the following:
- Telegraf OPC-UA plugin (connects to many systems, including PTC Kepware)
- Telegraf Modbus plugin
- Telegraf KNX plugin (coming soon in Telegraf 1.19)
These enhancements are in addition to the following longstanding capabilities - a pretty long list that reflects the breadth and diversity of the IoT market shown above, including:
- Telegraf MQTT plugin
- Telegraf AMQP plugin
- Telegraf Azure Event Hub plugin
- Telegraf RTI DDS plugin
- Native integrations between InfluxDB and Apache NiFi, openHAB, WinCC, Node-RED, Particle.io
- ..and many more
Also, InfluxDB offers a rich set of APIs enabling virtually any system or device (using a variety of programming languages) to send data to and query from the data store.
Here’s a graphic to summarize our IoT-related data acquisition capabilities:
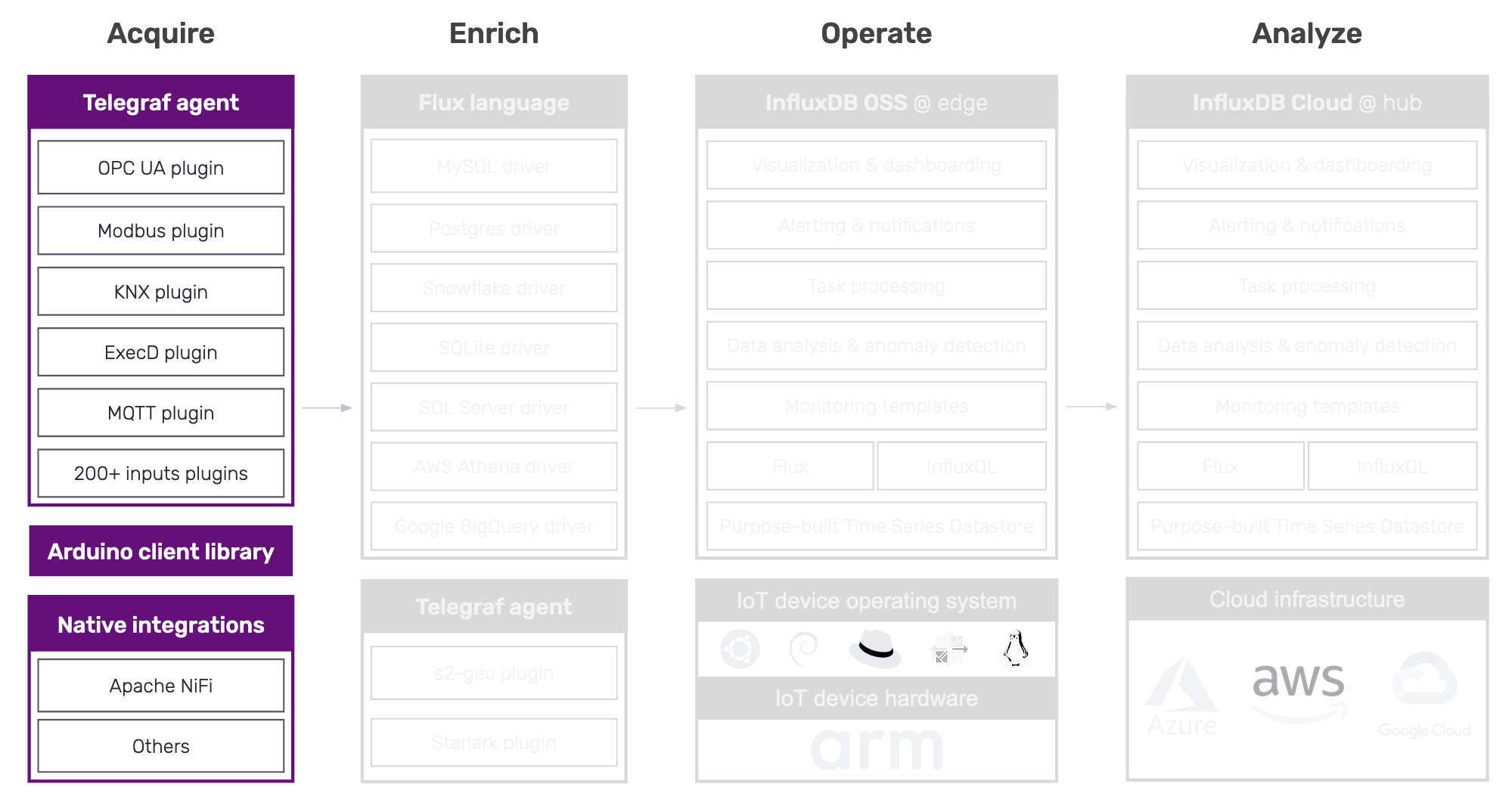
Even with the above breadth of support and the over 200 Telegraf input plugins, there may still be datasources we don’t yet support. In these cases, submit a feature request on the Telegraf repo or leverage the extensibility through Telegraf’s ExecD integration shim.
