MQTT vs Kafka: An IoT Advocate's Perspective (Part 1 - The Basics)
By
Jay Clifford
updated December 14, 2025
Use Cases
Developer
Navigate to:
With the Kafka Summit fast approaching, I thought it was time to get my hands dirty and see what it’s all about. As an advocate for IoT, I heard about Kafka but was too embedded in protocols like MQTT to investigate further. For the uninitiated (like me) both protocols seem extremely similar if not almost competing. However, I have learned this is far from the case and actually, in many cases, they complement one another.
In this blog series, I hope to summarize what Kafka and MQTT are and how they can both fit into an IoT architecture. To help explain some of the concepts, I thought it would be practical to use a past scenario:
In the previous blog, we discussed a scenario where we wanted to monitor emergency fuel generators. We created a simulator with the InfluxDB Python Client library to send generator data to InfluxDB Cloud. For this blog, I decided to reuse that simulator but replace the client library with an MQTT publisher and Kafka producer to understand the core mechanics behind each.
You can find the code for this demo here.
Understanding the basics
So what is Kafka? Kafka is described as an event streaming platform. It conforms to a publisher-subscriber architecture with the added benefit of data persistence (to understand more of the fundamentals, check out this blog). Kafka also promotes some pretty great benefits within the IoT sector:
- High throughput
- High availability
- Connectors to well-known third-party platforms
So why would I not just build my entire IoT platform using Kafka? Well, it boils down to a few key issues:
- Kafka is built for stable networks which deploy a good infrastructure
- It does not deploy key data delivery features such as Keep-Alive and Last Will
Having said this, let’s go ahead and compare implementations of writing a basic Kafka producer and compare it to an MQTT publisher within the context of the Emergency generator demo:
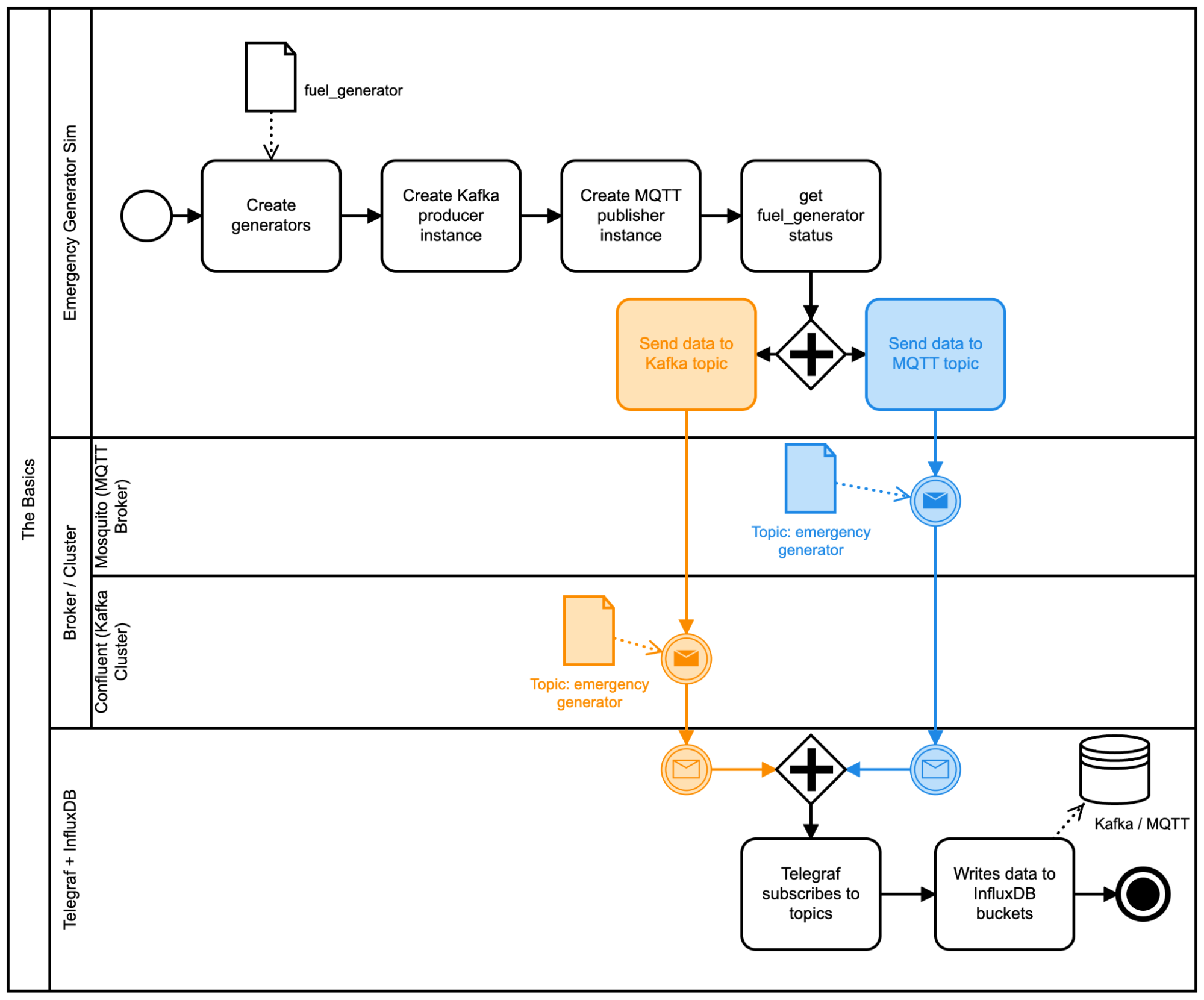
Assumptions: For the purposes of this demo, I will be making use of the Mosquitto MQTT Broker and the Confluent platform (Kafka). We will not cover the initial creation/setup here, but you can consult these instructions accordingly:
- Mosquito Broker
- Confluent (I highly recommend using the free trial of Confluent Cloud to sense check if Kafka is right for you before bogging yourself down in an on-prem setup)
Initialization
Let’s start with the initialization of our MQTT publisher and Kafka producer:
MQTT
The minimum requirements for an MQTT Publisher (omitting security) are as follows:
- Host: The address / IP of the platform hosting the Mosquitto server
- Port: Which port will the MQTT producer talk to. Usually 1883 for basic connectivity, 8883 TLS.
- Keep Alive Interval: The amount of time in seconds allowed between communications.
self.client.connect(host=self.mqttBroker,port=self.port, keepalive=MQTT_KEEPALIVE_INTERVAL)
Kafka
There was a little more background work when it came to Kafka. We had to establish connectivity to two different Kafka entities:
- Kafka cluster: This is a given we will be sending our payload here.
