Infrastructure Monitoring with InfluxDB | Live Demonstration
Database Indexing
Updated March 08, 2024
The index of a database table acts like the index in a physical textbook. On this page, we will learn what database indexing is and more.
What is database indexing?
The index of a database table acts like the index in a physical textbook. Just like consulting the index of a book lets you go straight to the relevant page, a database index lets you retrieve a specific record without going through every row in a table. Database indexing improves the speed of data retrieval. By creating extra data structures to maintain the index, database indexes optimize the querying of tables that can have thousands or even millions of rows.
Why database indexing is needed
The presence of database indexes improves several operations on a table. The following list describes some of the important uses of database indexes.
-
Reading data from tables with a large number of rows: When executing a simple SELECT query for a specific row in a table, the database management system might have to look through every record to find that row. In very large tables, like one with over 100,000 rows, searching through every record would result in poor performance. If the index contains a pointer to a specific row, it speeds things up by preventing the query from searching the entire table.
-
Providing a unique key: Most SQL database engines create a default index using the primary key column from a table. This column expects a unique value for each row. As a result, when you create a primary key column for indexing, you also get a unique key that can serve as an ID to identify a specific row throughout the rest of an application. For example, an ID column of a table containing student registration numbers might hold the value for a specific student’s unique registration number.
-
Improving record sorting: The index for a column is sorted in a logical order. Thus, SQL queries that ORDER results in either ascending (ASC) or descending (DESC) order experience a boost in performance if the query uses the indexed column in its ORDER BY statement.
-
Speeding up look-ups: Besides the SELECT query, using an indexed column in a WHERE clause can speed up lookup for UPDATE and DELETE queries. In other words, indexes can prevent the database system from looking through all the rows in a table when it only needs to update or delete specific rows.
How database indexing works under the hood
By default, an SQL database looks up specific rows from a table by scanning the table. A table scan, also called a sequential scan, means reading each row in a table in sequential order. Then, a WHERE clause tests specific columns for the condition queried.
That scenario occurs when querying a table without an index. Database indexing eliminates the need for sequential reads. Instead, the index file contains pointers to the row with the key value. The index is a sorted list, hence, it’s easier for the database system to search through its records.
In a clustered index, data is broken down into smaller nodes in a tree format, as shown below:
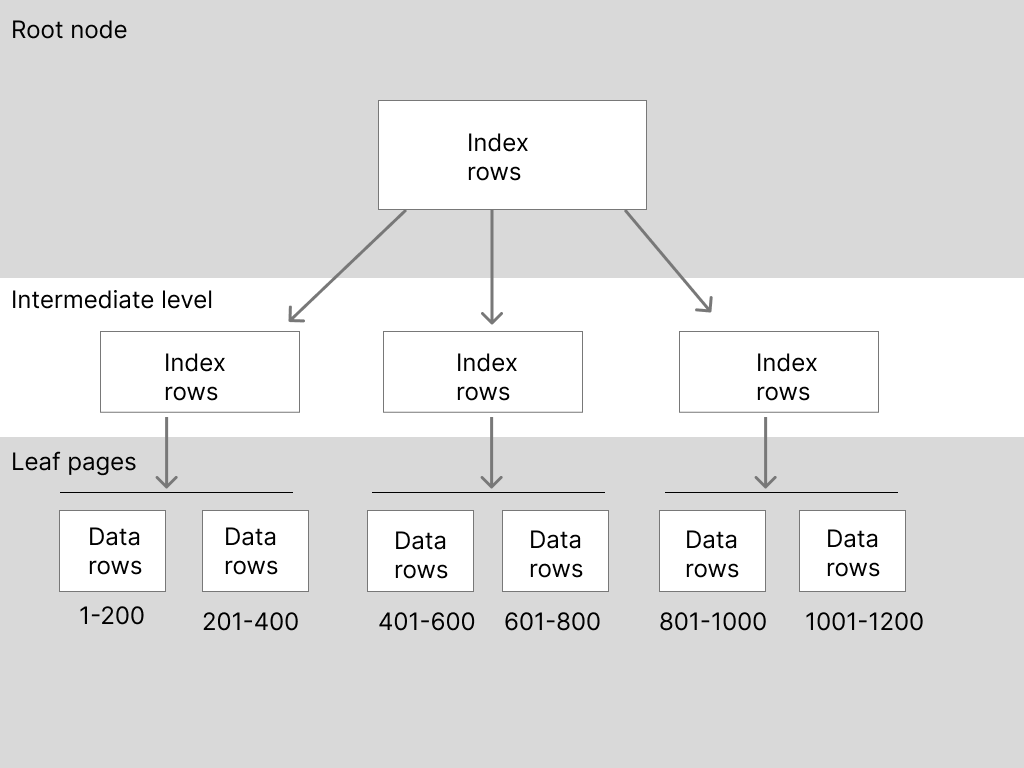
Here, the index has three nodes at the intermediate level. Each node contains its own set of data leaves. Each leaf page contains 200 data rows, and in order to fetch data within a specific range, the request moves through each level, passing through only the nodes that lead to the data. For example, to retrieve a row with key 805, the search starts at the root node and passes through the third intermediate index row, down to leaf pages 801–1000. As a result, there’s less actual disk I/O as compared to a full table scan.