Enrich IoT telemetry data
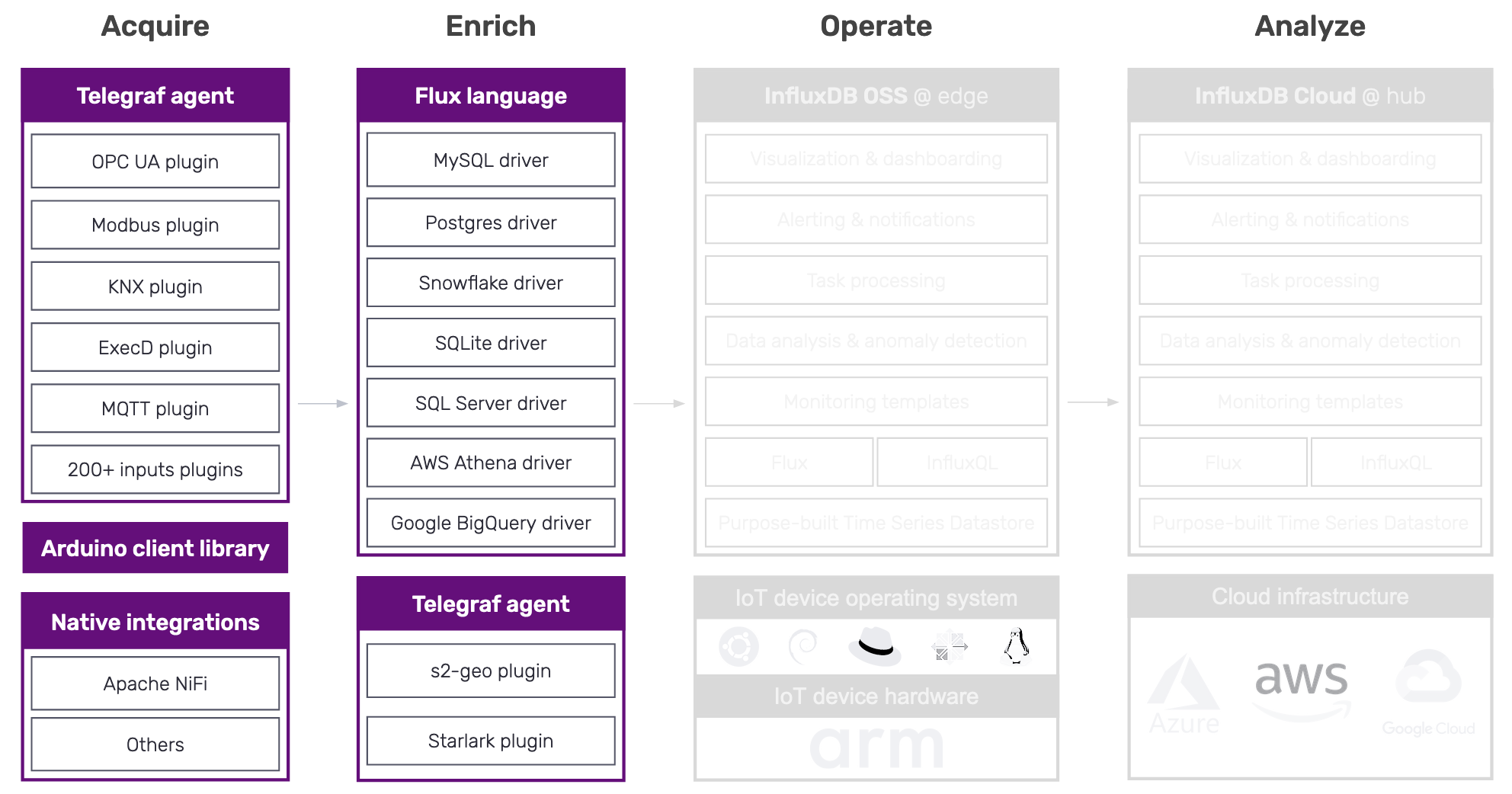
Over the past year, we’ve been enhancing InfluxDB to let you combine IoT asset metadata - again, things like machine IDs and sensor IDs - with IoT time series telemetry to provide a human-readable view of device status and health. There are three ways you can enrich IoT telemetry with InfluxDB:
- Metadata enrichment
- Geospatial enrichment
- Calculated values enrichment
Let’s cover each.