- Schema registry: The registry lies outside the scope of the Kafka Cluster. It handles the storing and delivery of topic schemers. In other words, this forces producers to deliver data in a format that is expected by the Kafka consumer. More on this later.
So let’s set up connectivity to both entities:
Schema registry
schema_registry_conf = {'url': 'https://psrc-8vyvr.eu-central-1.aws.confluent.cloud',
'basic.auth.user.info': <USERNAME>:<PASSWORD>'}
schema_registry_client = SchemaRegistryClient(schema_registry_conf)The breakdown:
- url: The address of your schema registry. Confluent supports the creation of registries for hosting.
- authentication: Like any repository, it contains basic security to keep your schema designs secure.
Kafka cluster
self.json_serializer = JSONSerializer(self.schema_str, schema_registry_client, engine_to_dict)
self.p = SerializingProducer({
'bootstrap.servers': 'pkc-41wq6.eu-west-2.aws.confluent.cloud:9092',
'sasl.mechanism': 'PLAIN',
'security.protocol': 'SASL_SSL',
'sasl.username': '######',
'sasl.password': '######',
'error_cb': error_cb,
'key.serializer': StringSerializer('utf_8'),
'value.serializer': self.json_serializer
})The breakdown:
- bootstrap.servers: In short, the address points to Confluent Cloud hosting our Kafka Cluster; more specifically, a Kafka broker. (Kafka also has the notation of brokers but on a per-topic basis). Bootstrap is a reference to the producer establishing its presence globally in the cluster.
- sasl.*: Simple security authentication protocol; these are a minimum requirement for connecting to Confluent Kafka. I won't cover this here, as it is of no interest to our overall comparison.
- error_cb: Handles Kafka error handling.
- key_serializer: This describes how the message key will be stored within Kafka. Keys are an extremely important part of how Kafka handles payloads. More on this within the next blog.
- Value.serializer: We will cover this next, in short, we must describe what type of data our producer will be sending. This is why defining our schema registry is very important.
Topics and delivery
Now that we have initiated our MQTT publisher and Kafka producer, it’s time to send our Emergency generator data. To do this, both protocols require the establishment of a topic and data preparation before delivery:
MQTT
Within MQTT’s world, a topic is a UTF-8 string that establishes logical filtering between payloads.
| Topic Name | Payload |
| temperature | 36 |
| fuel | 400 |
In Part 2 of this series, we break down the capabilities and differences of MQTT and Kafka topics in further detail. For now, we are going to establish one topic to send all of our Emergency Generator data (this is not best practice but is logical in the complexity build-up of this project).
message = json.dumps(data)
self.client.publish(topic="emergency_generator", message)MQTT has the benefit of being able to generate topics on demand during the delivery of a payload. If the topic already exists, the payload is simply sent to the established topic. If not, the topic is created. This makes our code relatively simple. We define our topic name and the JSON string we plan to send. MQTT payloads by default are extremely flexible, which has pros and cons. On the positive side, you do not need to define strict schema typing for your data. On the other hand, you rely on your subscribers being robust enough to handle the incoming messages which fall out of the norm.