Clustered vs. non-clustered indexing
For most SQL databases like MySQL and SQL Server, an index is either a clustered index or a non-clustered index.
A clustered index is also called a primary index in SQL database engines like MySQL. This is partly because the clustered index uses the primary key column for the index. Because each table can have only one primary index per table, each table can also have only one clustered index.
Non-clustered indexes are secondary indexes. Instead of using the primary key column to index the database, a non-clustered index can be created from any column you intend to use in your WHERE clause to speed up lookups. Non-clustered indexes can use multiple columns depending on the database design requirements. As a result, you can have more than one clustered index for a single table.
How to create an index in a database table
There are two main ways to create an index for a table. The first option uses a primary key column. The other option creates an index from any column that will be used to search for specific rows. It is possible to create indexes for tables without data; for our examples, we’ll focus on a table with no data.
How to create an index using a primary key
Creating an index using a primary key is as easy as adding a column with the primary key constraint to a table.
To create a table of students with an ID column that will serve as both the primary key and index, run the following SQL query:
CREATE TABLE students(id int PRIMARY KEY, full_name varchar(100) NOT NULL, date_of_birth date);
This query creates a new table called students in a MySQL database. It also generates an index for the ID column of the new table.
To verify that this query creates an index for the students table, run the following SQL query:
SHOW INDEX FROM students;
The following screenshot shows the result of running the SHOW INDEX query.
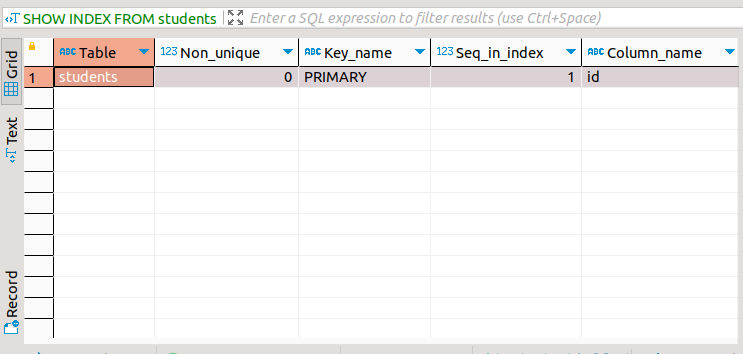
Flagging a column as the primary key for a table is sufficient to create a primary index, also called a clustered index. However, because there can be only one primary key column per table in MySQL, you can only use a single column for this type of index. The next example shows how to create an index with multiple columns.
How to create an index using any column
You can create new indexes in a table using just about any column. Also, you can create multiple indexes using multiple columns. However, creating indexes for too many columns can slow down write operations like UPDATE because you will need to update the indexes during writing.
For example, to create a new index using the full_name column from the students table in the previous example, you could run the following query:
CREATE INDEX idx_fullname ON students (full_name);
After running the query, you can run the SHOW INDEX query to verify that there is a new index.
The result for SHOW INDEX should show two indexes, as in the screenshot below.
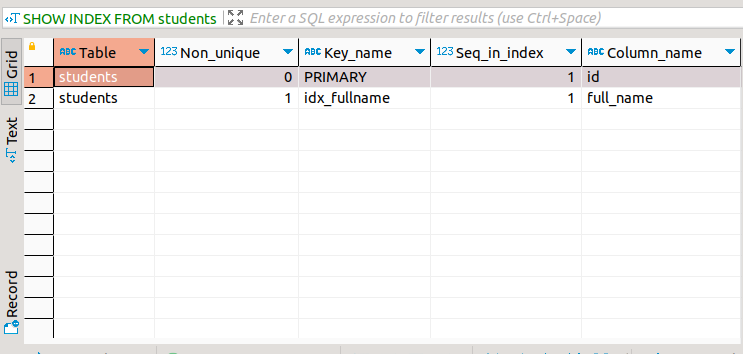
To use either the index in the first or second example, you can add the columns id or full_name to a WHERE clause for SELECT, DELETE, or UPDATE.
Engineered for performance.
Designed for flexibility.
Related resources

Free InfluxDB Training
Jump start your InfluxDB journey with free self-paced & instructor-led training.

Developer Education
Free training to get up and running quickly