Metadata enrichment. Here’s an example. In InfluxDB line protocol, you could have the following time series data point for a wind turbine:
turbineVoltage, turbineID=1234 voltage=150 1556813561098000000
If you’re a human, this doesn’t tell you a whole lot. How big is this turbine? Is it producing its expected output? If not, when was it last serviced? Does it need to be taken offline soon?
But let’s say that you have a relational database that contains turbineID as a primary key for your turbines table, with columns for turbine make, model, and last service date. In this case, you can query your relational databases for metadata, then join it to your time series data, while keeping your relational database credentials secret. All this you can do using Flux, InfluxDB’s language for working with time series data.
Once you have this richer relational-plus-time-series view of data, questions like the above are much easier to answer. Over the past year, we’ve added support for a broad range of relational databases, including PostgreSQL, MySQL, Snowflake, SQLite, Microsoft SQL Server, AWS Athena, Google BigQuery, MariaDB, and CockroachDB. This allows you to add metadata from a broad set of sources, but if there are others you’d like us to support, please let us know by submitting an issue in the Flux repository.

Geospatial enrichment. Often, IoT telemetry will contain the latitude and longitude of a device, and you’ll want to use this data to filter telemetry by a particular location. Because IoT data volumes can be huge, it’s important to ensure that these geospatial queries run as quickly as possible.
Flux’s geotemporal query functions can leverage a specialized geospatial index, which can be calculated at data collection time or at query time from the raw lat/lon data dynamically, if necessary.
Calculated values enrichment. Sometimes you need to enrich time series telemetry with calculated values. For instance, you might want to use your time series telemetry on electrical current and resistance to calculate voltage, using the formula voltage = current * resistance. Or convert imperial measurements like Fahrenheit, miles, or pounds to their corresponding metric values. Or reduce the precision of IoT measurements.
At ingest time, you can add calculated values to your incoming time series telemetry using the Telegraf Starlark plugin. And you can add calculated values to your existing time series data using InfluxDB Tasks and the Flux map() function.
Here’s a graphical summary of what we’ve covered so far around IoT data acquisition and enrichment:
Operate using local IoT telemetry data
As mentioned, sometimes it’s helpful to store IoT telemetry data onsite or on-vehicle, so equipment operators have high resolution data available in real-time, without any concerns around network performance.
To support these use cases, InfluxDB OSS (open source software) is a good option, since it provides a complete time series data platform (storage, analysis, tasks, dashboards, and alerting) in a single lightweight binary. This full range of functionality makes InfluxDB OSS a good choice for intelligent edge use cases.
Since there are a broad range of IoT devices that run on ARM processors, we’ve recently ported InfluxDB to ARM 64 to provide you with more deployment flexibility. Now you can go to our download page to get InfluxDB binaries for Ubuntu, Debian, RHEL, and Centos running on ARM 64-bit systems such as a Raspberry Pi 4 series, and there are ARM 64 Docker images for InfluxDB as well.
And if you’re running Windows 10, InfluxDB OSS will soon run on that as well - so stay tuned!
Here’s what we’ve covered so far:
Analyze IoT telemetry data
Once your data is ingested and enriched, it’s time to analyze it to drive decisions, such as those listed above. And for that, we’ve recently made some significant strides; here are two.
Geotemporal data. InfluxDB now lets you run geotemporal queries, both for fixed and mobile assets. For instance, you might want to understand which vehicles’ engines are performing properly? What’s been the output of all our factories, solar farms, or wind turbines? And so on.
In these cases, you can query InfluxDB by geographic location using the Flux Geo package. And soon, you’ll be able to visualize those results on a map in your InfluxDB Cloud Data Explorer and Dashboards. Below is an example.