Kafka
So I must admit, I came in with foolish optimism that sending a JSON payload via Kafka would be as simple as publish(). How wrong I was! Let’s walk through it:
self.schema_str = """{
"$schema": "http://json-schema.org/draft-07/schema#",
"title": "Generator",
"description": "A fuel engines health data",
"type": "object",
"properties": {
"generatorID": {
"description": "UniqueID of generator",
"type": "string"
},
"lat": {
"description": "latitude",
"type": "number"
},
"lon": {
"description": "longitude",
"type": "number"
},
"temperature": {
"description": "temperature",
"type": "number"
},
"pressure": {
"description": "pressure",
"type": "number"
},
"fuel": {
"description": "fuel",
"type": "number"
}
},
"required": [ "generatorID", "lat", "lon", "temperature", "pressure", "fuel" ]
}"""
schema_registry_conf = {'url': 'https://psrc-8vyvr.eu-central-1.aws.confluent.cloud',
'basic.auth.user.info': environ.get('SCHEMEA_REGISTRY_LOGIN')}
schema_registry_client = SchemaRegistryClient(schema_registry_conf)
self.json_serializer = JSONSerializer(self.schema_str, schema_registry_client, engine_to_dict)
self.p = SerializingProducer({
'bootstrap.servers': 'pkc-41wq6.eu-west-2.aws.confluent.cloud:9092',
'sasl.mechanism': 'PLAIN',
'security.protocol': 'SASL_SSL',
'sasl.username': environ.get('SASL_USERNAME'),
'sasl.password': environ.get('SASL_PASSWORD'),
'error_cb': error_cb,
'key.serializer': StringSerializer('utf_8'),
'value.serializer': self.json_serializer
})The first task on our list is to establish a JSON schema. The JSON schema describes the expected structure of our data. In our example, we define our generator meter readings (temperature, pressure, fuel) and also our metadata (generdatorID, lat, lon). Note, within the definition, we define their data types and which data points are required to be sent with each payload.
We have already discussed connecting to our schema registry earlier. Next, we want to register our JSON schema with the registry and create a JSON serializer. To do this we need three parameters:
- schema_str: the schema design we discussed
- schema _registry_client: Our object connecting to the registry
- engine_to_dict: The JSON serializer which allows you to write a custom function for building out a Python dictionary struct which will be converted to JSON format.
The json_serializer object is then included within the initialization of the Serializing Producer.
Finally to send data we call our producer object:
self.p.produce(topic=topic, key=str(uuid4()), value=data, on_delivery=delivery_report)
To send data to our Kafka cluster we:
- Define our topic name (Kafka by default requires the manual generation of topics. You can, via settings within the broker/cluster, allow auto-generation).
- Create a unique key for our data, the data we wish to publish (this will be processed through our custom function and delivery report (a function defined to provide feedback on successful or unsuccessful delivery of the payload).
My first impression of strongly typed / schemer-based design was: “Wow, this must leave system designers with a lot of code to maintain and a steep learning curve”. As I implemented the example, I realized you would probably avert a lot of future technical debt this way. Schemers force new producers/consumers to conform to the current intended data structure or generate a new schema version. This allows the current system to continue unimpeded by a rogue producer connecting to your Kafka cluster. I am going to cover this in more detail within Part 2 of this blog series.
Prospective and conclusion
So, what have we done? Well, in its most brutally simplistic form we have created a Kafka producer and MQTT publisher to transmit our generator data. At face value, it may seem Kafka seems vastly more complex in its setup than MQTT for the same result.
At this level, you would be correct. However, we have barely scraped the surface of what Kafka can do and how it should be deployed in a true IoT architecture. I plan to release two more blogs in this series:
- Part 2: I cover more of the features unique to Kafka, such as a deeper look into topics, scalability and third-party integrations (including InfluxDB).
- Part 3: We take what we have learned and apply best practices to a real IoT project. We will use Kafka's MQTT proxy and delve deeper into third-party integrations to get the most out of your Kafka infrastructure.
Until then check out the code, run it, play with it, and improve it. Next blog (Part 2 of this series) we cover topics in more detail.
