Infrastructure Monitoring with InfluxDB | Live Demonstration
Distributed Tracing
Updated March 08, 2024
Tracing is a method for understanding how interconnected components of a distributed system interact with each other.
What is distributed tracing?
Tracing is a method for understanding how interconnected components of a distributed system interact with each other. The interconnectedness of processes and services means that some may depend on others within an application or process. As a result, errors, delays, and bottlenecks in one (or multiple) area can impact overall system performance.
Tracing reveals how all these different pieces work in concert. A trace provides a view of a request, task, operation, job, or other useful unit of work, as it works its way through a distributed system. Any number of subtasks (algorithms, network calls, database transactions, cache queries, etc) coordinate to satisfy the request. Each of these subtasks is a span.
A trace consists of a collection of spans that provide timing information on the finer details of a request.
How does tracing work?
Spans have zero to many sub-spans, called child spans, or children. Child spans can have their own children, and so forth.
A trace begins with a root span. The root span has no parent span and because it is the recursive parent of all other spans in the trace, the duration of the root span represents the total time of the trace.
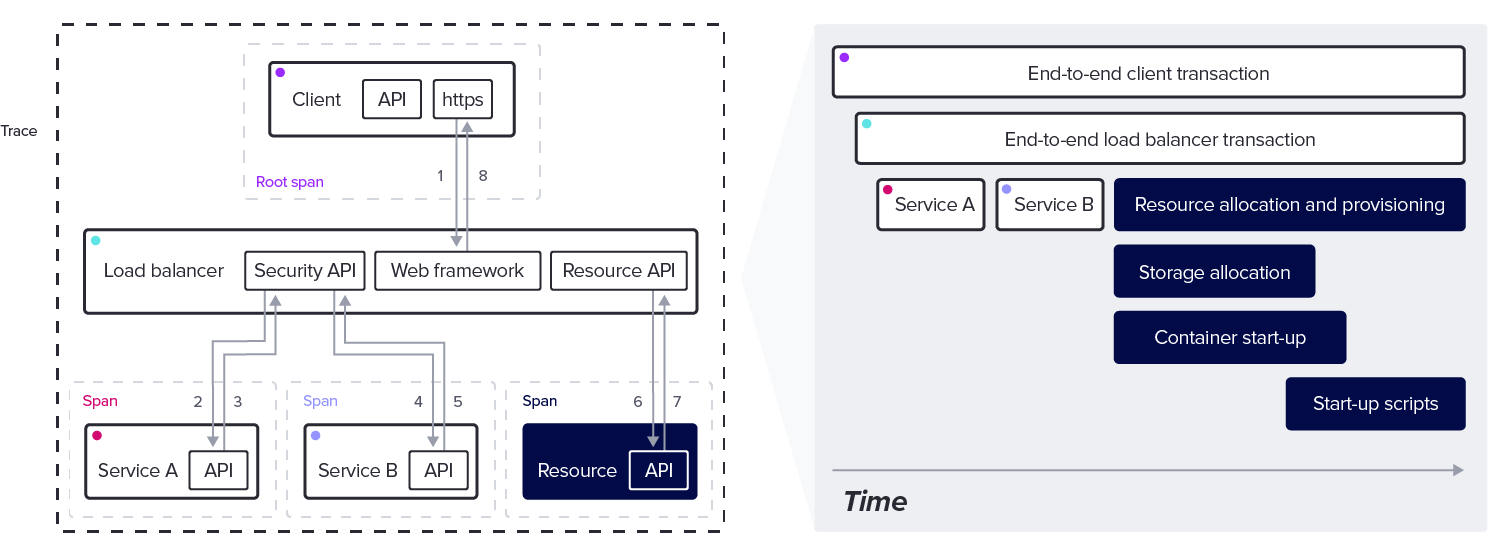
As the diagram indicates, a single trace contains a lot of potential spans.
Every span needs identifying information to ensure that the trace can piece all the data together properly. Each span has a trace ID, a span ID, and, when applicable, a parent span ID.
These building blocks create a hierarchical tree of subtasks that provide the key structure for building traces.
Tracing with InfluxDB
Because every span contains a unique ID, tracing data is high cardinality time series data. InfluxDB’s time series merge tree (TSM) engine struggled with high cardinality tracing data, but its updated storage engine solves the cardinality problem, making InfluxDB an ideal solution for storing and analyzing tracing data.
Engineered for performance.
Designed for flexibility.
Related resources

Free InfluxDB Training
Jump start your InfluxDB journey with free self-paced & instructor-led training.

Developer Education
Free training to get up and running quickly
