Infrastructure Monitoring with InfluxDB | Live Demonstration
Apache Parquet
Apache Parquet is an open source columnar data file format that supports different encoding and compression schemes to optimize it for efficient data storage and retrieval in bulk.
Apache Parquet is an open source columnar data file format that emerged out of Cloudera designed for fast data processing of complex data. Initially built to handle the data interchange for the Apache Hadoop ecosystem, it has since been adopted by a number of open source projects like Delta Lake, Apache Iceberg, and InfluxDB, as well as big data systems like Hive, Drill, Impala, Presto, Spark, Kudu, Redshift, BigQuery, Snowflake, Clickhouse, and others. Many of these projects are built around object storage with Parquet files and an elastic query tier that processes those files.
Parquet supports different encoding and compression schemes on a per-column basis that allow for efficient data storage and retrieval in bulk. Dictionary and run-length encoding (RLE) are also supported as well as a wide variety of data types like numerical data, textual data, and structured data like JSON. Parquet is self-describing and allows for metadata (such as schema, min/max values, and Bloom filters) to be included on a per-column basis. This helps the query planner and executor to optimize what needs to be read and decoded from a Paquet file.
Additionally, it is built around nested data structures using the record shredding and assembly algorithm first described in the Dremel paper that came out of Google.
Apache Parquet is part of the Apache Arrow project, and therefore it has support for a wide number of languages including Java, C++, Python, R, Ruby, JavaScript, Rust, and Go.
Advantages of Parquet
Performance — I/O and compute are reduced because a subset of the columns can be scanned when performing queries. Per-column metadata and compression help with this.
Compression — Organizing homogeneous data into columns allows for better compression. Dictionaries and run length encoding provide efficient storage for repeated values.
Open Source — Robust open-source ecosystem, constantly being improved and maintained by a vibrant community.
How Parquet stores data
Let’s use an example to see how Parquet stores data in columns. The following is a simple data set of 3 sensors with information about the IDs, the type, and location. When you save as a row-based format like csv or Arvo, it looks like this:

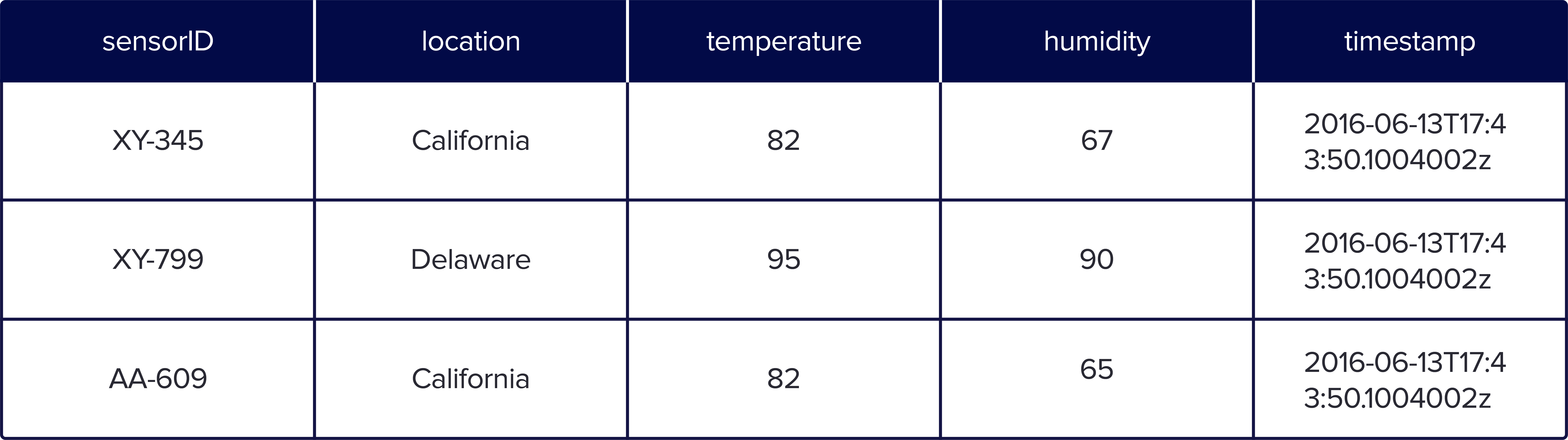
When you store it in Parquet columnar format, your data is organized with each specific data type in a column like the following:
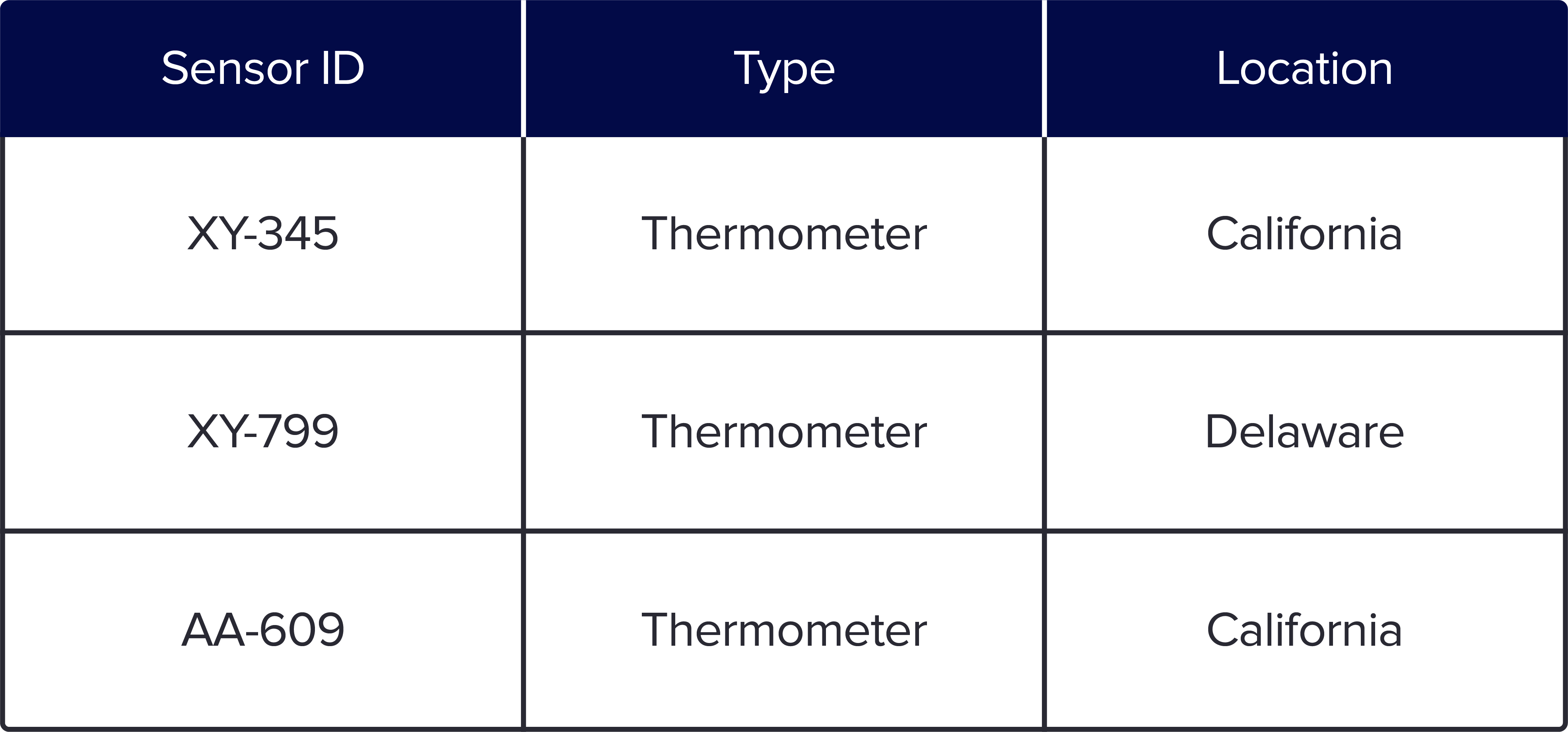
The row-based format is easy to understand since it is the typical format that we see in spreadsheets. However, for any type of large-scale querying, columnar formats have an advantage because you can query the subset of columns needed to answer a query. In addition, storage is more cost effective because row-based stores, like CSV, do not compress data as efficiently as Parquet.
InfluxDB and the Parquet file format
Here is an example that we will use to demonstrate how InfluxDB stores time series data in the Parquet file format.