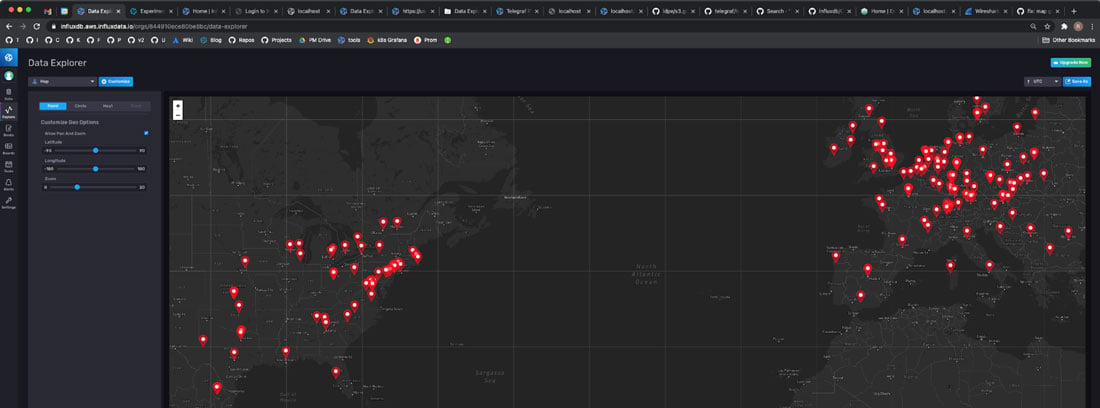
The Flux Geo package is very flexible: you can find all points within a radius of a particular point, a rectangle, a single point, or a polygon of an arbitrary shape (such as the boundary of a city, state, or country). And you can combine geotemporal filtering with many other types of Flux functions.
Extensible analytics. One of the reasons we created Flux was that we wanted a language that was easy to extend. Across the range of IoT domains above, there is a correspondingly broad range of analytic functions we can add to Flux. One of these is a Flux function to calculate OEE (overall equipment effectiveness), a standard for measuring manufacturing productivity. For instance, an OEE score of 100% means you are manufacturing only good parts, as fast as possible, with no stop time.

OEE is but one example of Flux’s extensibility. If there are other analytical functions you’d like us to add to Flux, submit an issue in the Flux repository.
To sum up, here’s a diagram of all four categories of IoT-related investments in our product line:
Our IoT product philosophy
What you’ve seen above are the first steps in a longer journey of IoT capabilities, so I’d like to share the thinking behind what we’re building so that InfluxDB works as a foundational element of your IoT data architecture:
Time to awesome for IoT: Since our founding, InfluxData has been focused on making it easy to work with time series data. We’ve continued to follow this principle as we’ve expanded deeper into meeting the needs of our IoT and IIoT customers, by striving to provide the right mix of ease-of-use, power, and extensibility to our time series platform.
Self-managed and as-a-Service: We realize that there’ll be a range of requirements and use cases across our customer base. Some of you will want the flexibility to assemble your own IoT telemetry platform using the components above. Or you might want a pre-assembled IoT platform; if so, check out PTC ThingWorx, which uses InfluxDB as its time series database.
Greenfield and brownfield: Some of our customers have the luxury of starting with a blank page when it comes to formulating their IoT data architecture; we call them the greenfield customers. But many others, the brownfield, have decades-old legacy IIoT historians that can’t handle the exponential growth of IoT telemetry data, and the appetite across the organization to consume it. We have to meet the needs of both our green- and brownfield customers, by supporting both older and newer technologies. And this includes coexisting with legacy historians when necessary.
Incremental modernization: In live industrial settings, no one ever changes everything all at once. It’s too disruptive to operations. Instead, we see incremental modernization, for instance, when new PLCs (programmable logic controllers) that arrive as old equipment is replaced. We need to provide an IoT telemetry platform that grows with our customers.
Partnering with domain experts: We understand that IoT is a broad range of domains, and so we partner with a range of IoT experts to deliver IoT solutions to our joint customers. In addition to PTC, these include Nortal, Factry RTI, Particle, Seeq, and Rockwell. Do reach out to them as needed!
To sum up, we see InfluxDB as a core piece of a modern IoT stack that meets the above requirements.
Conclusion
Now that you’ve seen common IoT deployment patterns, architectures, use cases, and how InfluxDB addresses them, here’s what to do next:
- Sign up for a free InfluxDB Cloud account and follow our getting started guide, which provides a tutorial.
- Review our whitepapers on IoT and IIoT.
- Learn from other IoT and IIoT customers.
And of course, feel free to engage our ever-helpful InfluxDB community and Slack for questions. Enjoy!