The measurement maps to one or more Parquet files, and the tags, fields, and timestamps map to individual columns. These columns use different encoding schemes to get the best possible compression.
In addition, the data is organized in non-overlapping time ranges. Here we have 3 sample Parquet files for the same measurement but into 3 different time groupings.
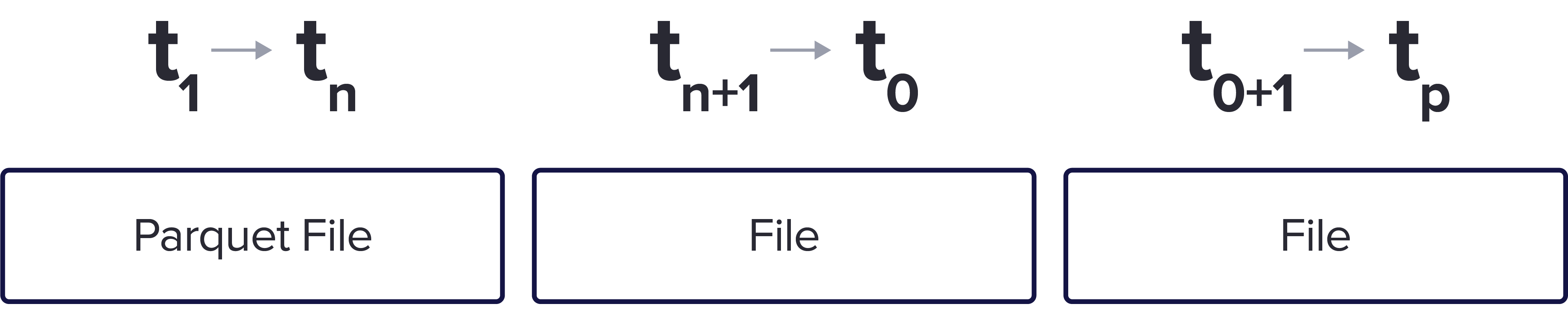
This executes a faster query since it allows the user to gather data for a specific time range. In addition, storing time series data in this way allows for easy eviction of data to save space, if required.
Parquet and Interoperability
The open source nature of Parquet and its wide adoption in other technologies and ecosystems means that Parquet users can utilize time series data stored in Parquet files in other applications. This allows users to extend the value and efficacy of time series data to areas and applications not previously possible.
Take charge of your operations and lower storage costs by 90%
Get Started for Free Run a Proof of ConceptNo credit card required.

Related resources

Free InfluxDB Training
Jump start your InfluxDB journey with free self-paced & instructor-led training.

